额外加分
我们在 CVPR 2023 上展示了我们的解决方案。在 YouTube 上观看 这里
引言
我们团队想深切感谢 Kaggle 工作人员、Google Research 和 Haiper 举办了这场激动人心的图像匹配挑战赛 continuation,也感谢所有参赛并分享精彩讨论的选手。祝贺所有参与者!
我们在这里描述的工作 truly 是 @yamsam、@remekkinas 和 @vostankovich 的共同努力成果。我很荣幸能成为这个勤奋、团结且技术精湛的团队一员。非常感谢大家!我从你们身上学到了很多。
我们很享受这场比赛!
用于最终私人排行榜评分的最佳提交在比赛的最后一天完成。我们对此提交并非完全确定,因为不清楚其中存在多少随机性。我们有多次重新运行相同 notebook 代码来观察可以获得多少分数的习惯。我们讨论了在最后一天实现的解决方案,相信它,结果证明是可行的。另一个有趣的事实是,我们为最终评估选择的第二提交获得了 0.497/0.542 的分数,这也使我们获得了第二名。这个第二选定的提交与第一份完全相同,只是没有使用下面描述的"多次运行重建"技巧。无论如何,最佳提交 (0.562) 与第二份之间的差异是显著的。
概述
总的来说,在我们的所有代码提交中,我们不断与 COLMAP 负责场景重建的随机性作斗争。我们的最终解决方案基于使用 COLMAP 和预训练的 SuperPoint/SuperGlue 模型,对场景中每张图像以不同分辨率运行。我们应用了许多针对不同 COLMAP 流程部分的技巧,以稳定我们的解决方案并达到最终分数。
架构
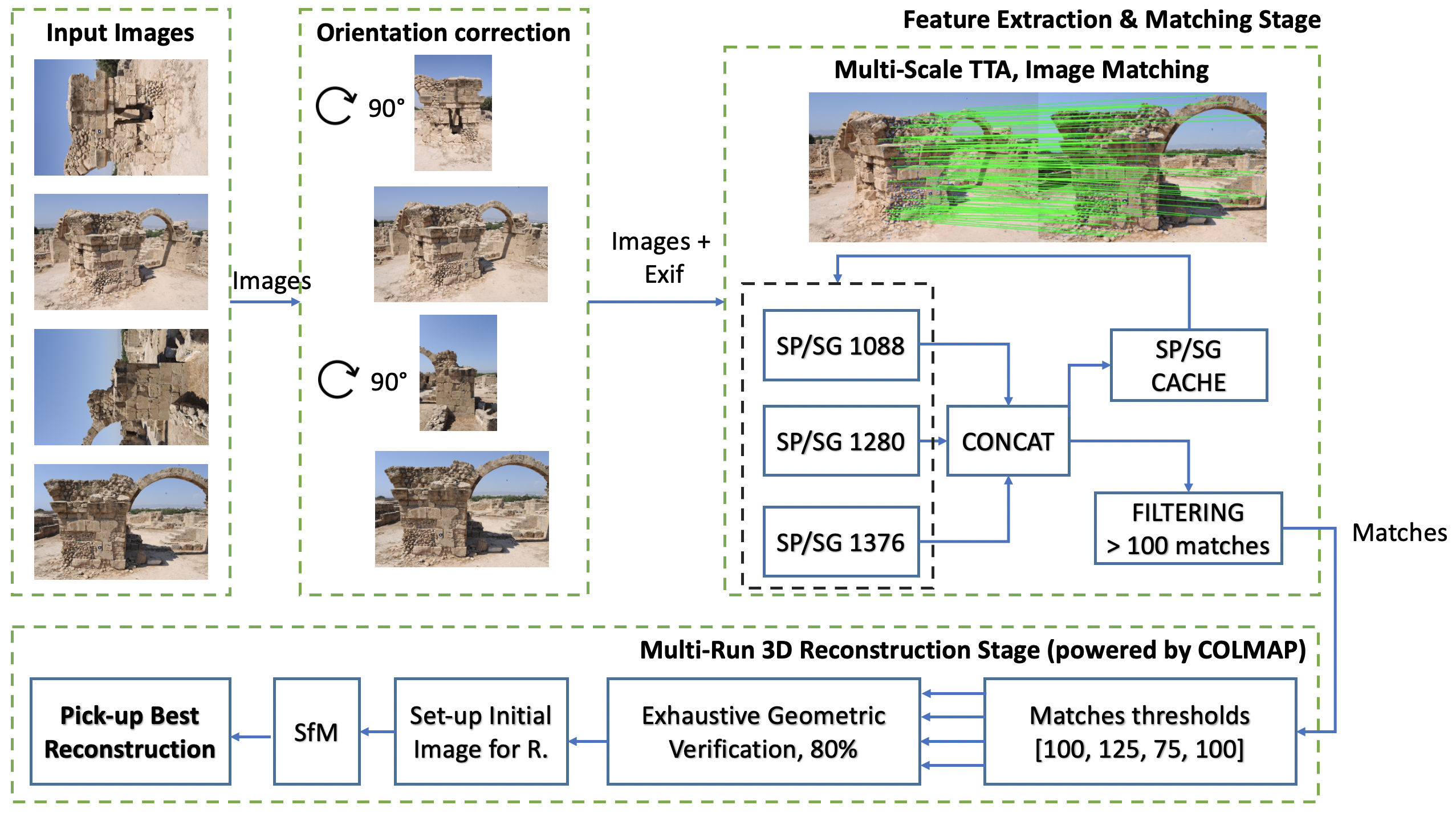
关键要点:
- 最初,使用场景集中生成的所有可能的唯一图像对。移除用于查找和排序场景中相似图像的模型和逻辑。100 的阈值定义了我们期望每对图像具有的最少匹配数。如果少于该数量,则丢弃该对。
- SP/SG 设置:不限关键点数,关键点阈值为 0.005,匹配阈值为 0.2,sinkhorn 迭代次数为 20。
- SP/SG 的半精度有助于减少内存占用,而不会明显牺牲精度。另一个显著的性能优化技巧是缓存 SP 为每张图像生成的关键点/描述符,然后缓存每对图像的 SG 匹配。这大大减少了运行时间。
- TTA:从不同尺度图像中提取的匹配集成。在我们的本地实验中,使用 [1088, 1280, 1376] 组合获得最佳结果。我们使用 np.concatenate 连接来自不同模型的匹配,这在上一届 IMC22 比赛中很常见。
- 应用旋转检测器在必要时对场景中的图像进行去旋转。我们发现训练数据集中的某些场景(cyprus、dioscuri)有许多 90/270 度旋转的图像。部分图像具有 EXIF 元信息。不幸的是,查看训练数据集后,我们未找到关于图像拍摄方向的具体信息。为解决此旋转问题,我们通过采用此解决方案重新旋转图像到其自然方向。我们不加阈值直接使用,并查看需要对图像应用多少次旋转。应用旋转后,cyprus 场景的得分从 ~0.02 显著提升至 ~0.55。RotNet 实现对我们无效。
- 显式设置 COLMAP 重建的初始图像。对于每张图像,我们存储其在多少对图像中出现以及这些对产生的匹配数。然后我们选择具有最多对数的图像。如果多张图像满足此标准,则选择匹配数最多的那张。这有助于提升得分。
