祝贺所有获奖者,非常感谢那些贡献高质量讨论和代码的人:@cdeotte, @siukeitin, @optimistix, @mikhailnaumov, @mahoganybuttstrings。即使我在这里忘了提到你,你们也知道你是谁。
我想特别感谢 @masayakawamata 和他的 优秀 TabM Notebook。它帮助了我的集成模型,但主要是因为我学会使用了一组新的神经网络,我怀疑它们在未来会很有用。
公共 LB 上的竞争非常激烈,私有 LB 也是如此。除了前 4 名“并列”在 0.05563 之外,接下来的约 200 名竞争者都在 0.05564。我们以前也有过接近的情况,但即使按 Kaggle 的标准来看,这似乎也极端了。
在我的学术日历中,10 月份有一段稍微开放的三周时间,所以这是我除暑假和寒假外在有意义地参与比赛的唯一机会。所以我做了,我的电脑可以证明这一点。从一开始在我看来,这场比赛在第一周左右之后就不会有多大进展了。天哪,我低估了它!别说“没有多大进展”,简直是毫无进展?在过去的 3 周里,我的 LB 分数一直相同,即使当我整理了大约一打得分为 0.05537 的提交时,内部分数只有微小的改善。由于其他 Kagglers 的分数大部分保持不变,很明显这种停滞不仅发生在我身上。
我尝试了很多事情, summarize 起来需要很长时间。相反,我将提及我认为最有区别的地方,尽管我不确定是否有区别,因为有 3 名 Kagglers 与我并列,另外 200 人仅落后 0.00001。
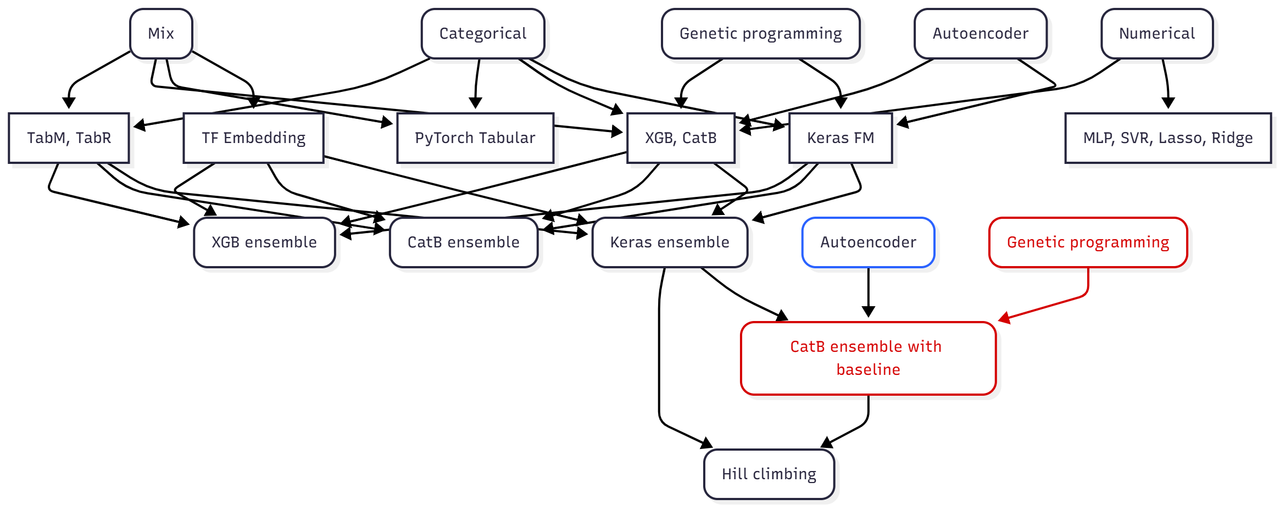
我本想制作一个有用的图表,但上面的结果似乎过于复杂。希望它能起作用。第一行是使用的各种数据类型。Mix 指的是既有分类特征又有数值特征的原始数据。有时它们都被转换为 Categorical 或 Numerical。大约 10 天后,我添加了通过 Autoencoder 生成的潜在空间表示和一些通过 遗传编程 (Genetic programming) derived 的特征。
纯数值表示不起作用,或者我应该说按 Kaggle 标准它不起作用。例如,我从 Lasso 获得了 0.058 的 CV 分数和 0.05802 的私有分数,这对于一个 10x10 重复 K-fold 运行只需约 2 分钟的方法来说客观上是非常优秀的。不仅如此,Lasso 特征系数在这场比赛中信息量极大。
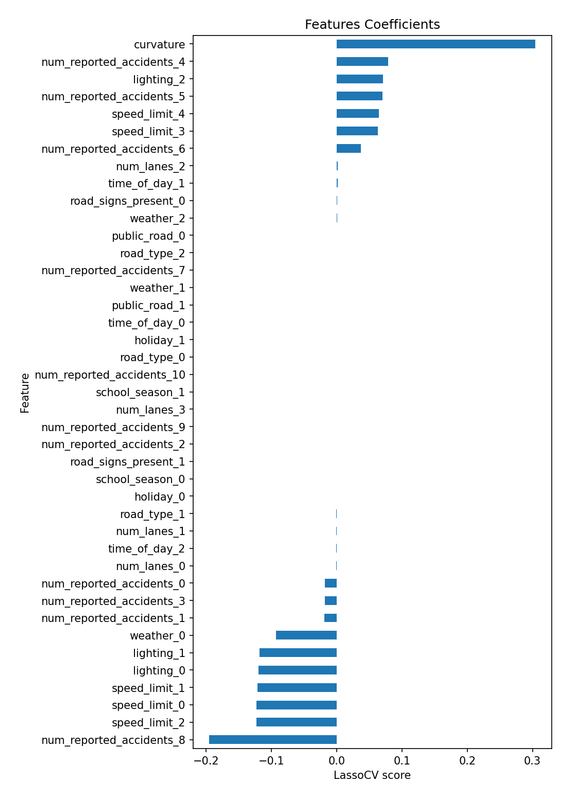
当你将图中的内容转化为数字(同时忽略绝对值 < 0.05 的系数)时,你会得到这个:
accident_risk =
0.3046 * curvature +
0.0706 * lighting_2 +
-0.1203 * lighting_0 +
-0.1181 * lighting_1 +
-0.0928 * weather_0 +
-0.1232 * speed_limit_0 +
-0.1232 * speed_limit_2 +
-0.1218 * speed_limit_1 +
0.0646 * speed_limit_4 +
