第14名方案 – 使用LGBM知识蒸馏的NN Transformer
感谢 Amex 分享数据并举办这场有趣的表格数据竞赛。感谢 Kaggle 平台。感谢各位 Kagglers 分享许多有帮助的讨论和 Notebooks。特别感谢 Raddar 和 Martin 的贡献。
方案概述
我的解决方案是 LGBM 和 NN Transformer 的 50%/50% 融合模型。LGBM 基于 Martin 分享的优秀的公开 LGBM 代码,NN Transformer 基于我公开的 Transformer 代码。
核心技巧在于如何训练 Transformer。我们首先利用训练好的 LGBM 进行知识蒸馏,然后使用训练集目标进行微调。此外,训练集和测试集数据都被用于知识蒸馏,这有助于 Transformer 学习测试集的数据分布。
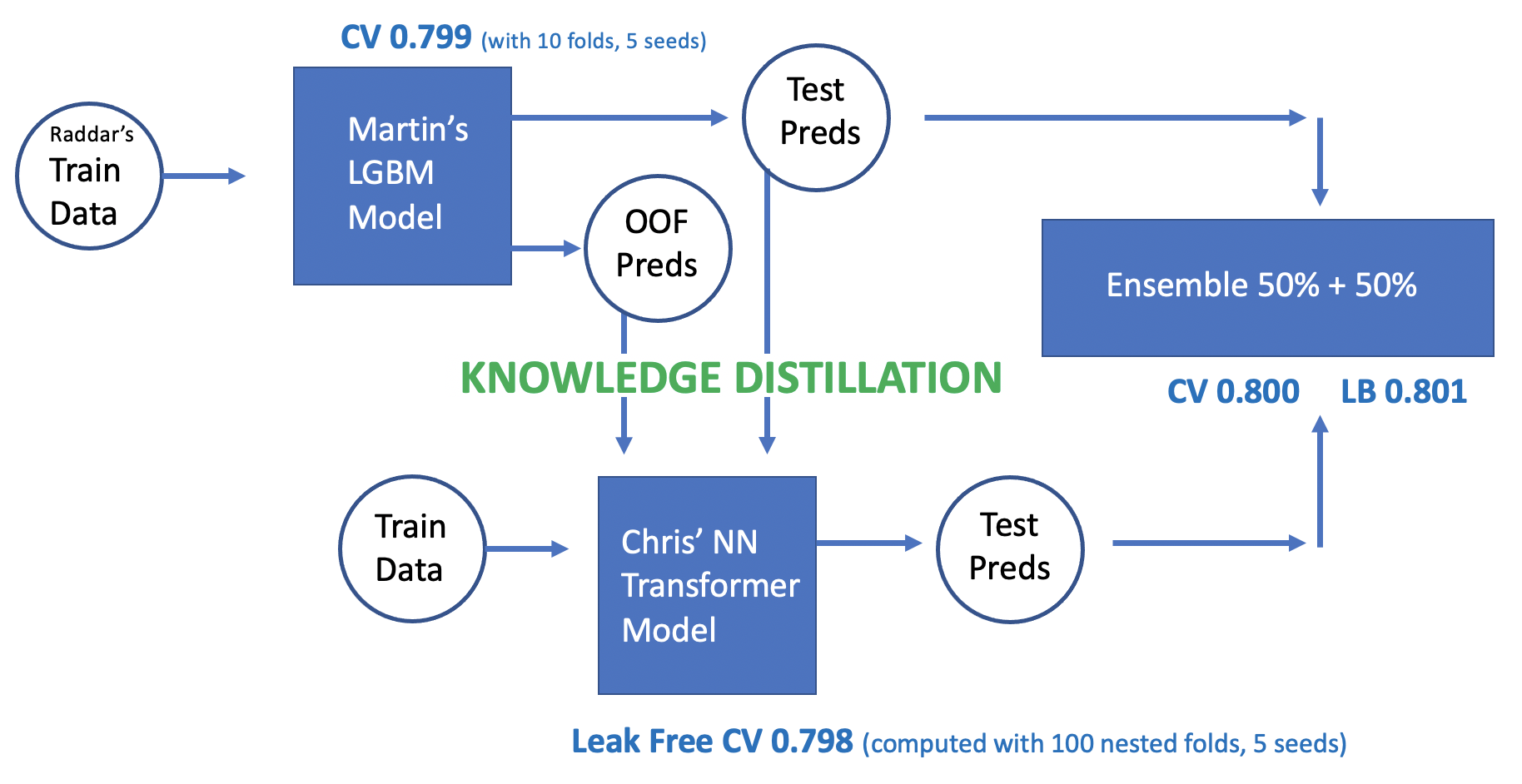
NN Transformer 训练
我公开的 Notebook 中的 Transformer 包含 2 层和跳跃连接(为了使训练更容易)。当使用知识蒸馏时,我们可以成功地训练更深的 Transformer。我的最终方案使用了 4 层 Transformer 且没有跳跃连接。我们还在 Transformer 块之后和最终分类层之前添加了一个 GRU 层。
训练使用 4 个周期的余弦学习率调度。在第一个冷启动余弦周期中,我们使用 LGBM 的 OOF 预测和 LGBM 的测试预测的拼接行来预训练(即知识蒸馏)Transformer,并将概率保持在 0 和 1 之间(即软标签)。在第二个余弦周期中,我们使用热启动,降低学习率并使用硬标签(0 或 1,即真实目标)进行训练。对于第三和第四个周期,我们重复第一和第二个周期的过程。
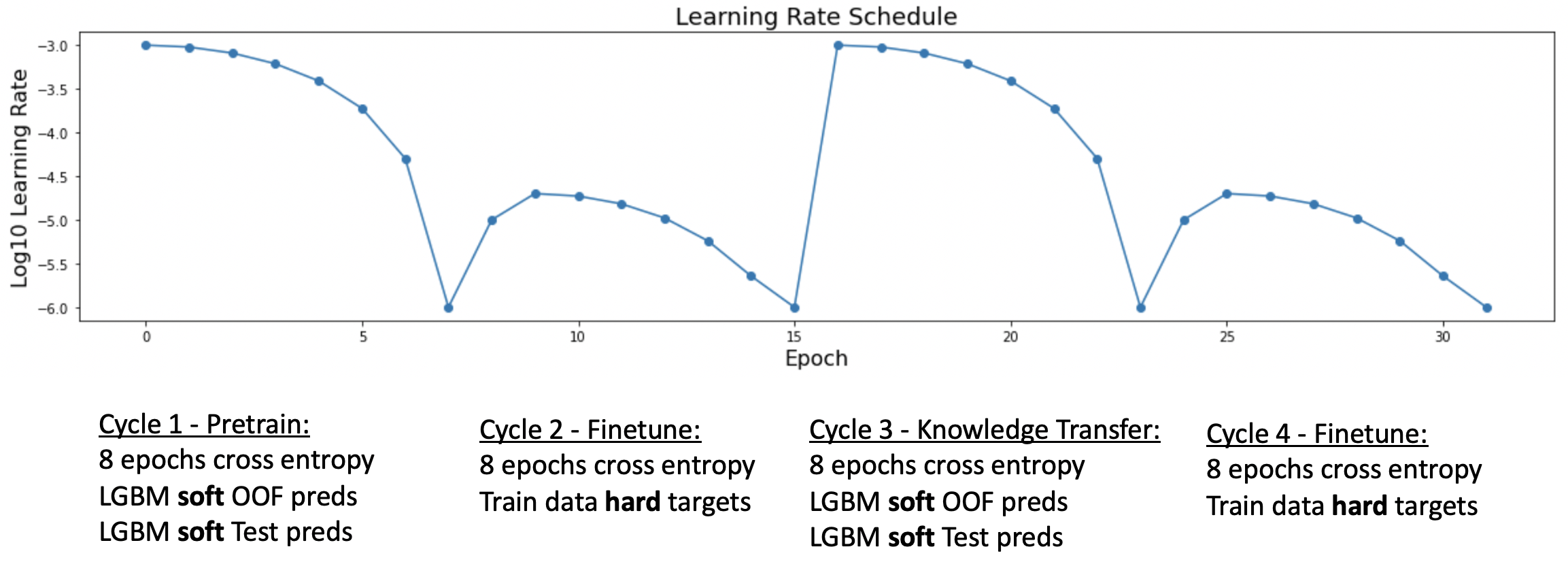
模型性能
