第11名解决方案 - Team COTS
我们很高兴能在榜单震动中“幸存”下来,事实证明相信交叉验证(CV)确实是这里的关键!这是一个伟大的团队努力,与 @anjum48, @yamsam, @imeintanis 和 @markunys 一起合作是一段很棒的旅程。凭借这枚金牌,我们中有3人(@imeintanis, @markunys 和我)将成为竞赛大师,这真是太美妙了 😆
总的来说,观察带有模型预测的视频片段非常重要,这有助于我们发现改进领域,如跟踪、集成和添加新数据。以下是我们解决方案的一些关键点:
最佳私有LB模型流程
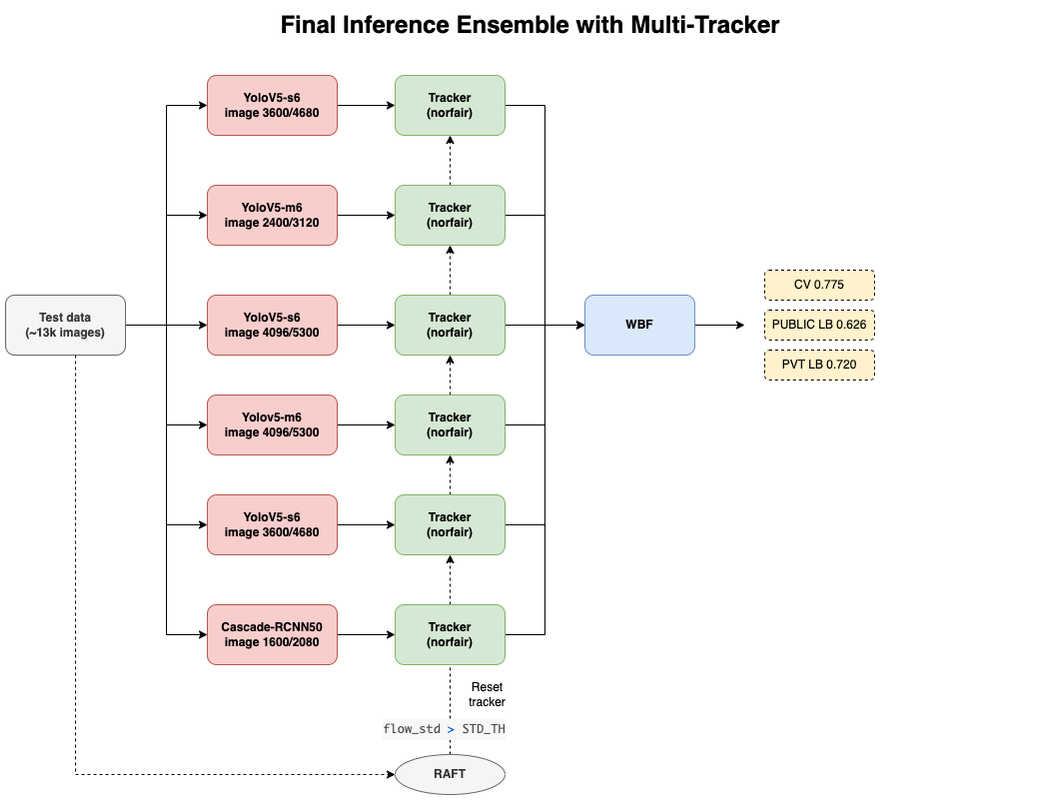
1. 最终提交模型 (2个最佳CV模型, 1个最佳CV & LB模型, 1个最佳LB模型)
- 5个YOLO WBF + 1个Cascade RCNN WBF: 仅使用那些与YOLO预测IOU >= 0.3的RCNN预测,以修正YOLO的边界框)。 CV 775 公开LB 626 私有LB 720
- 7个YOLO WBF: CV 781 公开LB 628 私有LB 719
- 4个YOLO WBF + 1个最佳LB模型 WBF: 4个YOLO WBF CV 771, 公开LB 653, 私有LB 706
- 2个最佳LB模型 WBF: 不确定CV分数, 公开LB 718, 私有LB 666。
2. 集成与最终提交
最终提交 notebook
- 模型推理使用1.3倍训练尺寸(yolov5中的多尺度推理)。
- 对每个单独模型使用低置信度阈值,在WBF之后使用高置信度阈值(与WBF前使用高阈值和WBF后使用低阈值相比,CV提高约0.005)。
- 模型挑选标准:数据的多样性(是否使用CLAHE预处理)、训练方法(1阶段,2阶段)和模型(yolov5或rcnn)。
3. CV方案
- 手动挑选代表20%数据的序列(4707张图像)——在代表性和数据大小之间取得平衡。这导致最终CV和私有LB的相关性达到90%。
- 挑选标准:每帧的COTS数量 + 根据f2分数判断预测难度(我们不想挑选太容易或太难预测的序列子集)+ 跨不同视频的序列。
- 由于计算限制未使用5折交叉验证。未使用video_id,因为它会占用太多数据。
4. 训练
- 使用所有标注图像 + 约5%的背景图像进行训练(这些背景图像是从高FP图像中挑选或随机挑选的,这使CV提高了约0.005)。
- 使用CV选择超参数和最佳轮数 --> 使用所有数据进行提交训练。
- YOLOv5: 默认超参数(mixup, mosaic, flip, HSV, translate, scale),但学习率为0.001,使用Adam优化器。
- 1阶段模型:使用GT数据训练20~40个epoch,batch size为4,训练图像尺寸2400~3600(取决于模型大小)。
- 2阶段模型:像1阶段模型一样使用原始数据训练,然后使用GT数据以0.0001的学习率训练10个epoch。
- 一些模型还使用了
--label-smoothing 0.2以加快收敛并提高CV分数。
- Cascade-RCNN: mmdetection框架,增强包括flip, rotate, CLAHE, HueSaturation, RandomBrightnessContrast, RandomSizedBBoxSafeCrop。
5. 后处理
- 在WBF之前对每个模型使用跟踪器(与在WBF之后使用跟踪器相比,CV提高约0.01)。
- 对于跟踪器,我们过滤掉了那些位于边缘的预测,因为它们通常是FP(这