第4名方案:Deberta模型与后处理
首先,感谢竞赛主办方举办这次比赛,也感谢优秀的队友( @takoihiraokazu, @shuheigoda, @copasta )。
同样感谢社区在 Notebook 和 Discussion 中分享的许多想法。
摘要
我们集成了4个 token 分类模型,针对每个 case_num 设定了阈值,并进行了后处理。
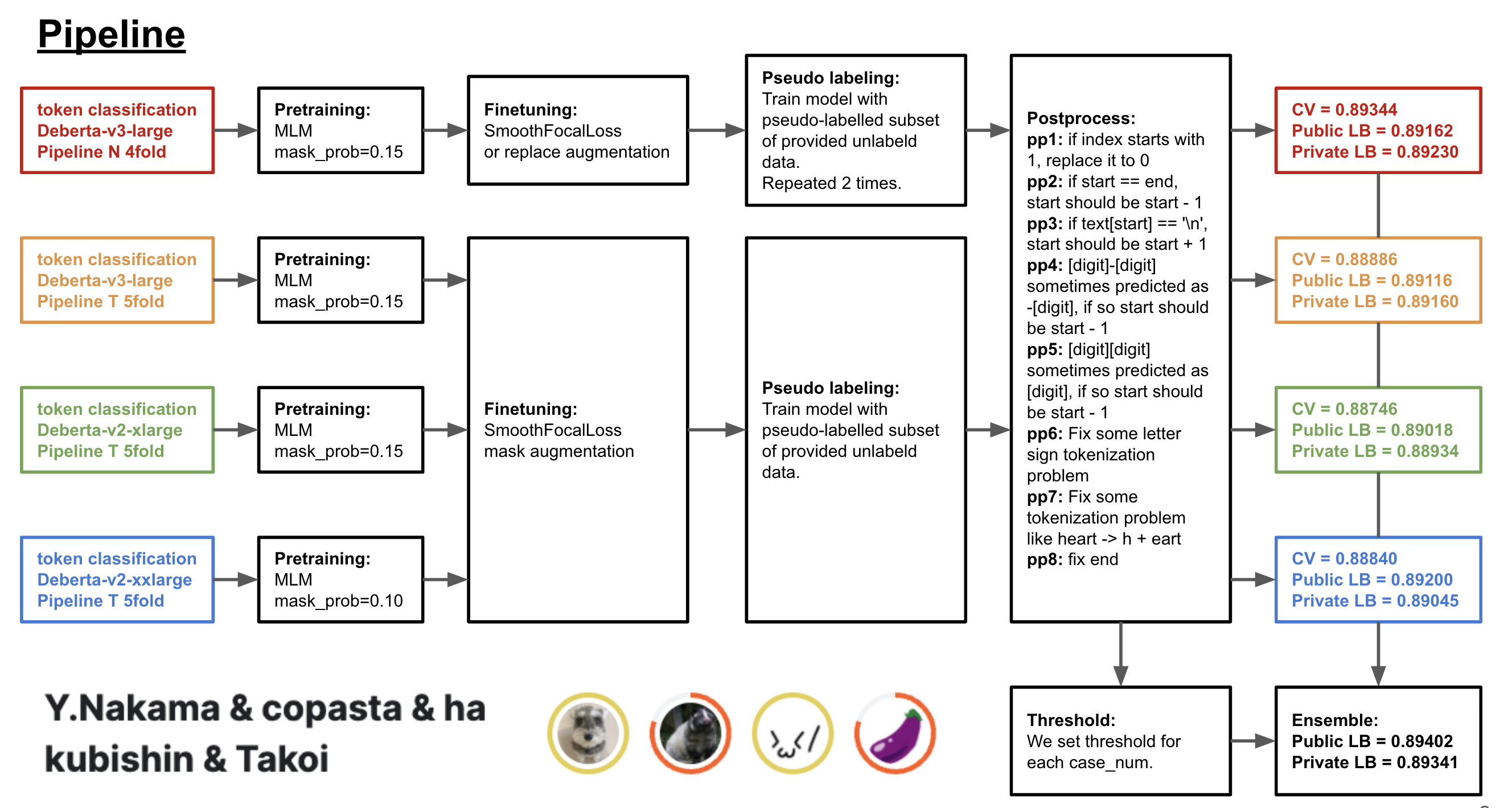
模型
我们训练了以下4个 token 分类模型,并将其用于最终提交。
- token 分类 Deberta-v3-large 4折交叉验证
- MLM(0.15)
- 微调 (finetune)
- SmoothFocalLoss
- 或对特征文本进行替换增强
- 文本小写化
- ~~3次伪标签~~
- 2次伪标签(这是用于最终提交的版本,但在 Private LB 上4次伪标签效果更好)
- Public LB: 0.891 (含后处理)
- Private LB: 0.892 (含后处理)
- token 分类 Deberta-v3-large 5折交叉验证
- MLM(0.15)
- 微调 (finetune)
- SmoothFocalLoss
- mask 增强
- 伪标签
- Public LB: 0.891 (含后处理)
- token 分类 Deberta-v2-xlarge 5折交叉验证
- MLM(0.15)
- 微调 (finetune)
- SmoothFocalLoss
- mask 增强
- 伪标签
- Public LB: 0.890 (含后处理)
- token 分类 Deberta-v2-xxlarge 4折交叉验证
- MLM(0.10)
- 微调 (finetune)
- SmoothFocalLoss
- mask 增强
- 伪标签 (Deberta-v2-xlarge)
- Public LB: 0.892 (含后处理, 5折)
我们还训练了1个字符分类模型,3个 token 分类模型和1个字符分类模型的集成在 Private LB 上表现最好,但未能选为最终提交。
- 字符分类 Deberta-v3-large 4折交叉验证
- MLM(0.15)
- 微调 (finetune)
- BCELoss
- GRU Head(4 层)
- 伪标签
- 字符分类 Deberta-v3-large 4折
- 字符分类 Deberta-xlarge 4折
- 字符分类 Deberta-large 4折
- Public LB: 0.890 (含后处理)
集成
基于字符概率的4个模型加权融合。
阈值
我们为每个 case_num 设定了阈值。
后处理
这是我们的后处理代码。
def postprocess(texts, preds):
from nltk.tokenize import word_tokenize
preds_pp = preds.copy()
tk0 = tqdm(range(len(preds_pp)), total=len(preds_pp))
for raw_idx in tk0:
pred = preds[raw_idx]
text = texts[raw_idx]
if len(pred