AMP®-帕金森病进展预测
哇,这场比赛的顶级排名竞争异常激烈。我早就预料到这种情况,因为我认为只有一个可靠的信号源(即`患者就诊日期`),所有顶尖团队都在努力从中多提取0.1的SMAPE分数。SMAPE是一个百分比指标,所以0.1实际上就是0.001。这就是竞争的激烈程度!
最终排行榜分为两组。前18名团队的SMAPE分数都≤62.5,而之后的团队分数都≥68.4。我认为前18名团队都利用了`患者就诊日期`的信号,而之后的团队则没有。
蛋白质/肽数据的信号
在本次比赛中,Kaggle提供了227个蛋白质NXP特征和968个肽段丰度特征。也就是说,在17个可能的就诊时间点上,每个时间点都有1195个特征。但我们只有248名训练患者。当特征数量 > 训练样本数/10时,就会出现"维度灾难"。换句话说,我们只有足够的训练数据来合理训练25个特征,而不是1195个特征!
我做了一个实验:创建了1000列随机数。使用前向特征选择,我发现随机数列对GroupKFold CV分数的提升,与蛋白质/肽特征的提升量相同。这意味着蛋白质肽数据中可能隐藏着信号,但由于只有248名患者,信号太弱而无法检测到模式(因为没有蛋白质或肽特征比随机数更能提升CV分数)。
患者就诊日期的信号
接下来我搜索了患者就诊日期中的信号。许多Kaggler忽略了我们可以从患者就诊日期中设计特征。以下是一些示例特征:
- 患者首次验血是什么时候?
