第11名解决方案
首先,我想表达我对许多参赛者的钦佩之情,你们找到了如何在一个完全陌生的领域中前行的方法。更重要的是,你们非常慷慨地与我们分享了这些见解。掌握蛋白质建模、使用蛋白质语言模型以及进行能量和分子动力学计算所需的领域知识需要很长时间。然而,你们中的许多人做到了,并使我们能够进行一场有意义且富有成效的比赛。谢谢大家!
你们现在可能已经在其他方案分享中听到了这一点,但我还是要重申:集成解决方案是必由之路。
我一开始比较懒散,主要是因为如果不投入大量时间,还不清楚如何使用他们提供的训练数据集。有几个基于测试数据的非常不错的解决方案,所以我也就顺着这个思路走了。像其他人一样,我在弄清楚我们可以从测试数据中计算出哪些分子量最有信息量,以及如何混合它们以获得最佳分数。一路上我一直警告说,pLDDT值和B因子并不能真正预测热稳定性,但有足够的证据表明它们对这种蛋白质有效。在10月中旬的某个时候,当我偶然排在第3名时,我突然意识到我需要做出决定:是专注于在这个核酸酶上获得最佳结果,还是尝试制作一个尽可能通用的模型,希望它也能适用于这种蛋白质。除非你全身心投入,否则很难付出最大的努力,所以我选择了后者。
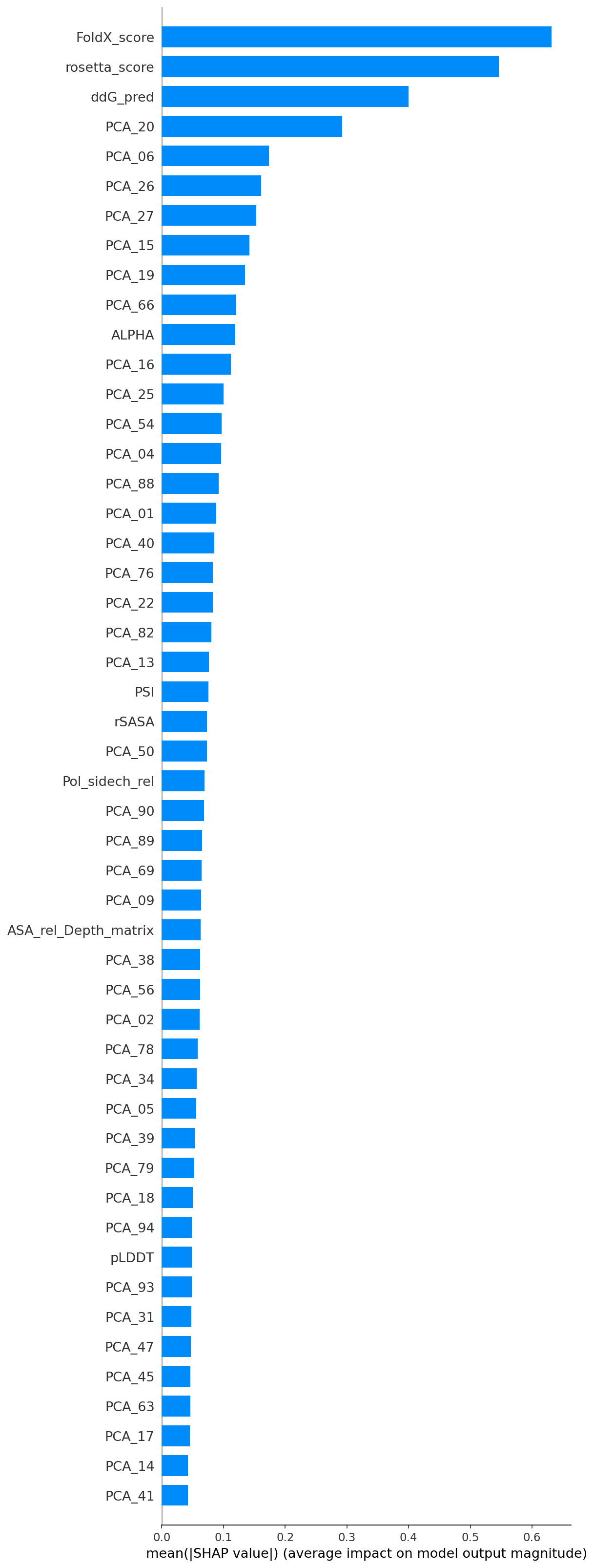
我已经知道Rosetta的能量函数效果很好,但以前从未使用过FoldX进行诱变。事实证明,仅基于测试数据的FoldX得分就让我的公共LB分数达到了约0.47。我使用了Rosetta鲜为人知的程序 ddg_monomer 和 pmut_scan,它们是为突变体评分设计的。pmut_scan 单独在公共LB上得分0.499,这让我确信使用这些程序及其基于物理的能量函数是势在必行的。与此同时,我开始构建训练数据集,并对所有野生型蛋白质和突变体进行全规模的AlphaFold2建模。最后总共有2335个测试突变体和2964个训练突变体,其中最后约300个PDB模型尚未完成。这使我的GPU自11月初以来一直处于恒定的工作负载状态。获得前1000-1500个训练突变体的dTm值相对容易,这些突变体的残基编号匹配良好,并且是在单一pH值下测量的。到了下半程,这就变得很困难了,因为我必须手动验证蛋白质残基是否与PDB残基匹配,必须在纳入之前找出哪个pH值具有生理相关性,等等。直到12月中旬我才完成训练数据集(除了AlphaFold2建模),但最终我有了2964个精心策划的突变体用于训练。我从PDB文件中提取了约50个特征,计算了FoldX、ddb_monomer和pmut_scan得分,进行了ESM2和ProtT5嵌入,并从野生型中减去了突变值。