当从我们的两个模型创建 submission.csv 文件时,我们可以使用正常的 K-Fold LGBM OOF 预测和正常的 LGBM 测试预测。因此,生成提交文件既快速又简单。此外,我们对每个模型平均 5 个随机种子(以及轻微的模型变体)以提高性能。
为了调整我们的两个模型并计算最佳超参数,我们需要一个无泄漏的可靠 CV 分数。无泄漏 CV 分数是使用 嵌套 K-Fold(Nested K-Fold)CV 创建的。我们将 10 个外层折中的每一个划分为 10 个内层折。然后我们使用 GBT 训练 100 个模型。然后 10 个外层折中的每一个都有其独特的 OOF 预测和独特的测试预测。这些个性化的 OOF 和测试预测是仅使用相应外层折训练数据中的训练目标创建的。
在计算无泄漏 CV 分数时,我们发现我们的 NN Transformer 具有 CV 0.798 / LB 0.799,我们的 LGBM 具有 CV 0.799 / LB 0.799,而我们的 50%/50% 融合模型具有 CV 0.800 / LB 0.801。
快速实验
快速实验是使用 GPU 完成的。感谢 Nvidia 为我提供本次比赛的算力资源。实验使用 4xV100 32GB 进行加速。
特征工程使用 RAPIDS cuDF 进行探索,它在 GPU 上执行 dataframe groupby 聚合等操作的速度比使用 CPU 快 10-100 倍。许多 GBT 实验模型使用快速 GPU XGB 进行训练和评估。使用 1xV100 GPU,XGB 可以在仅 2 小时内在完整数据上训练 100 个模型用于嵌套 10 in 10 K-Fold(即 100 个模型)。
特征选择同时使用了 XGB 特征重要性和置换重要性。使用 RAPIDS FIL,我们可以极快地执行置换重要性,即对 10 个折中的每一个将每个特征列随机打乱 10 次(并平均 100 个结果)!
对于数千个特征列中的每一个,我们推断 100 次。这总共涉及数十万次模型推断,其中每个