第3名解决方案 [更新 + 代码链接]
首先,我要感谢组织者举办了这场精彩的比赛,它提供了一个深入探索大语言模型(LLM)的绝佳机会。同时,感谢分享数据集和方法的Kaggle伙伴们。特别感谢@radek1和@cdeotte提供的高质量数据集,这些数据集在训练问答模型方面帮助巨大。感谢@simjeg展示了如何完成看似不可能的任务,感谢@cpmpml发展这些想法并提供了Xwin模型权重。特别感谢@sugupoko分享的7万条数据集,该数据集帮助我调整了重排序模型(这个数据集也对问答模型有贡献),从而极大地提升了我的分数。为了促进知识共享,我将公开我的代码,但还需要几天时间。
重要提示:在详细介绍解决方案之前,有一个需要说明的事项:我使用了Platypus2模型,但由于其许可证限制,我最初不确定是否允许使用。最终我决定保留在最终提交中,因为组织者声明获胜模型不会用于任何商业目的,这意味着许可证中的商业使用限制应该不成问题。
[更新] 事实证明使用Platypus2是符合要求的,但令人惊讶的是,后续的消融研究表明,不使用它反而能获得略高的分数!具体数据见下表。
解决方案流程图
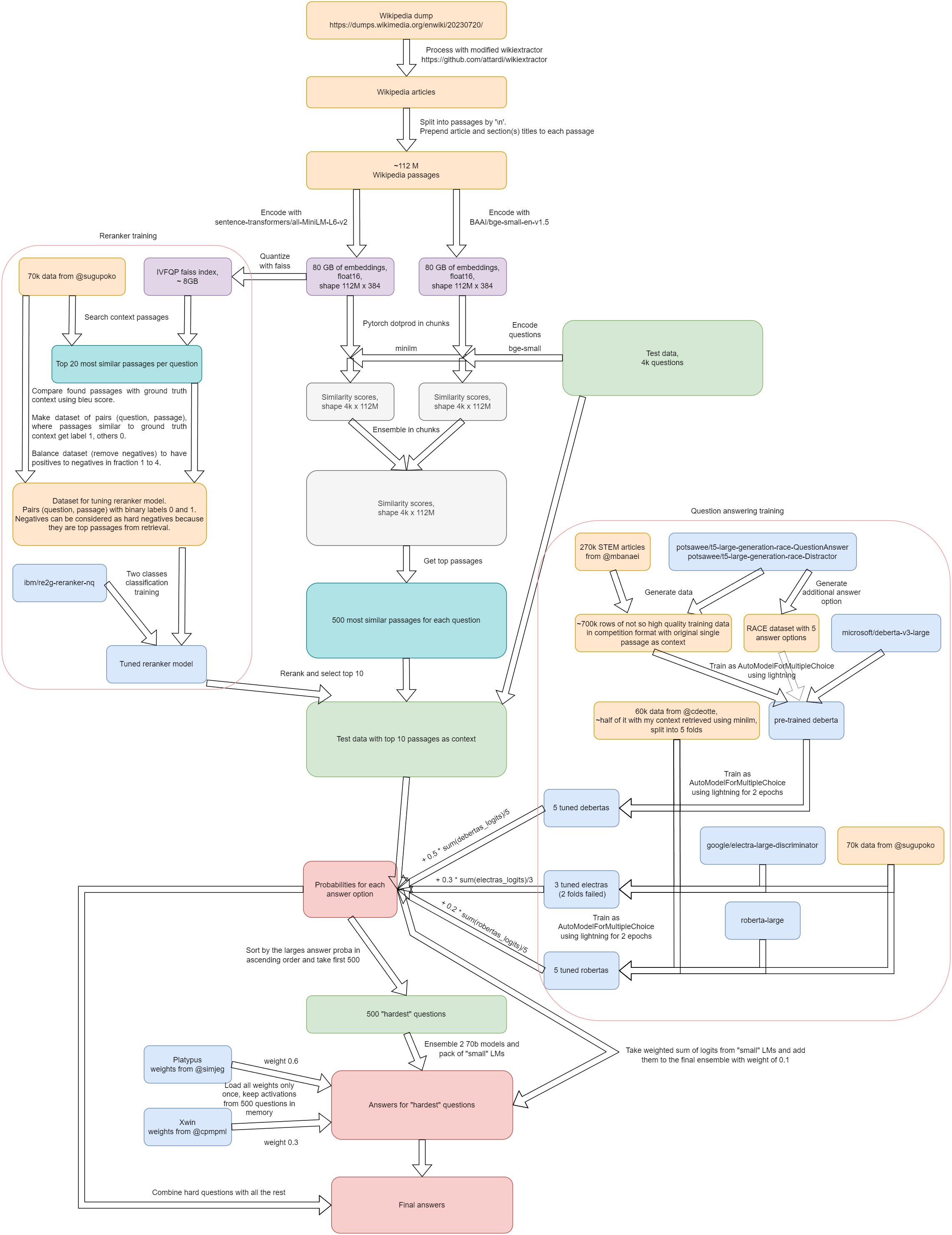
解决方案说明
维基百科数据处理
解决方案首先从维基百科数据转储的处理开始,因为正如许多人所指出的,现有已处理的维基百科数据存在许多缺陷,从缺失数字到缺失文章不等。我使用了https://github.com/attardi/wikiextractor工具,并对其进行了修改以解决数值被意外删除的问题。虽然可能仍存在一些问题,但部分关键问题已得到解决。
上下文搜索采用单阶段段落级搜索,而不是先搜索文章再搜索句子的两阶段方法。原因在于某些情况下,两阶段搜索根本无法找到必要的上下文。例如,在训练数据中我遇到一个关于某部戏剧角色行为的问题,但该戏剧文章的标题或开头并未提及该角色,因此文章编码中不包含必要信息。不确定这种情况的普遍程度,但很可能不可忽视。
重排序器训练
我注意到其他讨论中有人尝试训练重排序模型但未成功。根据我的调优经验,这里有两个关键要素:
