第4名方案 (Team Durrett): 基于多智能体的模仿学习
首先,我们要感谢组织者和其他参赛者。通过这次比赛,我们学到了很多,比如强化学习和CNN架构。唯一的遗憾是我们没能成功运用强化学习(RL)。另一方面,如果RL更容易利用的话,由于我们知识和技能的不足,我们可能无法取得这么好的成绩。幸运的是,我们将能够从成功使用RL的顶尖团队那里学习,因此我们期待在下一次比赛中利用这次的经验。
摘要
像许多其他参赛者一样,我们的最终方案是利用前7名智能体进行模仿学习,使用了由 Sazuma的Notebook 分享的几乎相同的网络架构。
由于直接混合来自不同智能体的所有数据进行网络训练可能并不理想,我们准备了与要学习的智能体数量相同的最后一层全连接层(FC-layers),而CNN架构则是共享的。
在推理阶段,我们只使用了由排名第一的智能体数据训练出来的FC层。
模型
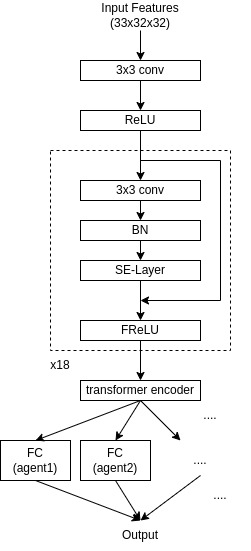
- 通道大小:384
- 所有单位和所有城市地砖的动作通过一次前向传播输出。
我们注意到原始Notebook中网络的表征能力不足,因此插入了FReLU、SE-Layer和Transformer编码器。此外,我们尽可能增加了层数和参数量。在我们的模型中,每一回合只执行一次前向传播,因此我们可以节省推理时间并最大化网络的表征能力(平均而言,除第一回合可能需要加载模型参数外,每回合大约需要1.5秒)。在训练误差、验证误差和自我对弈结果方面,我们观察到了这些网络架构改进带来的提升。
训练
- 优化器:AdamW (lr=1e-03, weight_decay=1e-05)
- 轮数:100
- 学习率调度器:在第50和第80个epoch时将学习率降低0.1倍。
- 损失函数:加权Softmax交叉熵(仅降低“移动到中心”动作的权重)
- 数据增强:4个方向旋转
值得一提的是,训练的轮数起着重要作用。这大大增加了训练时间(最终模型大约需要1周),但通过自我对弈和LB(排行榜)结果,我们观察到经过更多轮数训练的模型表现更好。
动作
我们的动作模型与其他方案没有太大区别。
工人的动作
- 移动 x 4
- 移动到中心
- 建造城市
- 转移 x 4
城市地砖的动作
- 研究
- 建造工人
- 什么都不做
网络解释器
直接使用网络的输出作为智能体的输出并没有给出令人满意的性能。因此,我们添加了一些规则来解释网络的输出。以下是一些例子:
- 禁止工人移动到同一个格子(城市地砖除外)。
- 禁止城市地砖内的工人移动到该城市地砖的同一个格子。(如果允许这种情况,多个工人会持续执行相同的动作。)
- 关于城市地砖的动作,“什么都不做”的比例非常大,这阻碍了正确模仿原始智能体。因此,在允许建造工人的情况下,根据输出分数优先处理“建造工人”。
我们通过数千次自我对弈评估了这些规则。
代码
我们在 这里 发布了最终模型的代码。
数据集
最终方案的数据集已上传至 这里。