最后,我通过对dTm和所有其他量添加负号来使数据集对称。这现在是一个表格数据集,可以使用任何机器学习方法进行建模,为了速度我选择了LightGBM,为了模型的多样性选择了TabNet。当这个数据集按dTm分层并按75:25分为训练集和测试集时,我得到了约0.6的10倍CV,以及测试数据上0.65的Spearman相关系数。看起来它是有效的,我认为它在预测ddG而不是dTm方面会更好。我将在下面粘贴由LightGBM树的SHAP确定的特征的相对重要性。你会看到基于能量的特征(FoldX、ddg_monomer和pmut_scan得分)是最重要的,其次是表示为PCA组件的语言嵌入。从PDB文件中提取的结构特征单独使用时效果相对较好(约0.5的10倍CV),但当它们处于一个大的特征集中时,很少有能进入按重要性排名的前50个特征的。
现在是时候在我们的核酸酶上测试这个模型了——唉——它效果不太好。最好的LightGBM模型在公共LB上得分为0.47-0.5,而最好的TabNet模型在0.45-0.48范围内。当我留出一个通用测试数据集时,它们都有相当高的CV分数并且表现良好,但这并没有转化为对Novozyme蛋白质的预测效果。最终,我混合了5个LightGBM模型和2个TabNet模型,在公共LB上得分0.531,在私有LB上得分0.511。考虑到我们在比赛开始时的假设,这是一个不错的分数,但这还不足以获得任何奖牌。
在最后两周,我回到了我基于测试的模型,并决定将它们与我通用训练中的LGB和TabNet模型混合。由于我没有折叠外数据来指导混合过程,这必须再次仅使用公共LB分数作为指导来完成。这总是涉及运气。最后,我选择了公开可用的ThermoNet V3(我想它得分约0.59)、我的pmut_scan模型(0.499)、与我发布的略有不同的SASA模型(0.453)、与我发布的略有不同的深度模型(0.42)、来自通用训练的两个LGB模型(得分0.505和0.5)以及一个TabNet模型(得分0.477)的等权混合。该混合在公共LB上得分为0.604,在私有LB上得分为0.529,这最终是我提交的最佳分数。有超过20个混合模型(包含2或3个TabNet模型)在私有LB上得分在0.53高位,但根据较低的公共LB分数,我没有选择它们中的任何一个。
还有很多其他没用的事情,还有几件我不确定它们是否有效的事情。我会稍后在帖子中添加它们,或者写一个单独的话题。
再次感谢大家在比赛过程中,尤其是过去两天里对我的支持和鼓励。我总是从每次比赛中学到东西,这次也不例外。
PS:对我们蛋白质的最后一次精彩观察在这里。