第 18 名 - 金字塔集成 (Pyramid Ensemble)
副标题:用小模型预测 100% 测试集,然后用中等模型预测前 50%,再用大模型预测前 10%,最后用超大模型预测额外的前 6%。
感谢 Kaggle 和社区带来了一场愉快的竞赛。我的最终解决方案是一个“金字塔集成”,旨在最大限度地利用有限的提交推理时间和计算资源。
首先,我们用小模型推理 100% 的测试样本,然后确定集成模型对哪些预测更不确定。接下来,我们用中等模型预测不确定性最高的前 50% 测试样本。我们将这些预测以 2 倍权重纳入,并重新计算预测不确定性。随后,我们用大模型预测不确定性最高的前 10%。我们将这些新预测以 4 倍权重纳入,并重新计算预测不确定性。最后,我们用超大模型预测前 6%,并以 8 倍权重纳入这些预测。更多信息请参见下图。
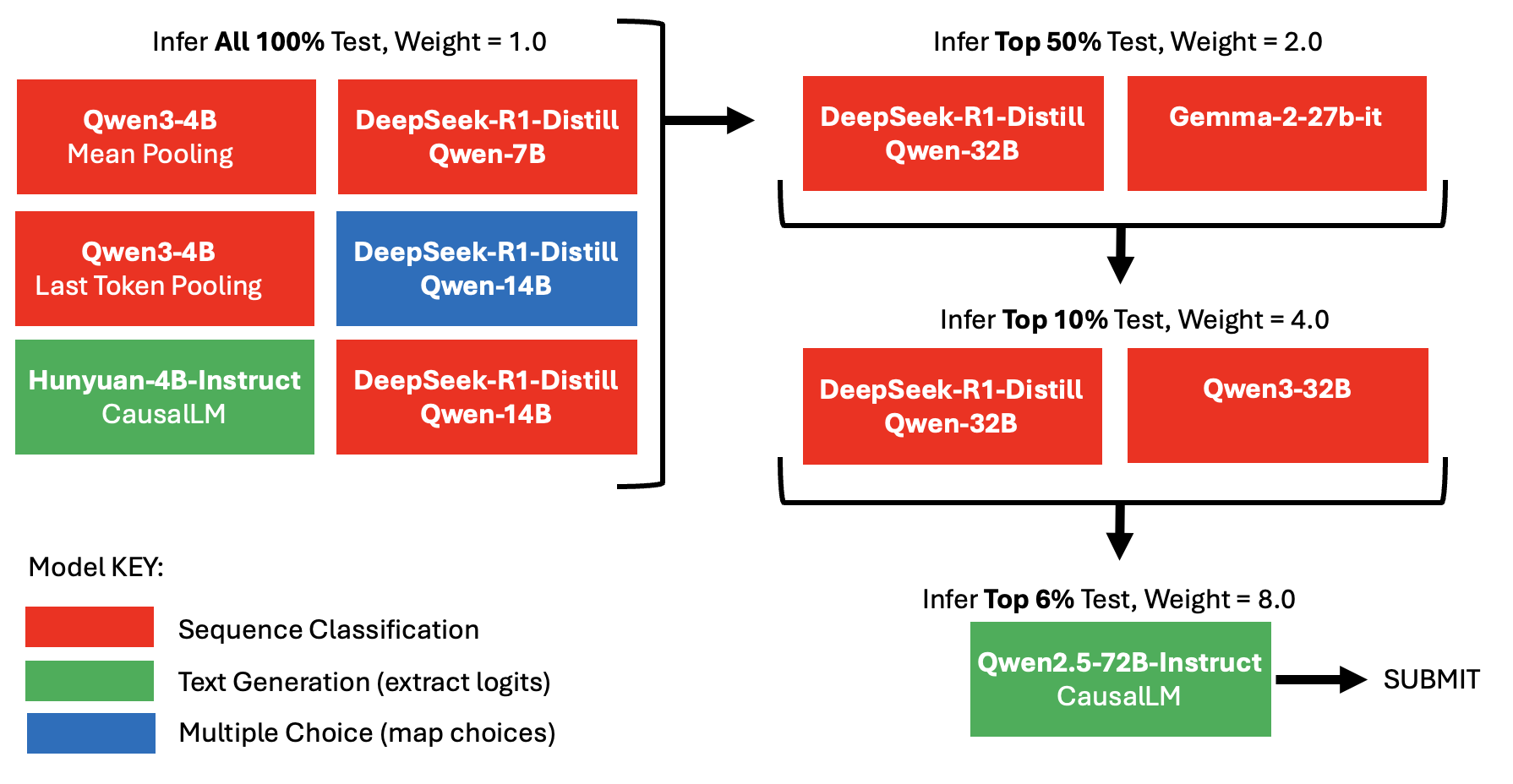
我的最终“金字塔集成”提交结果如下:5 折交叉验证 CV = 0.951,公共排行榜 = 0.952,私有排行榜 = 0.947。
多样性 (Diversity)
我在竞赛一开始就加入了,所以有 3 个月的时间调查许多不同的方法。在 3 个月内,我训练了 1000 多个 LLM 模型。每天我大约有 4 张 A100 GPU 在运行实验。我调查了以下内容:
- 不同的骨干模型 (Backbones) (例如 Qwen, Gemma, Llama 等)
- 不同的范式 (Paradigms) (例如 序列分类,文本生成,多项选择,多头等)
- 不同的提示词 (Prompts) (例如 列出 MC_Answer 选项,添加 'is_correct = Yes/No',列出目标类别选项,添加系统角色等)
- 生成式 AI 辅助 (例如 创建合成数据,vibe coding 等)
- 不同的训练配置 (全量微调,LORA,QLORA,层衰减,预热等)
- 不同的推理配置 (vllm, huggingface, awq, bitsandbytes 等)
多种范式 (Multiple Paradigms)
范式 - 序列分类和/或文本生成
解决这个问题有很多方法。最直接的方法是使用 AutoModelForSequenceClassification() 处理 65 个类别,或者去除 True/False 前缀处理 37 个类别。另一种强大的方法是 AutoModelForCausalLM(),模型生成单个 token 来预测目标类别,我们提取该 token 的 logits/概率。
范式 - 多项选择 (Multiple Choice)
另一种效果很好的方法是将问题转化为 LLM 多项选择,例如:
Question: A box contains 120 counters. The counters are red or blue. 3/5 of the counters are red. How many red counters are there?