- 为减少分数中的随机性,我们决定进行类似多次 match_exhaustive 调用平均的操作。思路是对原始匹配数据库运行 N 次 match_exhaustive。然后我们只保留在 8/10 情况下出现的匹配,其余匹配被忽略。这是通过粗暴的数据库复制写入/读取等方式实现的。
- 多次从头开始重建,使用不同的匹配器阈值,例如 [100, 125, 75, 100]。通过查看注册图像数量和 3D 点云数量,我们选择最佳重建。此技巧不仅有助于通过找到更优的匹配阈值来获得更好的重建,还能减少随机性影响,并作为防止分数大幅波动的对策。由于其时间复杂度,我们仅对包含少于 40-45 张图像的场景使用此策略。这是我们解决方案中的最后一步,帮助我们将分数从 0.497/0.542 提升至 0.506/0.562。我们还尝试了使用 pycolmap.incremental_mapping 的类似方法,但该方案未成功。
未成功或未充分测试的想法:
• 多裁剪 TTA,未成功。想法是将图像分割成多个裁剪,提取匹配以在场景中找到相似图像并确定最佳图像对。
• 方形尺寸图像
• 更大的图像尺寸(例如 1600)用于 SP/SG
• 使用手动 RANSAC 替代 COLMAP 内部实现。我们尝试禁用几何验证的实验,但得分不佳。
• 使用ANMS的NMS 过滤来减少点数
• 根据离群值数量而非原始匹配数过滤最不重要的图像对。寻找图像对的特定匹配数非常重要。使用 SP/SG 和 Loftr 进行了实验。使用 Loftr 获得了更高的 mAA,但可能需要更多努力使其正常工作,时间不足。
• 将场景图像下采样后再传递给 COLMAP
• 像素完美运动恢复结构。这是一个值得评估的有前途方法,因为我们在本地使用PixSfm获得了不错的提升,使用 1280 的单图像尺寸,分数从 0.71727 提升至 0.76253。之后,我们成功安装此框架并在 Kaggle 环境中运行,但无法击败我们当时的最佳分数。这是一个占用过多内存的 heavyweight 框架,我们只能对最多约 30 张图像的场景运行。有点沮丧,因为我们花了大量时间编译所有这些内容。
• 自适应图像尺寸。例如,如果场景中大多数图像的最长边 >= 1536,我们使用更高的图像分辨率进行匹配器集成,例如 [1280, 1408, 1536]。否则,应用默认设置 [1280,1088,1376]。没有足够时间测试此想法。它在本地对具有大分辨率的 cyprus 和 wall 有效。实现此想法的最后一份提交之一因内部错误崩溃。
• 不同的检测器、匹配器。我们测试了 Loftr、QuadreeAttention、AspanFormer、DKM v3、GlueStick(关键点+线条)、Patch2Pix、KeyNetAffNetHardNet、DISK、PatchNetVLAD。我们还尝试了置信度匹配阈值和匹配数,但无提升。最终,SP/SG 是我们最佳选择。可能许多基于密集的方法对我们无效的原因是"重复性"度量性能低且匹配中噪声高。
• 不同的CNN 来查找场景中最相似的图像并生成相应的图像对(NetVLAD、不同的预训练 timm 骨干网络、CosPlace 等)。我们甚至专门训练了模型来查找场景中的相似图像,但未成功。之后,我们完全放弃了此策略。
