第二名解决方案
祝贺所有获奖者,感谢Kaggle举办了如此有趣的比赛。这次比赛对我来说是一次非常棒的学习经历。我真的很期待阅读每个人的解决方案。
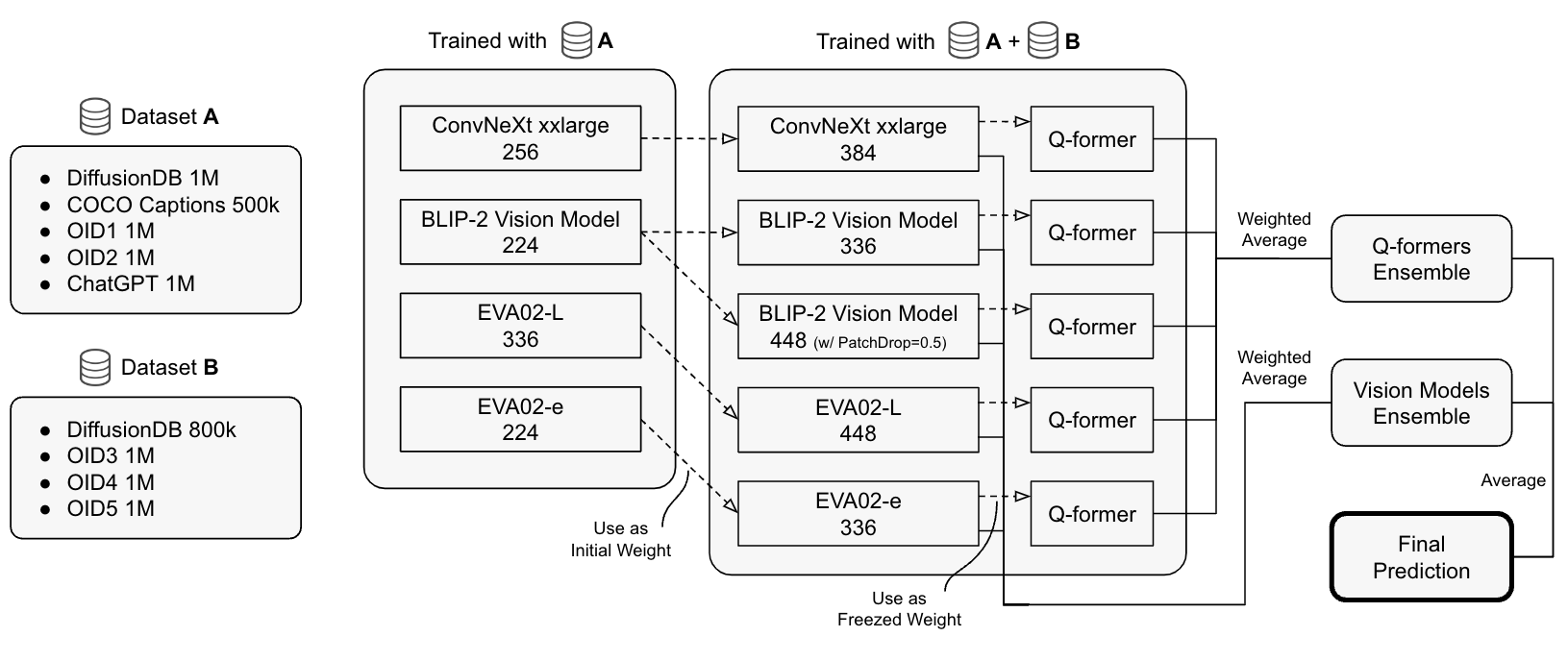
我的解决方案基本上与公开笔记本中的ViT方法相同。我通过运行Stable Diffusion创建了自己的数据集,并训练了一个模型以监督方式来预测句子嵌入。概览如下图所示。
数据集生成
准备工作
为了在使用fp16时将生成速度提高4倍,进行了以下修改:
- 将调度器从DDIM更改为DPMSolver++(diffusers.DPMSolverMultistepScheduler),并将步数从50步减少到16步。
- 使用xformers
曾担心减少生成步数会导致提示到图像的映射发生偏移,但没有显著的定性差异,而且生成速度提升的优势更大,因此我选择了这种方法。
xformers带来了约30%的速度提升。xformers也在模型训练中使用,后文会描述。
请注意,生成过程中使用的随机数对最终生成的图像有重大影响,因此需要使用不同的种子来生成图像。起初我将种子固定为0以确保可重复性,但我意识到这个错误,改为每个提示使用不同的种子,这大大提高了分数。我使用zlib.adler32、提示集名称和提示编号来生成种子。
关于指导尺度,我一直使用diffusers的默认值7.5,直到我意识到9.0似乎是正确的值(链接),因此我使用了这两个值生成的数据。排行榜分数显示7.5和9.0之间没有显著差异,但使用3.0的分数明显更低。
DiffusionDB
为了处理Stable Diffusion特有的词汇,我们使用DiffusionDB中的提示生成图像。去除重复后,大约有180万个提示,并为所有提示生成了图像。
COCO字幕
使用Microsoft COCO Captions中的字幕来生成图像。从训练和验证集中约60万个字幕生成了50万张图像。
Open Images
为了创建更加多样化的提示集,我利用了Open Images Dataset V3(OID)中的自然图像和图像转文本预训练模型。将OID中的图像输入到图像转文本模型,生成的字幕作为提示输入到StableDiffusion。OID包含900万张自然图像,其中前500万张被用于生成。