Correct Answer: 72
Student Answer: 24
Student Explanation: B because 3 fifths of 5 is 75
Choices: A) Correct B) Irrelevant C) Incomplete D) Wrong_Fraction E) Neither一旦我们去除 "True_" 和 "False_" 前缀,只剩下 37 个目标类别。对于每个问题,始终只有 6 个或更少的可能目标类别。因此,每个训练样本和测试样本都可以 reformulated 为选项 A, B, C, D, E, F(有时 C, D, E 和/或 F 为空)。我们可以随机打乱选项。模型必须学会阅读选项,理解选项,并从 6 个中选择 1 个。之后,我们将预测映射到具有 65 列(或 65 个原始目标类别)的 Numpy 概率数组中。
范式 - 多头架构 (Multi-head Architecture)
最有趣的范式是多头架构。很难让它工作,但我最终让多头架构使用 3 个头正常工作并表现良好。第一个头预测列 Category = ["True_Correct", "True_Neither", "True_Misconception", "False_Correct", "False_Neither", "False_Misconception"]。第二个头预测 True Misconceptions,第三个头预测 False Misconceptions。对于给定的训练样本,第一个头始终提供损失,然后头 2 和头 3 可能提供也可能不提供损失。
例如,如果完整标签是 True_Correct:NA。总损失只是第一个头(头 2 和头 3 不提供损失)。如果完整标签是 True_Misconception:Shorter_is_bigger。那么总损失是第一个头损失加上第二个头损失(头 3 不提供损失)。如果完整标签是 False_Misconception:WNB,那么总损失是第一个头加上第三个头(头 2 不提供损失)。
提示词多样性 (Prompt Diversity)
创建提示词有很多选择。例如,我们是在提示词中添加 is_correct = Yes/No,还是让模型自己确定?像这样的决定产生了很大的差异。我们还可以列出 MC_Answer 选项。我们可以列出特定 QuestionId 和 MC_Answer 组合的可能目标类别选项。我们还可以使用带有系统和用户角色的聊天格式。或者不使用。我们可以添加额外信息来帮助分类目标。我最好的单模型 笔记本在此 (CV 0.949, LB 0.949) 使用了以下提示词:
You are an expert mathematics assessor.
Question: What fraction of the shape is not shaded? Give your answer in its simplest form. [Image: A triangle split into 9 equal smaller triangles. 6 of them are shaded.]
Choices: A) \( \frac{1}{3} \), B) \( \frac{3}{6} \), C) \( \frac{3}{8} \), D) \( \frac{3}{9} \)
Response: \( \frac{3}{9} \)
Explanation: 6/9 is shaded therefore 3 must be left therefore the answer is 3/9.
Now classify the explanation as Correct explanation (regardless of whether response is correct), Misconception:Incomplete, Misconception:WNB, or Not an explanation.关于这个提示词的一些细节:
- 添加了类似系统的指令
- 枚举了 MC_Answer 选项
- 列出了特定 QuestionID 和 MC_Answer 的目标类别
- 澄清了一些目标类别,例如解释"Correct"是“无论响应是否正确”。
生成式 AI (Generative AI)
我尝试了许多使用 GPT 生成合成数据的实验。首先,使用所有训练数据的本地 OOF,我确定了哪些类别被混淆。然后我提示 ChatGPT4 专门制作合成数据,以帮助 LLM 学习这些混淆类别之间的区别。当然,我是以“袋外 (out of fold)"方式进行的,以防止泄露。结果喜忧参半,有时有改进,但大多数时候没有。最后我没有使用任何合成数据,因为我不信任它。
训练设置 (Train Setup)
对于 14B 及以下的模型,我主要进行全量微调。对于 14B 及以上的模型,我主要进行 LORA 或 QLORA。(对于 14B 模型,我同时做了 LORA 和非 LORA)。我使用 A100 GPU 80GB 显存训练模型。通常我会使用单 GPU 训练,但对于最大的 72B LLM,我使用 2xA100 或 4xA100 训练。我典型的 LORA 设置是 r=32, a=64, dropout=0.05 或 0.1, target modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj"]。我会使用梯度检查点 (gradient checkpointing) 和较大的 batch size,如 64。学习率通常在 1e-4 或 2e-4 左右。优化器通常是 AdamW4bit。
推理设置 (Infer Setup)
我做了很多实验来优化推理。我的主要创新是确保 2xT4 GPU 始终以 100% 运行。因此,如果模型只需要 1 个 GPU,我会运行两个线程,一个线程推理 test.csv 的前半部分,而第二个线程推理 test.csv 的后半部分。对于较大的模型,使用 CasualLM 和 vllm 是最有效和最快的。但我也使用纯 PyTorch 和/或 HF Trainer 进行推理。
骨干模型 (Backbones)
哇!有太多的 LLM 可以尝试。我可能尝试了 1B 到 72B 之间的每个 LLM 骨干模型。哈哈,是的,我训练了很多模型。对于每个骨干模型,我会尝试不同的范式、提示词、训练设置和推理设置。使用 ChatGPT 帮助我快速启动一切并解决出现的任何错误。