使用TensorFlow GRU预测乘数 - 第三名解决方案
感谢Kaggle和GoDaddy举办的这场激动人心的预测竞赛!
使用TensorFlow GRU预测乘数
我们的预测模型需要为每个县预测未来月份的小微企业密度。公共排行榜仅包含1个月后的预测,而私人排行榜包含3个月后的预测(训练集与测试集之间有2个月的间隔)。
从Kaggle的M5竞赛经验中我们了解到,预测乘数(测试期与训练期之间的比率)至关重要。例如在M5竞赛中,只需将公开笔记本的预测结果乘以0.95就能获得金牌!同样在GoDaddy竞赛中,如Vitaly的笔记本所示,将最后一个值基线乘以正确的1月/12月乘数1.0045,在多个月份都达到了公共排行榜的金牌成绩!
为了预测乘数,我们将训练数据转换为乘数,然后训练TensorFlow GRU模型。这个简单模型可获得第15名金牌成绩。如果再根据排行榜探测学习到的比率对乘数进行后处理,我们的解决方案能提升至第3名金牌!!
原始训练数据
Kaggle为我们提供了美国3135个县共41个月的历史数据。
步骤1 - 调整训练数据
小微企业密度的定义是"每100名18岁以上人口拥有的小微企业数量"。当县人口发生变化时,小微企业密度的值也会变化。因此第一步是将所有小微企业密度转换为使用相同的2021年人口普查数据。我们使用以下公式:
adjusted_microbusiness_density = microbusiness_density * (population / population_year_2021)步骤2 - 创建56,000个时间序列!
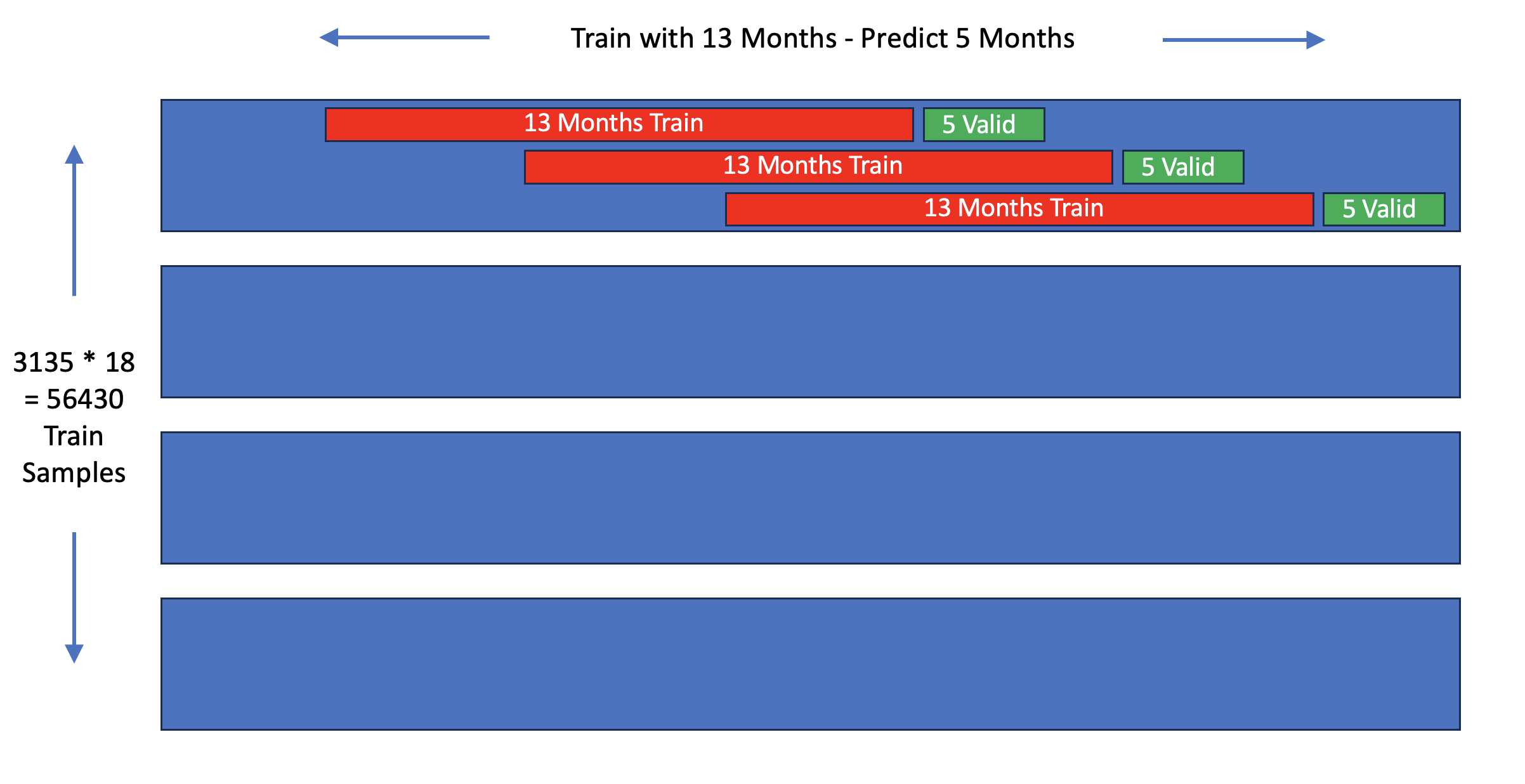
对每个县,我们创建18个时间序列。我们使用13个连续月份训练GRU,并预测接下来的5个月。(下图仅显示每个县3个时间序列作为示意)。之后,我们就有56,000个时间序列用于训练!
步骤3 - 仅使用最大的90%的县
我们注意到最小的10%的县,其小微企业密度几乎逐月相同,因此我们只使用最大的90%的县训练GRU。在推理时,对小的县我们直接使用最近已知值作为预测。
步骤4 - 转换为乘数
每个县有13个月的训练数据和5个月的验证数据。我们将原始小微企业数据转换为比率,用当前月除以上一月的比率替换每个值。之后我们得到12个月的训练比率和5个月的验证比率:
# 转换为比率
for k in range(17):
