第41名方案
恭喜所有的获奖者。
我在这次比赛中学到了很多关于NLP的知识。谢谢大家!
一旦排名确认,我就成为竞赛大师了!🙂
概览
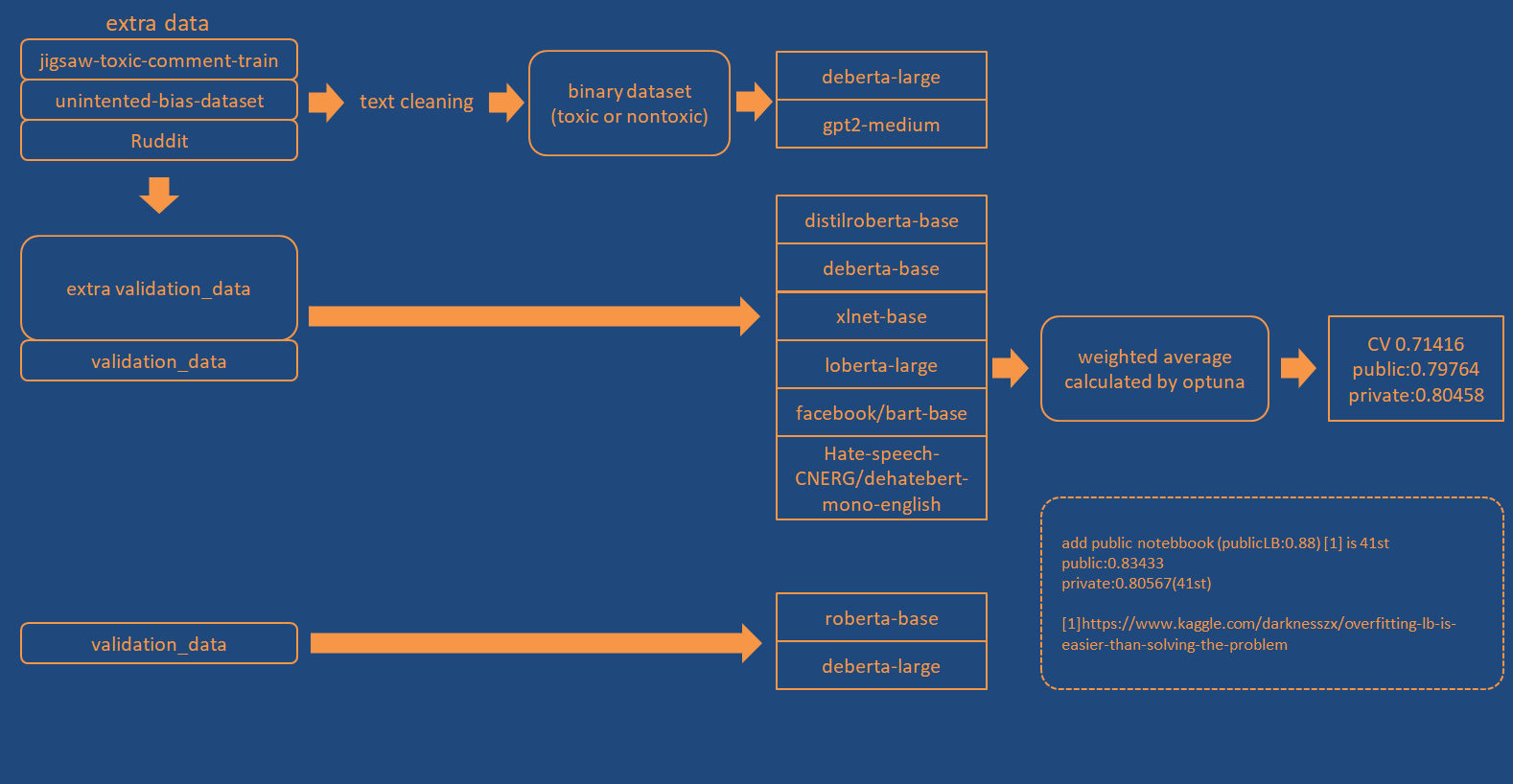
数据
我创建了两种类型的额外数据。
- 二分类标签数据(有毒或无毒)。
- more_toxic(更有毒)、less_toxic(较无毒)数据。
交叉验证策略 (CV strategy)
模型
| 模型 | CV分数 | 损失函数 |
|---|---|---|
| microsoft/deberta-large | 0.7032 | BCE |
| gpt2-medium | 0.6993 | BCE |
| distilroberta-base | 0.7012 | MarginRankingLoss |
| microsoft/deberta-base | 0.7043 | MarginRankingLoss |
| xlnet-base-cased | 0.6997 | MarginRankingLoss |
| robelta-large | 0.702 | MarginRankingLoss |
| facebook/bart-base | 0.7027 | MarginRankingLoss |
| Hate-speech-CNERG/dehatebert-mono-english | 0.6769 | MarginRankingLoss |
| roberta-base | 0.7017 | MarginRankingLoss |
| microsoft/deberta-large | 0.7014 | MarginRankingLoss |
较大的模型通常具有更好的CV分数。
max_len : 256
optimizer : AdamW
lr : 1e-5
weight_decay : 0.1
epochs : 1~3
scheduler : get_linear_schedule_with_warmup
集成
我使用了Optuna。具体描述如下:
cols = ['less_toxic_pred', 'more_toxic_pred']
oof = []
oof.append(pd.read_csv('../input/jigsaw4-model2/bi003_deberta-large/oof.csv',usecols=cols).values)
oof.append(pd.read_csv('../input/jigsaw4-model1/exp008_roberta-base/oof.csv',usecols=cols).values)
def calc_score(weight):
pred = np.zeros([n_data,2])
for p, w in zip(oof,weight):
pred += p*w
score = (pred[:,0] < pred[:,1]).sum()/pred.shape[0]
return score
class Objective:
def __init__(self, n_models):
self.n_models = n_models
def __call__(self, trial):
weight = [trial.suggest_uniform('weight' + str(n), 0, 1) for n in range(self.n_models)]
return calc_score(weight)
max_iter = 1800
SEED = 29
objective = Objective(n_models)
sampler = optuna.samplers.TPESampler(seed=SEED)
study = optuna.create_study(sampler = sampler,direction='maximize')
study.optimize(objective, n_trials = max_iter, n_jobs = -1)