第9名解决方案
感谢主办方,也祝贺所有的获奖者!
概述
参考Sartorius竞赛的前两名解决方案,我在竞赛早期决定采用目标检测和语义分割的两阶段流水线,而非使用Mask-RCNN等单阶段模型。我认为两阶段流水线的主要优势在于易于集成和进行测试时增强(TTA)。
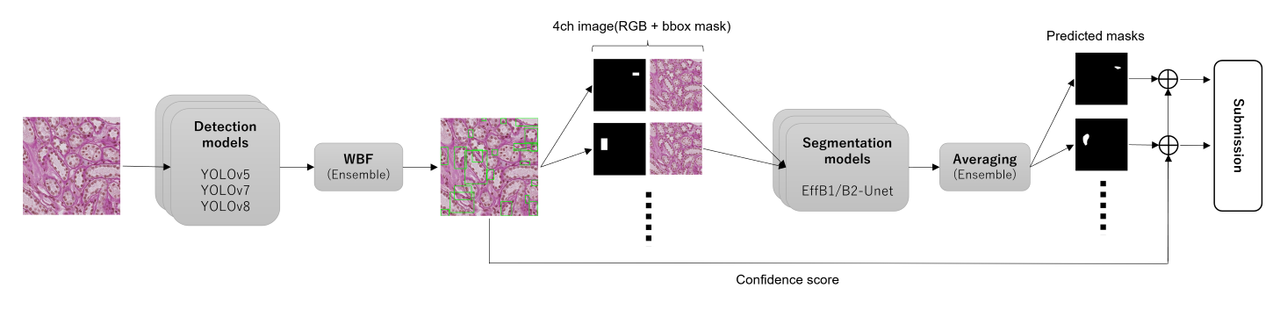
检测部分
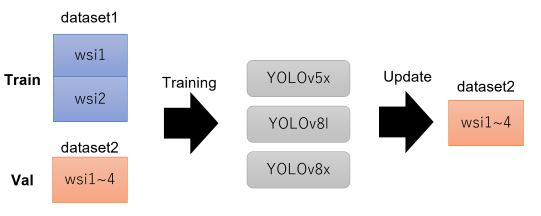
dataset2边界框级标注的更新
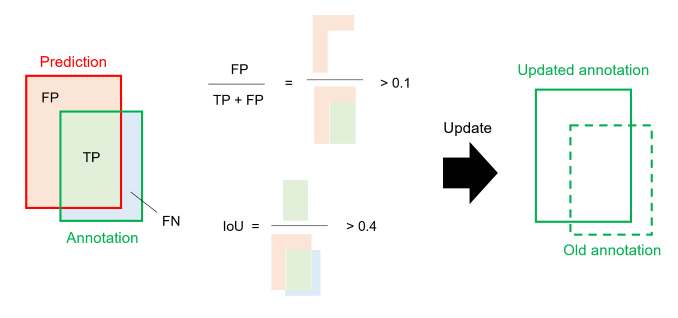
正如讨论中提到的,在同时使用dataset1和dataset2训练的模型中,膨胀操作显著提高了LB分数。然而仅使用dataset1训练的模型并未显示出这种效果。这让我相信dataset2的标注比dataset1的标注更小。考虑到存在多种类型的血管,并且它们的标注可能并非均匀偏小,我采取了使用仅从dataset1训练的模型来更新dataset2的边界框级标注的方法。
更新是通过替换原始标注为满足以下条件的预测结果来完成的。基本上,更新后的边界框比原始的要大,且dataset2中边界框的总数不会因更新而改变。
- IoU > 0.4
- FP / (TP + FP) > 0.1
在使用更新后的dataset2与dataset1一起训练的模型中,膨胀带来的LB提升几乎消失,且在没有膨胀的情况下就实现了0.5以上的LB分数。
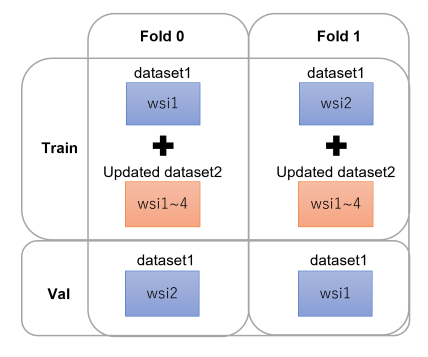
交叉验证策略
采用以下特殊的二折划分方式进行交叉验证。
模型训练
我训练了2类别(血管、肾小球)的检测模型,忽略"unsure"标签。我修改了YOLOv5/v7/v8的源代码,添加了90度随机旋转增强。最终提交使用了以下5种模型×2折(共10个模型)。
| 模型 | 输入尺寸 |
|---|---|
| YOLOv5x6 | 512 |
| YOLOv7x | 512 |
| YOLOv8l | 512 |
| YOLOv8x | 512 |
| YOLOv8l | 768 |
推理过程
由于我认为检测的准确性比分割更重要,且测试图像数量较少,因此我进行了10个模型×16种TTA的大规模集成。10×16=160个检测结果通过WBF合并。
- 16种TTA:8种来自h-flip、v-flip、90度旋转的组合,2种来自2种尺度(基础尺寸,基础尺寸+64px),8×2=16
- 每个模型NMS的IoU阈值:0.6
- WBF的IoU阈值:0.7
分割部分
交叉验证策略
与检测模型基本相同,只是dataset2不进行更新。
模型训练
作为边界框的掩码,我没有使用检测模型的预测结果,而是使用从原始标注中获得的边界框。与检测模型不同,"unsure"标签也被用于训练。最终提交使用了EfficientNetB1-Unet和EfficientNetB2-Unet(各2折,共4个模型)。
推理过程
由于运行时间限制,未使用TTA。二值化使用的分数阈值为0.5。
最终提交策略
通过更新dataset2获得的效果较小,但微小的膨胀略微提高了LB分数。我没有使用cv2.dilate对最终掩码进行膨胀,而是通过百分比增加边界框的尺寸。在我的最终提交中,3%的边界框膨胀使我的LB分数提高了约0.005。我在两个最终提交中的一个使用了3%的膨胀,另一个没有(除膨胀外还有其他差异)。
| 提交版本 | Public LB | Private LB |
|---|---|---|
| 使用3%膨胀 | 0.580 | 0.549 |
| 不使用3%膨胀 | 0.572 | 0.560 |
尝试但未成功的方法
- 在dataset3上的半监督学习