第19名 HappyWhale 解决方案
我们非常高兴地展示我们的 HappyWhale 第19名解决方案。我们的团队由 @ragnar123、@mpware、@bolkonsky 组成。能与这些 Kaggle 特级大师一起工作并向他们学习是一种荣幸。感谢 Kaggle、Ted Cheeseman、合作者以及 Happywhale 的所有人举办了这场精彩的比赛!
摘要
- 大型主干网络,如 EffNetB7,大图像尺寸,如 768x768
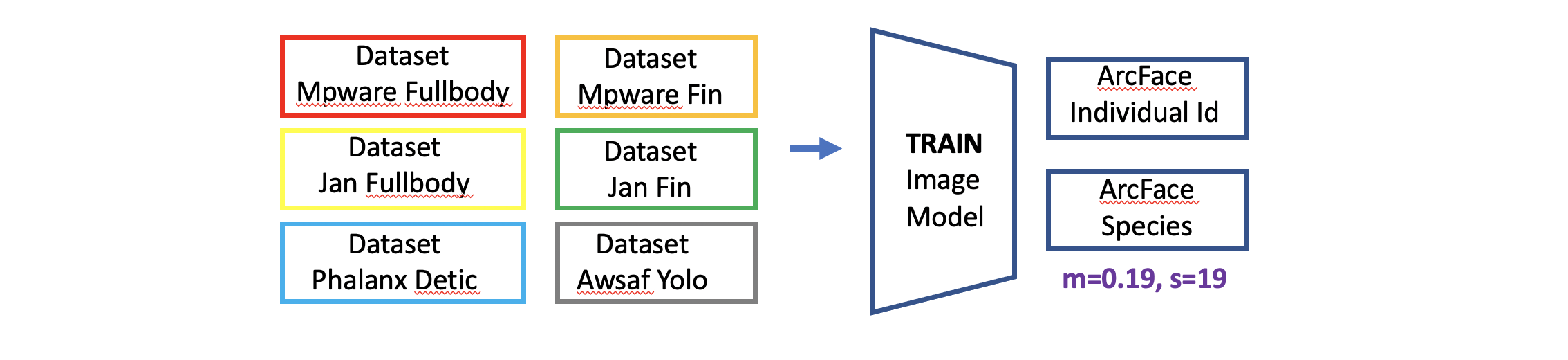
- 两个 ArcFace 模块。一个用于物种,一个用于 individual_id,参数均为 m=0.19, s=19
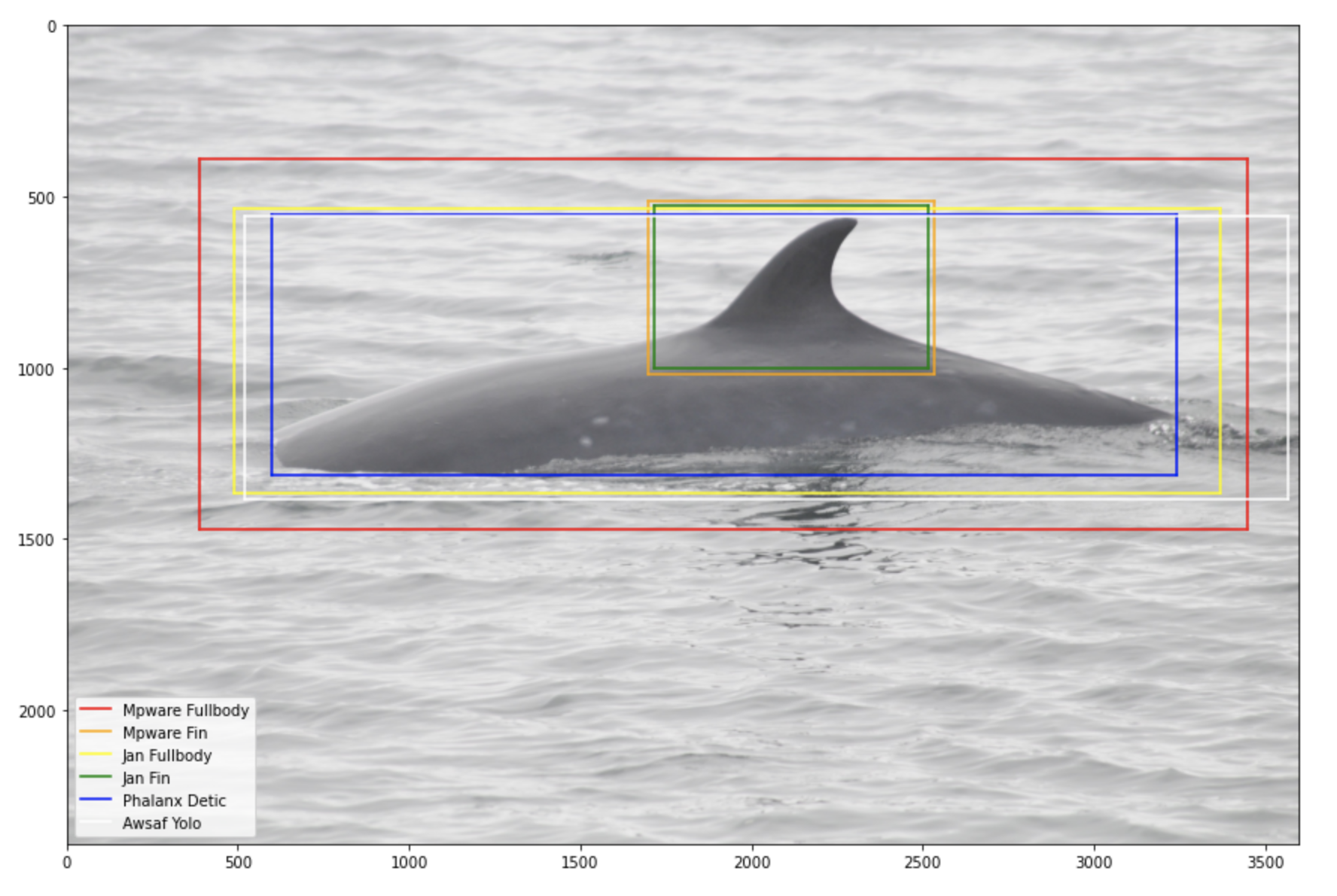
- 六个数据集:Mpware fullbody、Mpware fin、Jan fullbody、Jan fin、Phalanx detic、Awsaf yolo
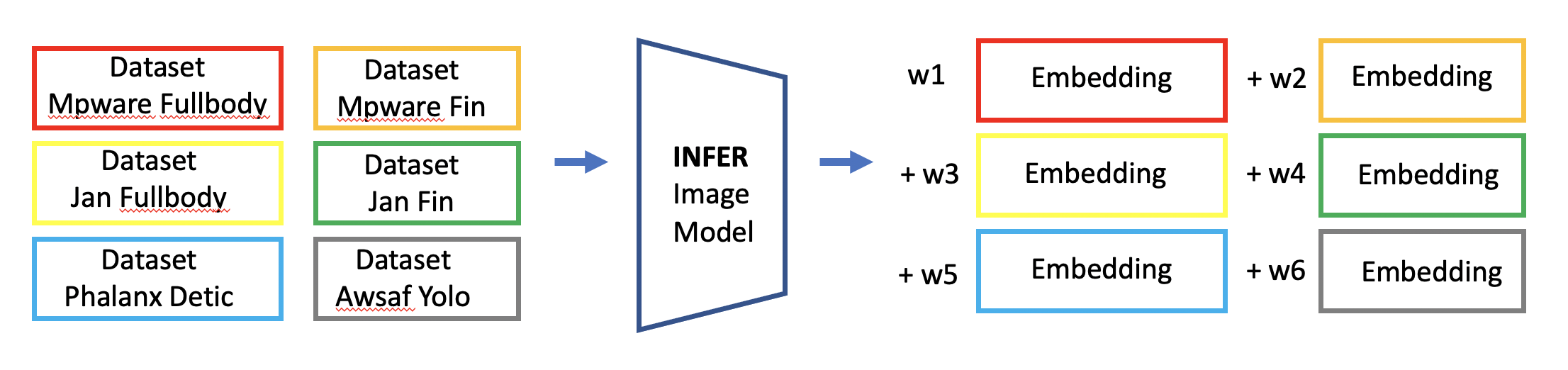
- 对所有六个数据集进行推理,并对六个嵌入进行贝叶斯优化加权平均
- 8折交叉验证 (8 fold CV)。在 CV 上调整
new_individual阈值。最佳单模型 CV 0.865 LB 0.859
数据集
我们非常希望仅使用原始图像来训练模型,并让模型学会将注意力集中在背鳍和/或全身。然而,图像非常大,比如 2500x3500。因此,我们使用了六个数据集,其中图像的重要部分被裁剪,然后调整为 512x512、640x640 或 768x768。

模型
- 图像尺寸:512x512, 640x640, 768x768
