第4名解决方案
大家好!
首先,我要感谢主办方举办了这场非常有趣且充满挑战的比赛。同时,也要祝贺所有参赛者:最后几天的悬念实在是太大了,我简直不敢相信现在一切都结束了。我在凌晨3点写下这篇文章,既感激又释然!此外,我也想对那些以微弱差距错失奖牌的选手说几句宽慰的话,因为接受这个结果可能很难。你们做得非常棒,我相信下次你们会做得更好。努力总会有回报。
最后,感谢我有才华且勤奋的队友 @ymatioun 和 @theoviel,我很享受与他们一起工作和学习的过程。
概览
我们的解决方案包含以下几个步骤:
- 清洗数据,主要是名称。 移除特殊字符和空格,应用 unidecode 统一非拉丁语言,转换为小写文本……
- 创建一些有意义的特征。 这需要预先做一些工作,例如创建相似类别的组(如“gyms”、“gyms or fitness centers”、“gymnastics gyms”、“gym pools”……),并计算每组的平均距离,以便我们找到至少 50%、75%、90% 和 95% 的真实匹配项。如果名称、城市和州指的是同一个地点,我们也会将它们分组。你可以查看这里的 3 个实用笔记本,了解我们的具体做法。
- 寻找候选匹配对。 为此,我们使用了不同的思路:考虑近邻;名称相似性;名称中包含相同的词;分组类别相等;(清洗后的)电话号码相等;地址相同;TF-IDF(特别是针对机场和印度地区);等等。
- 配对匹配。 此时,由于配对数量巨大,我们不得不使用 2 个模型来避免内存错误。第一个模型是一个 5 折 LGBM,仅使用了距离或名称相似度等少量特征以避免问题。其目标是删除所有不相关的配对(阈值 < 0.007)。然后,我们计算了 200 多个特征来训练第二个 LGBM(20 折!),由它给出最终结果。这两个模型都在整个训练集(110 万行)上进行训练,由于内存限制,这在 Kaggle 上是无法实现的,必须在其他地方进行。
- 后处理。 我们尝试了很多想法(基于图的方法;第三个 LGBM 模型,将第二个模型的分数以及上下文特征(如一个地点的高分邻居数量)作为输入)。最后,关键的想法是根据我们要合并的组的大小来调整阈值。事实上,合并 2 个地点与合并 2 个各包含 10 个地点的组,其影响(和概率)是不一样的。
让我们的分数从 0.939(第15名)提升到 0.957(第4名)的“魔法”
私有测试集中的某些行与训练集中的行非常相似。谢天谢地,我们在比赛的最后一天发现了这一点。因此,我们记录了训练集中所有匹配的 ID,如果它们出现在测试集中,我们会自动匹配它们。实际上,我们通过以下键来建立训练集和测试集之间的联系:cleaned_name + round(latitude, 5) + round(longitude, 5)。
在我看来,如果训练集和测试集的条目是截然不同的,对比赛来说会更好。
编辑:我们没有利用这个泄露来删除假阳性,但如果这样做肯定会有很大的提升。
流程图
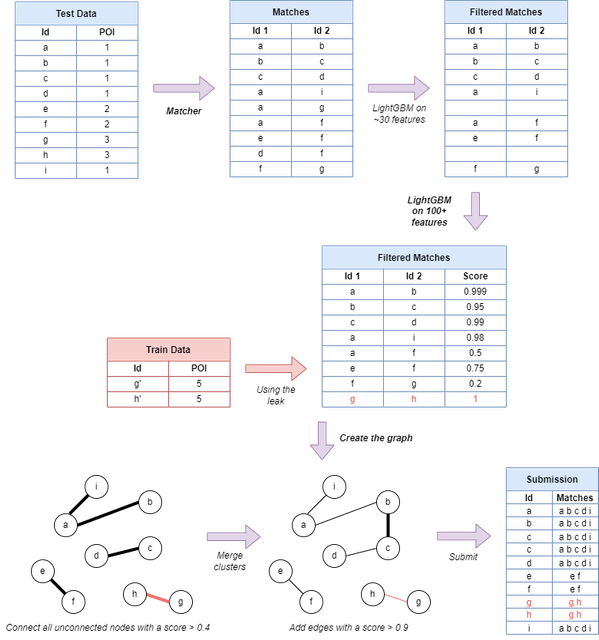
感谢 @theoviel 提供的精彩插图。
效果不佳的尝试
这部分内容会很长,但主要包括:
- Tf-idf 不太有用: 增加的真实匹配项不到 3%,而且增加了一些很难捕捉的假阳性(因为名称定义上就是相似的)。
- 外语翻译: 与 unidecode 相比并不是颠覆性的改变(除了 pykakasi 对日语翻译效果更好)。
- (离线)反向地理编码器: 没那么有用,主要是因为主要特征首先是基于名称/纬度/经度,而不是城市/州。
- 模型堆叠: 我们尝试添加 XGBoost 和 Catboost,但最终,与付出的努力相比,收益非常微薄。
代码
我们的代码可在