new_data[:,k+1] = old_data[:,k+1] / old_data[:,k]步骤5 - 使用GroupKFold训练GRU
创建KFold时需要使用GroupKFold,确保每个县的所有时间序列(每个县可能有18个)都在同一个折叠中。否则CV分数将不准确,无法正确优化模型超参数。以下是我们的TensorFlow GRU模型,输入12个比率并预测5个比率:
def build_model():
inp = tf.keras.Input(shape=(12,1)) # 输入形状为12
x = tf.keras.layers.GRU(units=8, return_sequences=True)(inp)
x = tf.keras.layers.GRU(units=8, return_sequences=True)(x)
x = tf.keras.layers.GRU(units=8, return_sequences=False)(x)
x = tf.keras.layers.Dense(5,activation='linear')(x) # 输出形状为5
model = tf.keras.Model(inputs=inp, outputs=x)
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
loss = tf.keras.losses.MeanSquaredError()
model.compile(loss=loss, optimizer = opt)
return model步骤6 - 推理与后处理
我们逐个预测每个县。要预测2023年1月,我们从2022年12月的最近已知值开始,乘以模型预测的第一个比率。预测2023年2月时,取1月预测值乘以模型预测的第二个比率。预测3月时乘以第三个比率,4月乘以第四个比率,5月乘以第五个比率。
我们可以通过排行榜探测信息改进预测,修改第一个比率(即2023年1月除以2022年12月的比率)。探测告诉我们,最大的90%县的1月/12月最佳平均比率为1.0045。同样,我们可以通过探测公共排行榜为小县找到不同规模的比率。
后处理将我们的GRU解决方案从第12名金牌提升到第3名金牌!!
GRU解决方案代码已发布
包含预处理、训练和推理的完整解决方案代码已发布于此。
更多解决方案模型
我的最后两个提交是:
- GRU with PP - 第3名
- Linear Model with PP - 第10名
关于线性模型的更多信息请见此处。祝你好运!