使用Salesforce/blip2-flan-t5-xxl作为图像转文本模型。我使用Nucleus采样,参数为do_sample=True和top_p=0.9。
比赛中的示例提示包含多个对象和多个句子,但BLIP-2输出的字幕默认倾向于生成非常简洁的句子。因此,通过链式调用BLIP-2的字幕生成,我确保生成具有一定复杂度的句子。链式生成过程如下:
- 像往常一样生成一个以
"a photo of"开头的句子(记生成的句子为A) - 生成一个以
"a photo of" + A开头的句子(记此为B) - 输出
A + B作为最终字幕
创建的提示集如下:
| 提示集名称 | 子集 | 图像数量 | 链数 |
|---|---|---|---|
| OID1 | train0 | 100万 | 2 |
| OID2 | train1 | 100万 | 3 |
| OID3 | train2 | 100万 | 1* |
| OID4 | train3 | 100万 | 2 |
| OID5 | train4 | 100万 | 2 |
对于OID3,为了实现自然图像中不存在的对象组合,通过将两个使用chain=1创建的短字幕用逗号连接来创建提示。具体来说,将chain=1创建的短字幕使用SentenceTransformer转换为句子嵌入,并使用球面K均值聚类分为1000个簇。然后,对于每两个簇的组合,我们从每个簇中随机选择一个字幕并用逗号连接。
ChatGPT (gpt-3.5-turbo)
这个数据集利用了此笔记本的思路。当我尝试使用ChatGPT生成提示时,发现使用相同的提示只会产生相似的生成结果。改变温度等参数确实有所改善,但也更容易产生断句或过长的句子。因此,我考虑利用之前生成的提示来修改发送给ChatGPT的提示,并用以下代码实现。
command = (
"Describe a fairly random scene with multiple objects by one short sentence with some modifiers in one line."
