第6名方案 - 我们的Jaccard得分随时间变化的可视化
首先,我要感谢 Kaggle 和竞赛主办方举办这个有趣的 NLP 挑战赛。我喜欢这种趋势,我们看到越来越多的 NLP 竞赛。我需要短暂休息一下,但肯定会参加 Jigsaw 竞赛 😉。
我们在比赛初期就意识到本地的 CV(交叉验证)分数并没有太大的意义。我们决定在竞赛中首次将重心放在公共排行榜上,而不是 CV 分数,但始终保持模型的多样性以避免剧烈波动。多样性也是我们在 CommonLit 挑战赛中获得金牌的关键。像所有团队一样,我们从 XLM Roberta Large 开始。我们将分数推到了 0.785,但没能进一步提高 (1)。
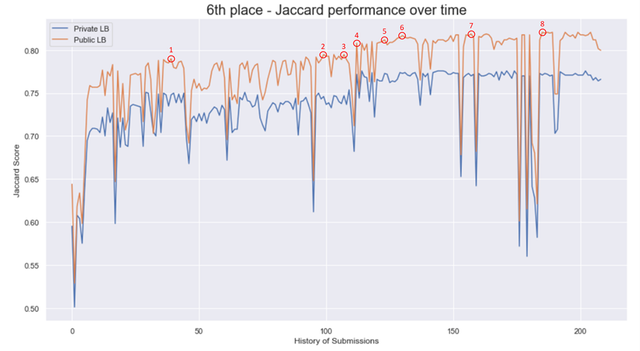
在那之后,我们显然取得了突破。我们成功集成了不同架构的模型。我们将 logits 映射到字符级别,以结合不同分词器大小的输出(链接在我的帖子末尾的笔记本中)。
随后,我们将 Roberta Large 与 Muril Base (0.732) 进行了集成,得分达到了 0.792 (2)。我们实施了 logits 的归一化以考虑不同的尺度,得分达到了 0.795 (3)。
后来,论坛上发布了 Muril Large 的链接。我们在微调它时遇到了困难,但最终创建了一个公共分数为 0.784 的模型。我们将它与我们的 Roberta Large 集成,分数大幅跃升至 0.808 (4)。一个有趣的旁注是,这个模型在私有排行榜上的得分已经达到了 0.776。
现在我们添加了 Rembert(0.774 单模型分数)(5) 和 XLM Info Large (6)。在比赛的最后几天,我们花了很多时间微调集成的权重 (7)。我们还在最后添加了 Wechsel 模型,占比很小 (8),最终达到了 0.821 的公共排行榜分数。
我们的最终集成模型权重如下:
- Rembert Large - 16.8%
- Muril Large - 29.4%
- Roberta Large - 44.1%
- Xlm Info Large - 5.7%
- Wechsel - 4%
我对结果很满意,尽管我们最终跌出了前 5 名。由于数据量小,CV 和排行榜之间存在巨大差距,关注公共排行榜感觉是正确的。我预计私有排行榜和公共排行榜之间的相关性要比私有排行榜和 CV 之间的相关性高得多。我检查了我们的提交记录,感觉被证明是正确的:
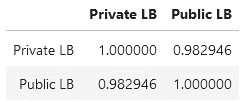
很高兴能和大家一起解决这个问题。下次我会尝试在论坛中更活跃,祝大家一切顺利。
感谢我出色的队友 @chamecall