- 患者是否在首次就诊时进行了验血,是或否?
- 患者就诊了多少次?
- 患者上次就诊是在多久以前?
等等。我们可以创建数百个关于患者何时就诊和何时进行血液检查的特征。我很快注意到以下趋势:就诊更频繁的患者有更大的UPDR评分。这在下图中显示。第一张图是就诊次数正常的患者,第二张是比正常值少1个标准差的患者,第三张是比正常值多1个标准差的患者。在每个图中,我们显示了这些三组患者每次就诊月份的平均目标值:
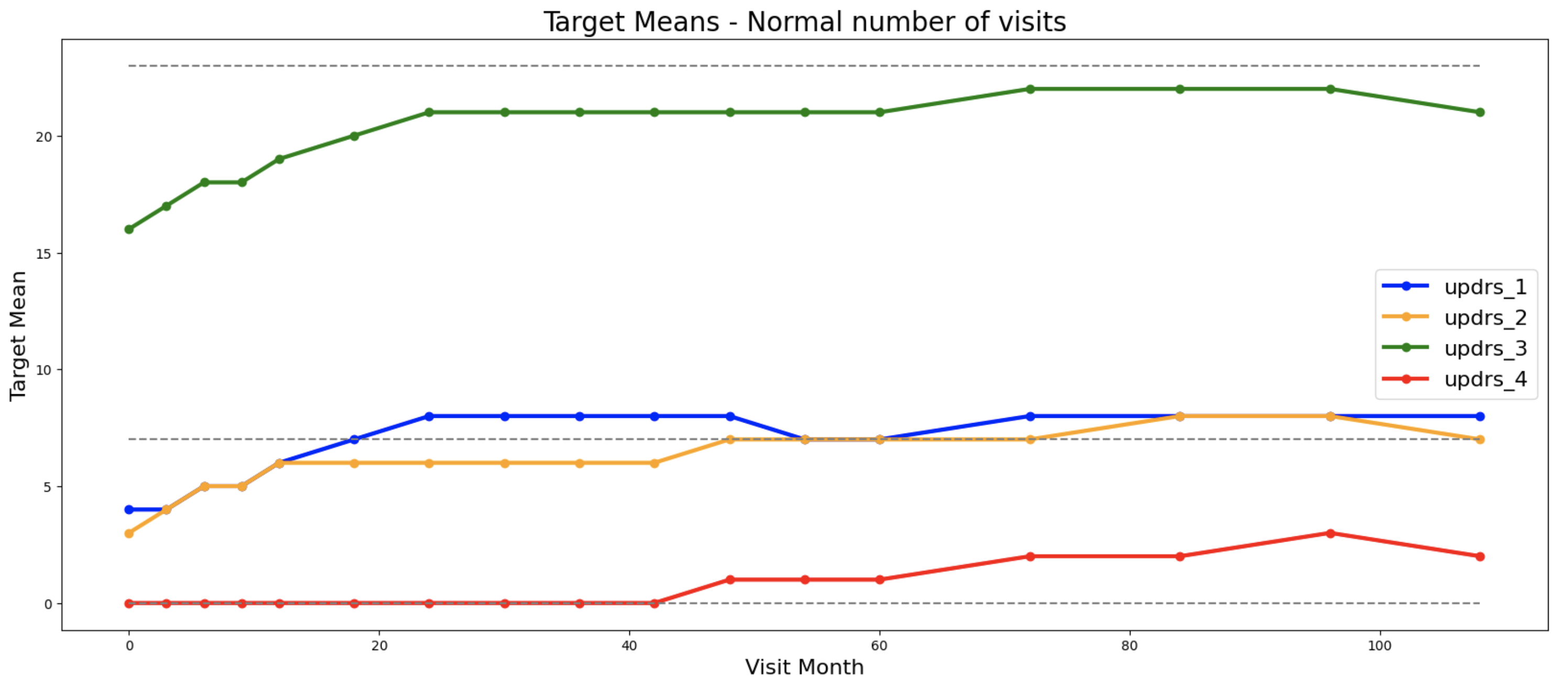
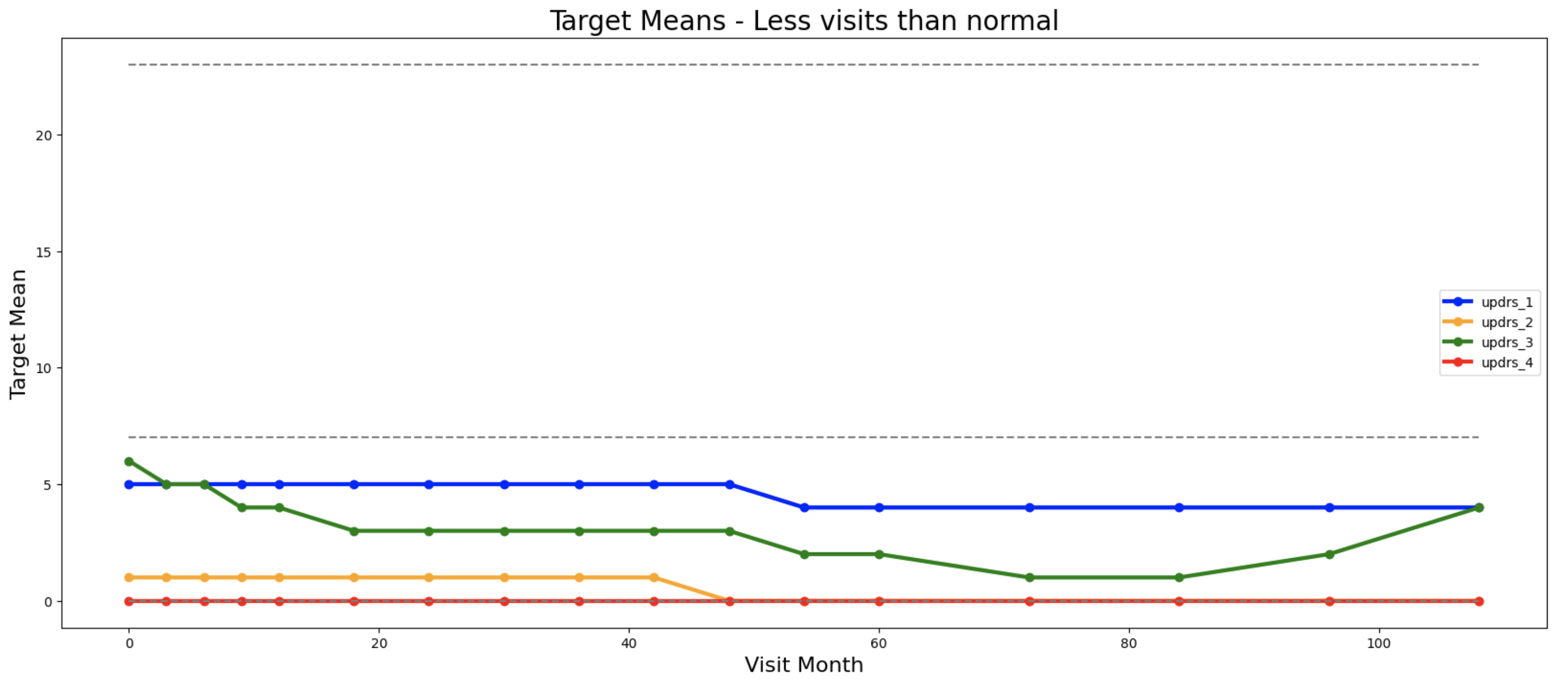
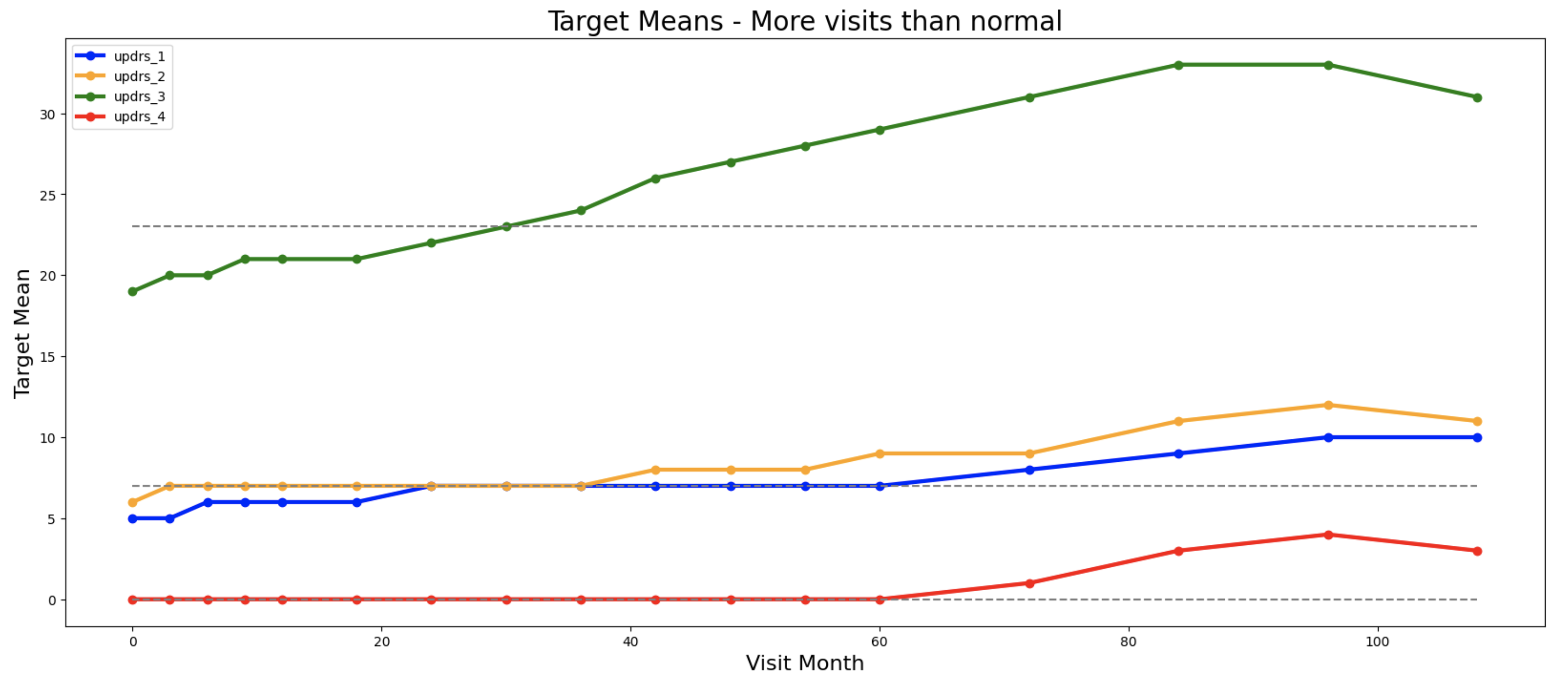
特征工程
上图显示了在`患者就诊日期`中存在信号。提取这个信号的最佳方法是什么?我生成了数百个特征,并使用`for循环`配合RAPIDS cuML SVR来找出哪些特征能提取最多的信号。
最终,简单的"布尔值"效果最好(模型"内部创建了自己的特征")。对于每个就诊月份,我创建了一个布尔变量。例如,对于就诊月份=24,我创建了以下"布尔值":
v24 = 0- 如果我们知道患者在就诊月份=24时没有就诊v24 = 1- 如果我们知道患者在就诊月份=24时确实就诊了v24 = -1- 如果我们不知道患者在月份=24时是否就诊