- EffNetV1-B5, EffNetV1-B6, EffNetV1-B7
- EffNetV2-L, EffNetV2-XL
- ConvNext-L
- Batchsize = 64
- 使用 Nvidia 8xV100 GPU 和 CoLab TPU 进行 TensorFlow 训练
训练 - 一个模型适用所有数据集
我们在所有 6 个数据集上训练一个模型,进行 20 个 epoch 的指数学习率衰减,包含 5 个 epoch 的预热。因此,模型会看到每张训练图像 120 次。我们还使用了数据增强和两个 ArcFace 头。
推理 - 六个嵌入的贝叶斯优化平均
我们分别在每个数据集上对模型进行推理,并为每张训练和测试图像获取六个嵌入。接下来,我们在 CV 分数上使用贝叶斯优化,找到这 6 个嵌入的最佳加权平均值,用于 KNN 匹配。
集成
我们最佳的单模型 8 折 CV 为 0.866,LB 为 0.859。我们训练了大约 12 个不同的模型,然后通过对每个折模型的 5 个预测进行投票集成,集成了这 96 = 12 x 8 个折模型。我们的集成结果是 LB 0.868。
如何改进
在阅读了其他顶级团队的获胜方案后,我们认为提升模型 LB 的下一步是对测试图像进行伪标记,然后使用训练数据和伪标记的测试数据重新训练模型。我相信这可以使 LB 提升多达 +0.010 到 +0.020 !
更新
比赛结束后,我使用伪标签重新训练了我们 12 个集成模型中的两个。公共 LB 提升 +0.009,私有 LB 提升 +0.016。这证实了伪标记在本次比赛中非常强大。
仅仅将伪标记添加到我们 12 个集成模型中的两个,就将我们的最终排名提升到了金牌区!我想如果我们将多轮伪标记添加到所有集成模型中,我们可以进一步攀升至金牌区!