[第五名解决方案] 使用Vanilla Transformer、Data2vec预训练、CutMix和知识蒸馏
感谢Kaggle和竞赛主办方举办这场令人难以置信的竞赛。以下是我的解决方案。
代码可在 GitHub仓库 获取。
简要总结
- 使用手部、姿态和嘴唇的3D坐标点进行强数据增强
- 带卷积stem和RoPE的Vanilla Transformer
- Data2vec 2.0预训练
- CTC分割和CutMix
- 知识蒸馏
数据处理
我使用3D坐标点而非2D坐标,因为在3D空间应用旋转增强能使模型更鲁棒。根据MediaPipe文档,z轴的尺度与x轴大致相同。由于x和y根据相机画布宽高归一化,且数据来自智能手机设备,我需要用原始纵横比进行反归一化以应用正确的旋转变换。我通过求解仿射矩阵来估计纵横比,该矩阵将每帧归一化的手部关键点映射到标准手部关键点,并从仿射矩阵获取缩放因子。平均纵横比为 0.5268970670149133,我将归一化的y值乘以 1.8979039030629028,即 points *= np.array([1, 1.8979039030629028, 1])。
正确的旋转变换:
$$X' = SRX$$
错误的旋转变换:
$$X' = RSX$$
注意:在归一化坐标后应用旋转是错误的。应先反归一化,旋转,再归一化。实际上,我不再归一化,因为这并非必要。
我使用了左手、右手、姿态和嘴唇的关键点。最初几周我只关注手部关键点,达到0.757的公开LB分数。我认为拼写完全与手势相关。令人惊讶的是,加入姿态和嘴唇等辅助关键点提升了性能并缓解过拟合。额外的输入点有助于提升泛化能力。
以下是数据增强代码片段:
Sequential(
LandmarkGroups(Normalize(), lengths=(21, 14, 40)),
TimeFlip(p=0.5),
RandomResample(limit=0.5, p=0.5),
Truncate(max_length),
AlignCTCLabel(),
LandmarkGroups(
transforms=(
FrameBlockMask(ratio=0.8, block_size=3, p=0.1),
FrameBlockMask(ratio=0.1, block_size=3, p=0.25),
FrameBlockMask(ratio=0.1, block_size=3, p=0.25),
