第30名解决方案
概述
@ayberkmir 和我参赛时间很晚。我浪费了第一周时间,因为没有正确理解评估指标,也没有据此调整提交策略。我们没时间去尝试太多不同的方法,所以这个方案相对简单。
验证策略
Ayberk采用了分层单次训练/测试分割(按血管数量分层),而我使用了4折留一WSI交叉验证。令人惊讶的是,这两种方法在私有排行榜上都表现良好。
模型选择
我主要负责基于ResNeXt101骨干网络的Mask R-CNN和Cascade Mask R-CNN模型,Ayberk则专注于YOLOv7和v8模型。
训练过程
我在构建数据集时,通过抑制重叠度超过0.99 IoU的边界框来去除重复标注。我还加入了肾小球标注,并将不确定标注视为血管处理,认为这样能让训练更稳定。Ayberk未使用肾小球或不确定标注,而YOLO本身已能处理重复标注问题。
由于全切片图像(WSIs)较为相似,我决定不使用染色增强。采用了多尺度训练,尺度范围在原始尺度的1.5倍到2倍之间:
train_scales = [
(, ), (, ), (, ),
(, ), (, ), (, ),
(, ), (, ), (, )
]其他训练增强包括随机水平、垂直和对角线翻转,以及随机亮度、对比度、色调和饱和度调整。
Ayberk采用固定的1024x1024输入尺寸,因为我们认为YOLO内置的增强策略已足够强大。
我们基本使用优化器和调度器的默认参数,我只额外添加了一个学习率乘数步骤。
后处理
我们都认为后处理是本竞赛最重要的环节,因为评估指标较为特殊。我们将大部分时间都投入在后处理而非建模上。
首先,我们在模型预测时使用了3倍测试时增强(TTA:水平、垂直和对角线翻转)。TTA预测结果通过加权框融合(WBF)进行合并,融合后框对应的掩码取平均值。遗憾的是,我无法在mmdetection中获取软掩码预测,只能对二值掩码进行平均。我们没有使用多尺度TTA。YOLO模型输入尺寸为1024x1024,Mask R-CNN模型为1280x1280。
由于我使用了4折交叉验证,还需合并各折的预测结果,同样采用加权框融合。我们还尝试在此阶段融合YOLO和Mask R-CNN的预测结果,在公共排行榜上效果与其他方法相当,但在私有排行榜上始终表现不佳。
我们对比了使用和不使用膨胀操作的提交结果,发现TTA在公共排行榜上大幅降低了膨胀的效果。这很有价值,因为TTA更安全而膨胀操作风险较高。
我们尝试了多种组合的提交:模型、折数、TTA、膨胀、分数乘法、WBF调优等。
按公共分数排序时,高分提交多使用膨胀或集成方法:
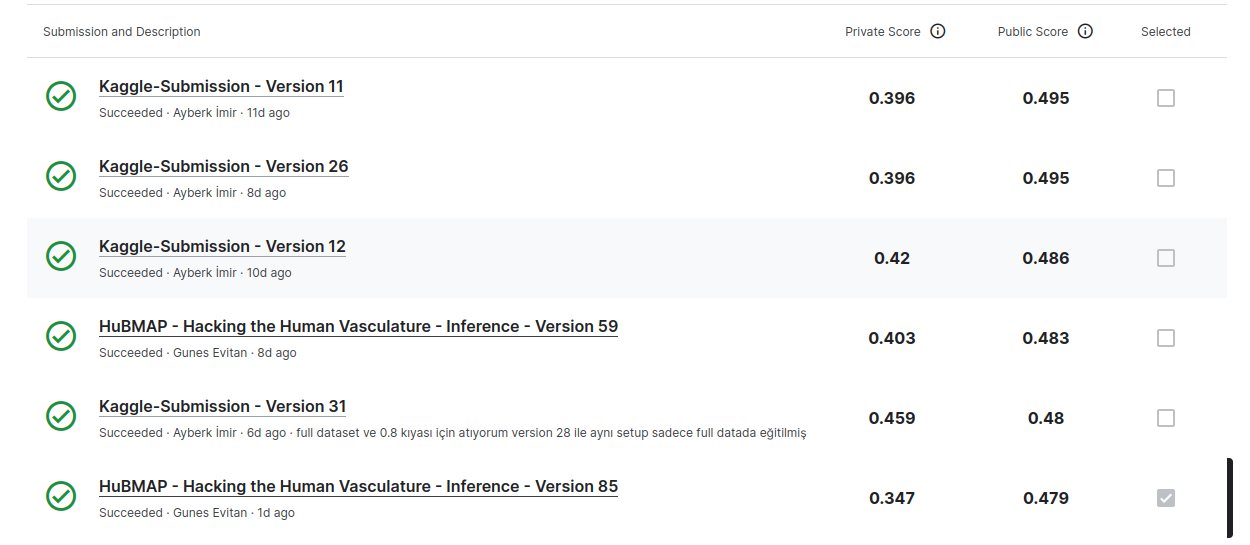
按私有分数排序时,高分提交多采用TTA、无膨胀且为单一模型,但有一份使用膨胀的提交在私有榜得分0.50x,这很奇怪:
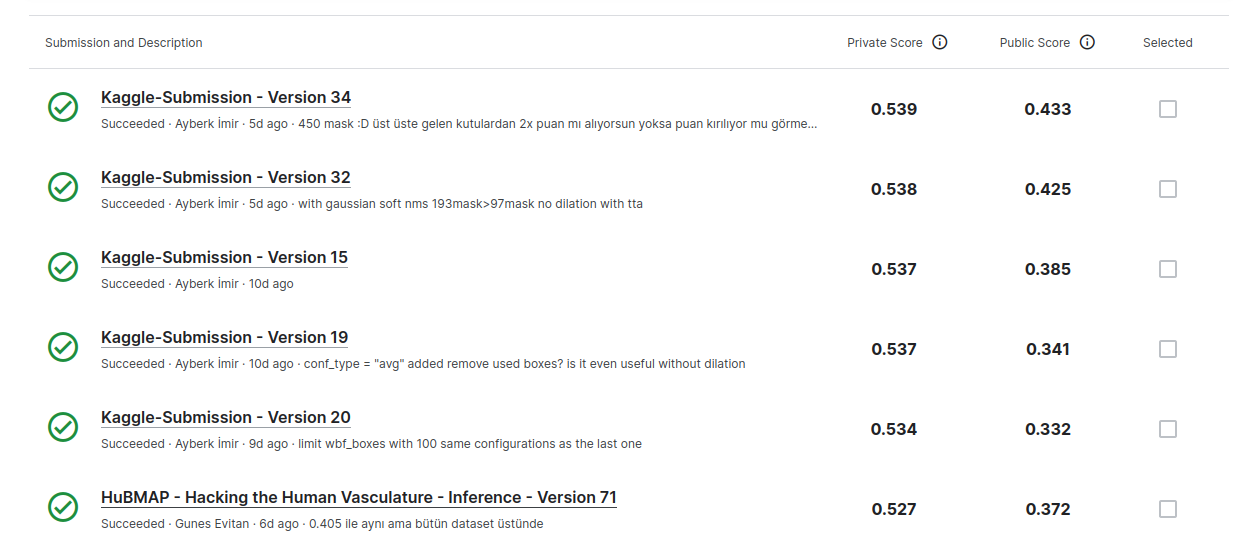
我们最佳提交在私有排行榜上位列第14名,但最终Ayberk选择了一个足够好的提交方案,使我们获得第30名。