"\nHere are some examples of such texts:"
)
sample_set = [
"hyper realistic photo of very friendly and dystopian crater",
"ramen carved out of fractal rose ebony, in the style of hudson river school",
"ultrasaurus holding a black bean taco in the woods, near an identical cheneosaurus",
"a thundering retro robot crane inks on parchment with a droopy french bulldog",
"portrait painting of a shimmering greek hero, next to a loud frill-necked lizard",
"an astronaut standing on a engaging white rose, in the midst of by ivory cherry blossoms",
'Kaggle employee Phil at a donut shop ordering all the best donuts, with a speech bubble that proclaims "Donuts. It\'s what\'s for dinner!"',
]
generated_prompts: Sequence[str] = []
for _ in range(num_trials):
if len(generated_prompts) < 5:
examples = list(sample_set)
else:
examples = list(np.random.choice(sample_set, 4, replace=False)) + list(
np.random.choice(generated_prompts, 3, replace=False)
)
np.random.shuffle(examples)
prompt = command + "".join([f'\n"{e}"' for e in examples])
generated_prompts = send_to_chat_gpt_and_cleansing(prompt)通过这种方法,我创建了约100万个提示,去除重复后输入到Stable Diffusion中,生成了约100万张图像。
我还测试了一些其他的大型语言模型,特别关注那些开源权重的模型,但根据我的定性评估,无法使用相同方法获得与gpt-3.5-turbo相当或更优的提示集。这类模型的典型行为是开始某种解释而不是按期望格式回答,或只能生成略微修改的示例。我没有测试LLaMA及其衍生模型,因为我无法以符合许可的方式获得LLaMA的权重。
模型与训练
CLIP模型
在最初的简单实验中,使用CLIP的预训练模型比ImageNet分类模型表现更好。因此,我专注于微调CLIP模型。
最终提交中使用了以下四个模型:
- ConvNeXt xxlarge (CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-rewind)
- BLIP-2 VisionModel (EVA01-g?, Salesforce/blip2-opt-2.7b)
- EVA02-L (timm/eva02_large_patch14_clip_336.merged2b_s6b_b61k)
- EVA02-e (timm/eva02_enormous_patch14_plus_clip_224.laion2b_s9b_b144k)
线性探测
关于CLIP的微调,有建议认为线性探测(LP,仅训练最后一个线性层)和LP-FT(在LP之后微调整个模型)对于泛化是有效的。事实上,这些方法在我的实验中也很有效。
分辨率
提高分辨率也产生了显著效果。CLIP模型通常在224分辨率下训练,但我认为224对于识别包含多个对象的复杂上下文是不利的。
通过插值位置编码,ViT可以对高于训练分辨率的输入进行推理,性能仅略有下降。例如,可以使用timm中实现的resample_abs_pos_embed函数。通过这种方式,可以将较低分辨率训练的模型用作较高分辨率训练时的良好初始值。
在比赛中期之前,我一直使用224分辨率训练的模型,但在比赛后期,我以这些模型为初始值,在336或448分辨率下训练模型,从而提高了分数。
Q-former
SentenceTransformer的句子嵌入是标记嵌入的归一化和。我考虑利用这些标记嵌入作为额外的监督信号。
我实现了一个使用BLIP-2中的Q-former的架构,将视觉模型输出的patch嵌入转换为长度为77的标记嵌入。然后将该模型的输出与SentenceTransformer的标记嵌入进行比较(用零填充至长度77),并基于此比较训练模型。简单地使用均方误差(MSE)会受到词序的严重影响,因此我使用匈牙利算法找到最小MSE的匹配,并计算这些匹配之间的MSE。我还使用了句子嵌入之间的余弦相似度。
Q-former和视觉模型的同步训练不稳定,在比赛期间我无法取得成功。然而,通过冻结预训练的视觉模型并仅训练添加的Q-former,单个模型在排行榜(LB)上的性能提升了+0.001到+0.003。此外,由于视觉模型是冻结的,我可以在使用Q-former预测时几乎不增加额外成本地获得视觉模型的独立输出。这在集成中提供了轻微的好处。
Q-former在此问题设置中的效果并不特别显著,但我相信它在反转任务的原始意义上会很有用,即目标是重现图像。
加权平均
对于集成,我使用了加权平均。权重使用Adam和我的ChatGPT数据集验证集进行了优化。