- 使用与推理时同分布的(问题,候选)正负样本对。重要的是使用维基百科处理得到的段落,而不是原始7万数据集中的上下文。
- 使用困难负样本进行训练。但需要注意:未经重排序任务预训练的模型在困难负样本上表现极差。因此建议使用预训练模型(如我使用的ibm/re2g-reranker-nq)或采用两阶段训练策略。
消融实验
虽然各部分集成较晚未能进行完整消融实验,但早期提交结果仍能提供一些参考:
| 管道配置 | 私有分数 | 公有分数 |
|---|---|---|
| 仅使用5个Deberta模型推理(非最终版),未调优重排序器 | 0.894 | 0.893 |
| + 使用Platypus回答500个难题 | 0.91 | 0.909 |
| + 更新Deberta模型并添加3个Electra和5个Roberta | 0.912 | 0.914 |
| + 使用调优后的重排序器 | 0.927 | 0.922 |
| + 添加Xwin到集成 | 0.928 | 0.926 |
这些结果表明,当提供正确上下文时,问答部分表现优异(重排序器调优带来的提升证明了这一点),而整个解决方案中最薄弱的环节是初始检索部分。这很合理,因为该部分未针对比赛数据进行专门优化,且使用两个容量非常小的模型来索引海量数据集。如果采用经过调优的检索模型,很可能获得更高的分数。
[更新] 各组件对最终分数贡献的详细测量数据:
| 管道配置 | 私有分数 | 公有分数 |
|---|---|---|
| 最终提交版本 | 0.9284 | 0.9286 |
| 不含Xwin | 0.9272 | 0.9257 |
| 不含Platypus2 | 0.9288 | 0.9309 |
| 不含两个大语言模型 | 0.9165 | 0.9201 |
| 检索中不含bge-small | 0.9272 | 0.9261 |
| 检索中不含MiniLM-L6-v2 | 0.9258 | 0.9259 |
| MLM集成中不含Electra和Roberta | 0.9246 | 0.9268 |
| 不含重排序器 | 0.9113 | 0.9130 |