• 不同的关键点/匹配细化方法(例如,最近发布的AdaMatcher、Patch2Pix),但没有足够时间。AdaMatcher 似乎是一个值得尝试的想法,其论文引用"作为 SP/SG 的细化网络,我们观察到 AUC 的显著改善"
性能改进步骤
| 方法 | 私人排行榜 | 公共排行榜 | Δ 私人排行榜 |
|---|---|---|---|
| 基线 | 0.382 | 0.317 | – |
| 手动 RANSAC | 0.336 | 0.286 | –0.046 |
| 图像尺寸 1024 → 1280 | 0.407 | 0.345 | +0.025 |
| 图像尺寸 1376,相似度=None | 0.489 | 0.426 | +0.026 |
| 穷尽匹配,8/10 | 0.486 | 0.441 | -0.003 |
| TTA,图像尺寸 [840, 1024, 1280] | 0.491 | 0.447 | +0.002 |
| TTA,图像尺寸 [1088, 1280, 1376] | 0.523 | 0.475 | +0.032 |
| 手动图像初始化 | 0.529 | 0.492 | +0.006 |
| 旋转检测 | 0.542 | 0.497 | +0.013 |
| 多次运行重建,匹配阈值 [100, 125, 75, 100] | 0.562 | 0.506 | +0.02 |
最终分数为公共/私人排行榜的 0.506/0.562。
本地验证
作为参考,这是我们使用训练数据集的最新指标报告之一:
urban / kyiv-puppet-theater (26 张图像,325 对) -> mAA=0.921538, mAA_q=0.991077, mAA_t=0.921846
urban -> mAA=0.921538
heritage / cyprus (30 张图像,435 对) -> mAA=0.514713, mAA_q=0.525287, mAA_t=0.543678
heritage / wall (43 张图像,903 对) -> mAA=0.495792, mAA_q=0.875637, mAA_t=0.509302
heritage -> mAA=0.505252
haiper / bike (15 张图像,105 对) -> mAA=0.940952, mAA_q=0.999048, mAA_t=0.940952
haiper / chairs (16 张图像,120 对) -> mAA=0.834167, mAA_q=0.863333, mAA_t=0.839167
haiper / fountain (23 张图像,253 对) -> mAA=0.999605, mAA_q=1.000000, mAA_t=0.999605
haiper -> mAA=0.924908
最终指标 -> mAA=0.783900
最后,我们在最后一天运行了两份提交。其中一份成功使我们获得第二名,但另一份意外地超出了时间限制。有时在比赛的最后一天提交会很紧张。
有用资源
特别感谢以下项目的作者:
• COLMAP
• SuperPoint
• SuperGlue
• check_orientation