第五名解决方案:结合GraphNet、Transformer与LSTM元模型
我们想感谢组织者和Kaggle团队共同组织了这场激动人心的挑战。当我们分享在"科学大便当盒"中烹制的科学盛宴时,请接受我们对稍迟提交方案的歉意。比赛竞争异常激烈,我们的团队在结束前两周时曾落后奖牌区400多名。通过努力和坚持,我们最终提升至第5名,并获得了首个金牌奖牌。
总结:
- Transformer使用两个256个区间的分类头,智能标签平滑 → 1.003
- 增加GraphNet在KNN图构建中使用的特征数量,将激活函数改为LayerNorm,整体增大模型规模,直接预测
(x, y, z)方向而非方位角和仰角 → 0.990 - LSTM模型选择器,接收输入数据以及Transformer和GraphNet的预测结果,返回应使用哪个模型的预测 → 0.974
Transformer
我们使用了标准的编码器架构,包含8层、512的模型尺寸和8个注意力头。输入包括(x, y, z, t, charge, auxiliary, is_core, rank)。is_core是一个0/1值,表示传感器是否属于深核心部分。rank的计算方式参考了这篇优秀的LSTM笔记本。对于(x, y, z, t, charge)等特征,我们在输入Transformer之前使用了几层线性层进行预处理。而(auxiliary, is_core, rank)由于其离散性质,采用了嵌入方式处理。
我们为方位角和仰角各设置了两个输出头。每个头预测256个值,代表不同的区间。我们使用等间距区间,并通过带有平滑标签的交叉熵进行训练。标签平滑的方式使得相邻区间也获得一定概率(不同于标准标签平滑中将剩余概率平均分配给所有类别)。对于方位角,这种平滑采用循环方式处理,因此预测\\(0\\)和\\(2 \\pi \\)是等价的。预测时只需对区间取argmax。我们尝试了不同数量的区间(16到256),更多区间带来更好性能,但128和256之间差异不大,最终选择了256。
我们在TPU上训练了760k步,批大小为512,序列长度为256,约3个epoch。学习率采用余弦调度,峰值LR=3e-5,每10k步重复一次周期(事后看来周期应该更长,但初期不确定训练效果)。最后160k步将峰值LR调整为3e-6。整个训练耗时约26小时。760k步后仍能看到轻微改进,但我们决定专注于其他思路。这使得模型在公开排行榜上达到1.003的分数。
GraphNet
我们以标准GraphNet模型为基础,结合了早期分享奖金笔记本中的额外输入特征。
模型输入包括(x, y, z, t, charge, auxiliary, quantum_effeciency, wrong_charge_dom, ice_absorption, ice_scatter),其中wrong_charge_dom标记了1229号传感器,因为我们的分析表明该传感器可能存在问题。模型输出为方向。
为实现最终排行榜分数,我们对模型进行了多项改进:
首先,在查看DynEdge代码时发现,features_subset参数(用于DynEdge中计算最近邻的潜在特征子集)不仅应用于第一层,也应用于其他层的输入。凭直觉认为这有所限制,我们改为非首层的features_subset可变。最终设置为48(更大似乎效果更好)。这一改进使模型在排行榜上达到0.998。
其次,我们将BatchNorm1d替换为LayerNorm。这一决定源于训练和验证时MAE指标存在较大差异。即使标准模型(使用BatchNorm1d)在不切换为评估模式时也表现更好,因此我们改用训练和评估模式下一致的LayerNorm。
最后,我们全面调整了训练过程。使用AdaBelief优化器,与Transformer不同,GraphNet采用阶梯式学习率调整:从1e-3开始,每200k步将学习率减半。总步数700k,批大小512,在RTX 4090上耗时约3天。
最终,经过所有改进和模型扩展,我们在排行榜上达到了0.990的分数。
模型堆叠集成
在比赛最后几天,我们有两个模型但已无时间进一步训练。之前尝试集成它们但结果不理想。分析发现,两个模型的预测有时差异很大。若能完美选择正确模型,下界约为0.810。
比赛结束前两天,我们从最佳Transformer(两个分类头之前的最后一个公共层)和GraphNet(预测方向前的层)提取了前10个数据批次的嵌入向量。最初将这些嵌入向量与模型预测一起输入XGBoost,达到了57%的准确率,在公开排行榜上得分为0.976(内部验证为0.978)。
随后,我们编写了一个简单的3层双向LSTM作为模型选择器。我们认为使用不同架构(非Transformer或GraphNet)的选择器有助于学习数据中的不同特征,从而做出更好的选择。
LSTM的隐藏状态使用拼接的Transformer和GraphNet嵌入进行初始化,并将脉冲子集作为输入序列*。我们认为在事件数据上训练有助于做出更好的决策。模型训练了约9个epoch(仅前10个批次),耗时约8小时。这使得准确率提升至58%,最终得分为0.974。
(*)我们也尝试将嵌入向量拼接到输入序列或最后一个分类层之前,但这两种方法的效果都不如仅用嵌入初始化隐藏状态。
最终提交的整体架构如下:
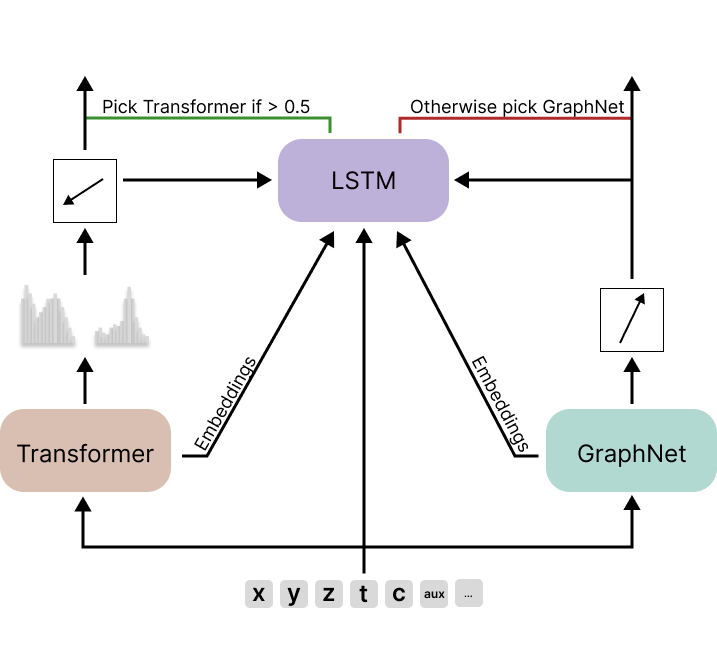
尝试过的方法
- 在不同数据子集上训练两个Transformer模型并尝试简单集成(相加logits/softmax后取argmax),但仅带来0.002的微小提升
- 在GraphNet嵌入上训练独立的分类头(类似Transformer),然后通过相加logits/softmax并取argmax集成两个模型,略微降低了误差但效果不显著
- GraphNet的分类任务效果不佳,方位角和仰角的回归也不理想。方向回归表现最佳
- 比赛初期,我们参考了论文《A Convolutional Neural Network based Cascade Reconstruction for the IceCube Neutrino Observatory》,实现了一个带有六边形卷积的3D卷积网络变体,旨在DOMs空间局部化。然而,我们未能使其有效工作,平均角度误差无法降至1.2以下。可能的原因是比赛数据与该论文使用的数据差异较大:后者在时间维度上分辨率很高(脉冲每2ns采集一次),而我们的数据要稀疏得多
推理代码
https://www.kaggle.com/grzego/inference-lstm-ensembler-graphnet-transformer