0.0629 * speed_limit_3 +
0.0789 * num_reported_accidents_4 +
0.0704 * num_reported_accidents_5将其与用于创建目标的原始方程进行比较,我们有一个强大的 Lasso 模型,清楚地解释了特征贡献。
base_risk = (
0.3 * data["curvature"] +
0.2 * (data["lighting"] == "night").astype(int) +
0.1 * (data["weather"] != "clear").astype(int) +
0.2 * (data["speed_limit"] >= 60).astype(int) +
0.1 * (np.array(data["num_reported_accidents"]) > 2).astype(int)
)但足够了。如上图流程图所示,我尝试了许多不同的神经网络。开始接触 PyTorch Tabular,甚至学习了 rudimentary PyTorch 编程。按 Kaggle 标准,这些都没有“起作用”。这就是 TabM Notebook 如此有价值的地方,因为它提供了另一个可以与我的 Keras FM 和 TF 嵌入网络一起工作的模型。我太晚才将 @cdeotte 的 XGB 残差 boosting 添加到我的集成中,那时无论个别模型多么有希望,我的 CV 和 LB 分数都没有动静。最后,我微调了 TabM 参数,得到了三个比原始模型分数更好的模型,这些参数可以在 这个 Notebook 中找到。使用了三个参数集中的一个,另外两个被注释掉了。你可能想尝试所有三个,看看是否有助于你的集成。XGBoost 和 CatBoost 对我来说在这场比赛中相当标准,除了开始时几次运行外,没有使用 LightGBM。
我使用多种方法进行集成,因为这通常很容易,而且谁也不知道什么会起作用。也就是说,我更喜欢使用 NN 和 Lasso 进行回归,然后是爬山法以获得快速结果。这是因为所有这些方法通常不需要调整。你会从流程图中看到,我也使用了 XGB 和 CatB 进行集成,但那些是漫长的 Optuna 运行,找到最佳参数需要 4-10 小时。大约 2 周后,我 exclusively 使用 NN 进行集成,因为它比任何其他方法都有效,而且速度合理(40-50 个模型需要 1-2 小时)。
我运行了几次 AutoGluon,产生了许多有希望的模型,但它们都没有帮助集成。
既然我在数据部分没有谈到它,我应该在这里说,自动编码器 (AE) 和遗传编程 (GP) 都没有产生单独效果很好的特征。再说一次,这是一个相对评估,因为它们比 Lasso 效果好,但通常没有竞争力。将它们添加到个别模型中也没有太大帮助。
以下是我认为产生了一点差异的地方:在集成阶段添加 11 个 GP 衍生特征。我有一个 Notebook 在这里 展示了 GP 特征是如何 derived 的。由于它们是添加到原始数据中的,你可以简单地复制这些文件并在你的 pipeline 中尝试它们。这些特征很难通过查看公式来合理化:
train['GP_11'] = np.sqrt(np.abs(np.sin(np.sin(np.sin(np.sin(np.sin(np.sin(0.254397*train['speed']*np.sqrt(np.abs(train['lighting']*train['speed']*np.exp(train['curvature'])*np.sqrt(np.abs(train['lighting']**3*np.sin(train['speed']**2*train['accidents']*np.cos(train['weather']))/train['weather']))))))))))))然而,请注意,即使在这里,也只选择了相关特征进行计算。有趣的是,我做了几次 GP 运行,禁止所有花哨的代数和三角函数操作,只允许 [+, -, *, /] 操作。看看其中两次运行独立产生了什么。
0.308*[curvature] + 0.180*[speed_limit_3] + 0.180*[speed_limit_4] + 0.128*[num_reported_accidents_4] + 0.180*[lighting_2] + 0.107*[weather_1] + 0.118*[weather_2] - 0.00040.309*[curvature] + 0.186*[speed_limit_3] + 0.186*[speed_limit_4] + 0.0929*[num_reported_accidents_4] + 0.186*[lighting_2] + 0.099*[weather_1] + 0.0929*[weather_2] + 0.011人们可能会认为这些会是很好的额外特征,因为它们几乎完美地重现了原始目标方程,但事实并非如此。由于它们与好模型非常相似,并且单独对目标的 RMSE 约为 0.059,似乎它们在集成阶段并不是真正需要的。基本上,它们没有带来多样性。该 Notebook 中的其他 GP 特征在我的集成中通常更有用。具体来说,在个别模型之上添加 11 个 GP 特征导致集成改进了 0.00001。
最后的改进来自使用 CatBoost 作为二级集成器。CatB 能够在集成之前使用强大的“基线”模型作为种子,这本质上与 boosting 残差相同,只不过从目标中加减是自动为我们完成的。所以我首先运行一个没有 11 个 GP 特征的 Keras 集成,然后运行带有相同模型组 + 11 个 GP 特征的 CatB,并使用 Keras 集成模型作为基线。这使得公共和私有 LB 分数都提高了约 0.00002。我认为这就是最终产生差异的原因。
最后一步是采取几个一级集成模型,并通过爬山法制作二级集成。虽然,有人可能会争辩说它们已经是二级集成,因为我首先通过 Keras 运行它们,然后通过 CatB 运行。那个最终的爬山法集成(使用 4 个以前的集成模型)以最佳分数完成,是我的获胜解决方案,即使它在 5 位小数上看起来与最佳个别集成相同。事实上,我所有的前 12 个解决方案在 5 位小数上看起来都相同,所以我很高兴在其中我选择了第 2 和第 5 好的解决方案。