第三个类别存在的原因是,在Kaggle API的每个时间步,我们都需要预测未来0、6、12、24个月的情况。因此,如果当前就诊月份=12,而我们预测的是就诊月份36,我们就不知道患者是否在就诊月份=24时就诊了。
单一模型RAPIDS cuML - 第8名金牌
一个单一的RAPIDS cuML SVR模型,使用11个特征进行训练,这些特征包括visit_month和v0、v6、v12、v18、v24、v36、v48、v60、v72、v84(其中v特征如上所述),达到了CV = 55.5、Public LB = 55.4和Private LB = 60.5的成绩。这是第8名金牌。使用RAPIDS cuML非常棒,因为它让我能够在几分钟内试验几十个模型!
单一模型TensorFlow MLP - 第4名金牌
在找到上述特征后,我尝试了不同的模型类型。我尝试了使用`PseudoHuber损失`的XGBoost,但其CV表现不如RAPIDS cuML SVR。接着我尝试了使用`MeanAbsoluteError`的TensorFlow MLP。我们构建了一个包含10个隐藏层的MLP,每个隐藏层有24个单元,激活函数为Relu。我们没有使用Dropout和BatchNormalization。我们使用Adam优化器训练了15个epoch,学习率LR = 1e-3,然后再用LR = 1e-4训练15个epoch。这达到了CV = 55.0、Public LB = 54.9和Private LB = 60.1的成绩。这是第4名金牌。
创建训练数据
我们的模型仅使用train_clinical_data.csv进行训练。为上述特征创建合适的训练数据并不简单。我们需要将原始训练数据中的每一行转换为4个新行。如果原始行是patient_id = 55和visit_month = 24,那么我们需要将这一行替换为4个新行:
- patient_id=55, visit_month=24, 并且 v0=X1, v6=-1, v12=-1, v24=-1, v>24=-1
- patient_id=55, visit_month=24, 并且 v0=X1, v6=X6, v12=-1, v24=-1, v>24=-1
- patient_id=55, visit_month=24, 并且 v0=X1, v6=X6, v12=X12, v24=-1, v>24=-1
- patient_id=55, visit_month=24, 并且 v0=X1, v6=X6, v12=X12, v24=X24, v>24=-1
其中X1、X6、X12、X24的值是0或1,取决于patient_id=55在月份0、6、12、24是否就诊。这4个新行对应的是当前就诊月份减去0、6、12、24。如果任何减法结果不是有效的就诊月份,则不创建该行。
第4名解决方案代码
我发布了使用TensorFlow MLP的第4名提交代码,这里。请享用!