),
lengths=(21, 14, 40),
),
FrameNoise(ratio=0.1, noise_stdev=0.3, p=0.25),
FeatureMask(ratio=0.1, p=0.1),
LandmarkGroups(
Sequential(
HorizontalFlip(p=0.5),
RandomInterpolatedRotation(0.2, np.pi / 4, p=0.5),
RandomShear(limit=0.2),
RandomScale(limit=0.2),
RandomShift(stdev=0.1),
),
lengths=(21, 14, 40),
),
Pad(max_length),
)总输入点数为75个。每个组件分别有21、21、14和40个点。具有更多NaN值的手会被丢弃,只保留主导手。如上所示,空间变换分别应用于各组件。关键点组首先按各组最大xy值进行中心化和归一化。注意z值可能超过1。
模型架构
我使用了类似ViT的简单Transformer编码器模型。采用PreLN和旋转位置编码。将ViT的线性patch投影stem替换为单层卷积,使模型能从第一卷积层捕获相对位置差异(如运动向量)。使用旋转编码后无长度限制,推理时也不截断序列。类似其他ViT变体,我还集成LayerDrop缓解过拟合。
Data2vec 2.0预训练
由于输入是3D点且使用低归纳偏置的标准Transformer,我认为需要预训练模型学习数据属性。Data2vec 2.0方法在各领域表现卓越且高效,很适合适应关键点数据集。
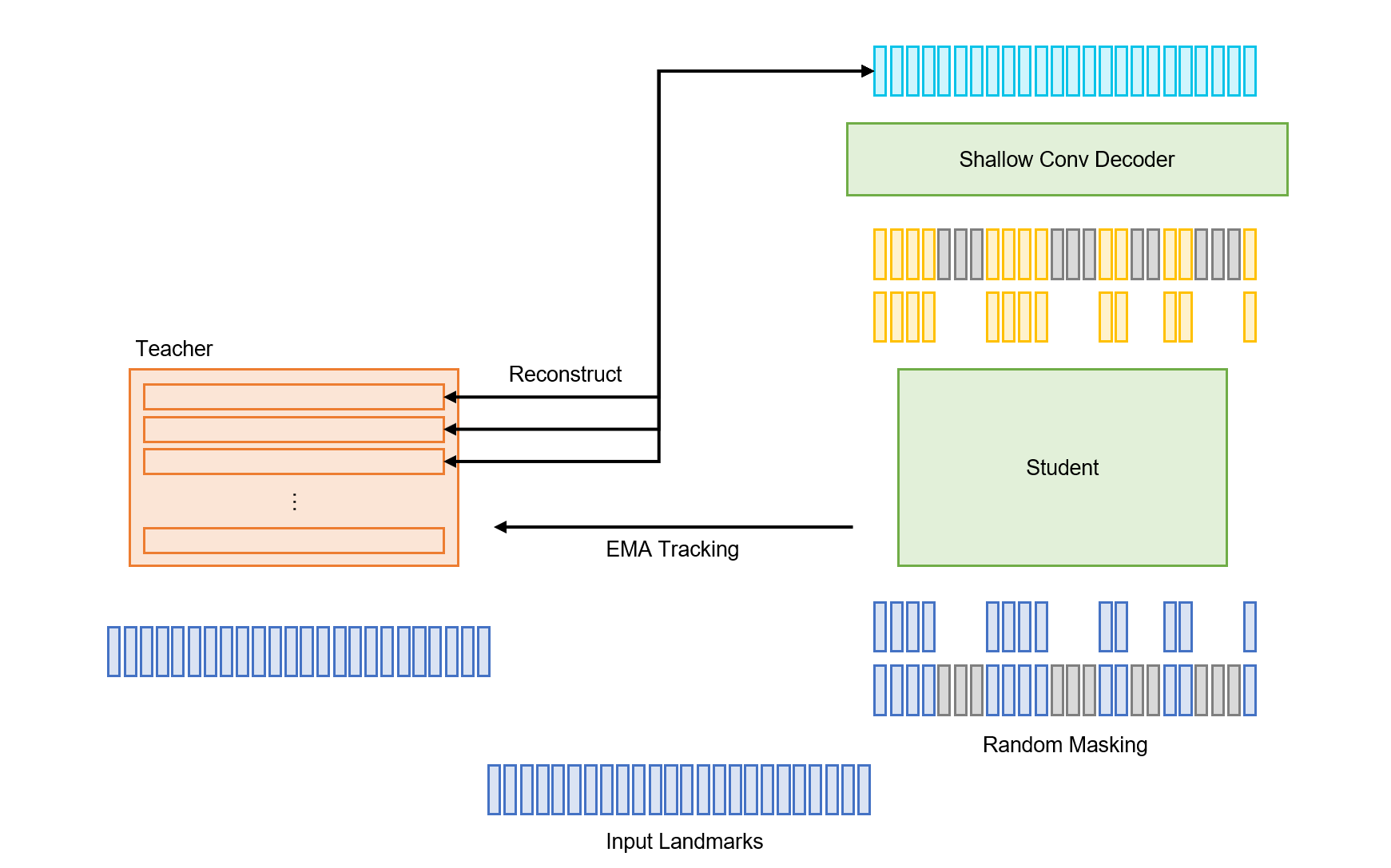
根据论文,同一批次内使用多种不同掩码有助于收敛和效率。我设置 $M = 8$ 和 $R = 0.5$,意味着50%输入序列被掩码且有8种不同掩码模式。经过大量实验,最终模型为:
- Transformer Large (24层 1024维): 109个epoch (872有效epoch)
- Transformer Small (24层 256维): 437个epoch (3496有效epoch)
训练终止由训练步数而非epoch数决定,导致epoch数不是10的倍数。预训练后,使用学生参数进行微调。
CTC分割与CutMix
在解释微调前,必须讨论CTC分割和CutMix增强。参考 此仓库 和 此文档。简言之,CTC训练模型可检测字符出现位置,推断短语与关键点视频的时间对齐。
