祝贺特级大师 Amed!
祝贺 Amed ( @amedprof ) 成为 Kaggle 最新晋级的竞赛特级大师!Amed 是我们团队的超级明星,他设计了我们要用的大部分模型。他真正赢得了 Kaggle 竞赛特级大师的头衔!
第三名解决方案总结
我们的解决方案是由 24 个模型组成的集成,没有使用伪标签。大多数模型使用 Deberta-v3-large 骨干网络和各种技巧。集成模型是通过爬山法选出的。与 Amed ( @amedprof ) 和 CroDoc ( @crodoc ) 合作是一件非常愉快的事情。谢谢大家!
爬山法 - CV 0.4420
我喜欢爬山法,因为它可以处理大量模型并挑选出最佳的小部分模型子集。(即它就像 Lasso 回归)并且它能计算集成模型的权重。
我们从 CV 分数最高的单个模型开始(对我们来说是 0.4470)。然后我们遍历所有其他模型,选择帮助最大的第二个模型。然后选择第三个,以此类推,直到新模型不再有帮助。我们不带伪标签的集成达到了 CV 0.4420。我们允许爬山法使用负权重,这比仅使用正权重提升了 CV +0.0010 和 Private LB +0.0060。
while not STOP:
potential_new_best_cv_score = GET_BEST()
for k in range( len(MODELS) ):
for wgt in range(-0.5,0.51,0.01):
potential_ensemble = (1-wgt) * current_best_ensemble + wgt * MODELS[k]
cv_score = compute_metric( potential_ensemble )
if cv_score < potential_new_best_cv_score:
potential_new_best_cv_score = cv_score
REMEMBER_THIS_MODEL(k,wgt)
current_best_ensemble, STOP = UPDATE_BEST()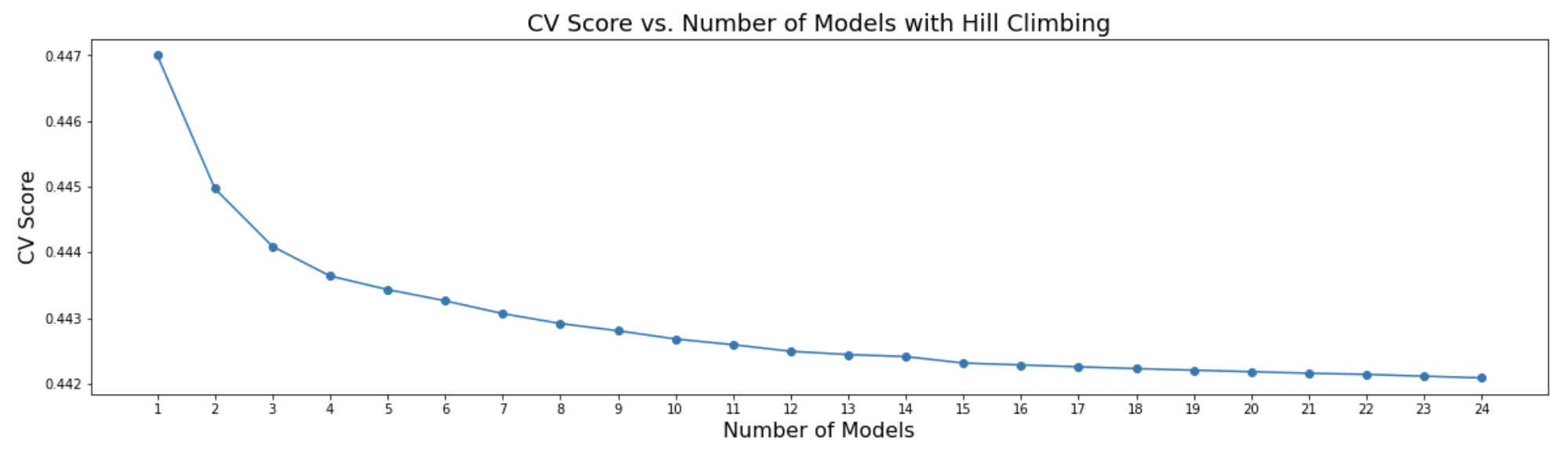
模型 - CV 0.4470
每天,我们都会训练新的多样化模型。然后我们运行爬山法,看看新模型是否会被选中。我们不需要制作 CV 分数很高的新模型,我们只需要制作多样化的新模型。以下是爬山法从我们的 50 个模型中按顺序选择的结果。我们观察到 CV 分数最高的模型并不是首先被选中的。相反,爬山法选择了多样化的模型。
集成 CV 分数的提升如上图所示。下表显示了单个模型的 CV 分数。我们不带伪标签的最佳单个模型达到了 CV 0.4470。
| 选择顺序 | 骨干网络 | CV 分数 | 权重 |
|---|---|---|---|
| 1 | deberta-v3-large | 0.447 | 0.190 |
| 2 | deberta-v3-large-squad2 | 0.4524 | 0.142 |
| 3 | deberta-v3-large | 0.4498 | 0.124 |
| 4 | deberta-large-mnli | 0.4548 | 0.068 |
| 5 | deberta-v3-large | 0.4492 | 0.133 |
| 6 | xlm-roberta-large | 0.4575 | 0.092 |
| 7 | deberta-v3-large-squad2 | 0.457 | -0.160 |
| 8 | deberta-v3-large-squad2 | 0.4525 |