第25名方案
感谢主办方举办了一场精彩的比赛。
起初,我尝试使用文本-图像对比学习方法,并尝试了UMAP等降维技术,还尝试将不同类别(时尚/包装/地标等)嵌入到不同的离散空间中,但这些方法效果都不理想。
对我而言,motono0223的基线方法效果最好。即:冻结的CLIP + Arcface头。
关于类别的下采样
- 64维的嵌入空间并不大,因此我调整了训练时的类别数量。
- 从Products10k/GLR中选取4000个类别进行训练对我来说效果最好。

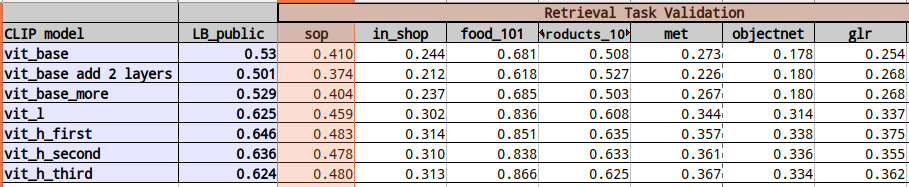
难以建立良好的CV-LB相关性
- 我配置了6种不同的检索任务,包括Products10k/GLR/Stanford Online Products/DeepFashion/MET/Food-101/ObjectNet,但无法找到清晰的CV(交叉验证)与LB(排行榜)之间的相关性。
- 当仅使用Products10k/GLR进行训练时,Stanford Online Products(柜子/沙发/椅子)的检索设置与LB相对相关。但这仍然不是完美的。
冻结CLIP
- 解冻CLIP进行微调对我来说不起作用。降低学习率虽然可行,但冻结参数配合高学习率的效果更好。
- 微调其他主干网络(如ImageNet预训练模型)的效果不佳。
- 在冻结的CLIP上添加更多的Transformer层效果也不好。