我先训练Transformer Large模型并创建伪对齐标签。利用对齐结果应用时序CutMix增强——从原序列截取随机部分,在截断点插入另一随机序列部分。该技术显著减少过拟合,性能提升约+0.02。随后用CutMix和伪对齐标签像Noisy Student一样重新训练Transformer Large模型,在CV集上获得更好性能。
我还观察到,补充数据集在没有CutMix时会降低性能,但与CutMix结合时带来显著提升,CV和LB均提高约+0.01。
微调与知识蒸馏
微调采用标准方法,仅使用上述增强的CTC损失。受40MB和5小时限制,Transformer Large模型过大。我探索多种组合和参数规模,最终选用Transformer Small (24层 256维)。为将Large模型压缩到Small模型,采用类似DeiT的知识蒸馏,预测教师模型的硬标签。我发现共享KD和CTC的头部会损害性能,因此使用独立头部。我还尝试RNN类头部(特别是堆叠BiLSTM),但无性能提升。模型收敛快,但最终性能不变。
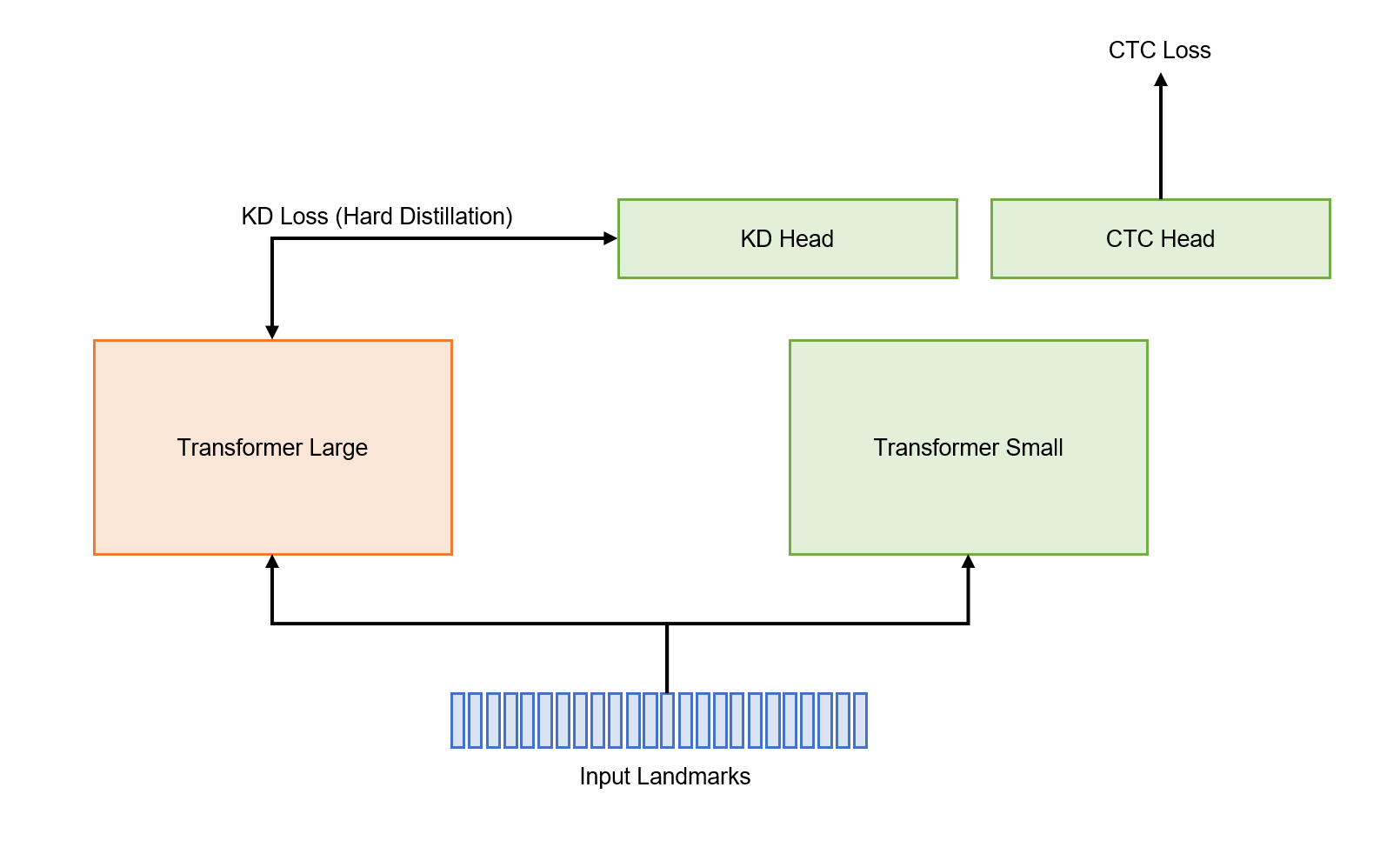
训练epoch数如下:
- Transformer Large (24层 1024维): 65个epoch
- Transformer Small (24层 256维): 830个epoch
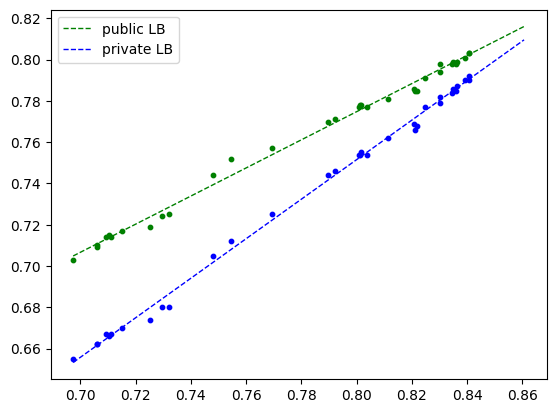
CV与LB
与许多人使用的GroupKFold验证策略不同,我仅将训练集5%作为验证集:
train_test_split(train_labels, test_size=0.05, random_state=42)最初我基于参与者ID使用GroupKFold,但发现交叉验证与公开LB分数不一致。上述方法使CV和公开LB性能保持一致提升。
无效策略与未来工作
- 使用外部数据集无效。竞赛数据集已相当大,很难找到同等规模的拼写数据集。
- 尽管前缀束搜索在较小束宽下提升+0.002,但tflite版本实现太慢,最终未采用。
- 尝试多种头部架构,但单层线性层已足够。
- Conformer和transformer编解码器模型未优于vanilla transformer。
- 尝试RandAugment和TrivialAugment,但手工设计的强增强效果更好。