前言
在撰写我们的解决方案之前,我们非常感谢 Google Brain 和 Kaggle 主办这次比赛,并祝贺所有人。同时,我非常享受与我的 UPSTAGE 团队成员一起参加这次比赛。感谢许多分享 notebook 并留下讨论的 Kaggler,我们才能取得好的成绩。在解释我们要做什么之前,我先写一个总结。如果有不清楚的地方,请参考正文或留下评论。
让我们开始我们的故事吧。
摘要
- 验证策略
- 使用 type_rc 作为 y 进行分层 k 折交叉验证
- 模型:我们使用了 Conv1d 和 LSTM 的组合
- 架构:Conv1d + 堆叠 LSTM (Stacked LSTM)
- 优化器:AdamW
- 调度器:余弦退火
- 特征:我们使用了 8 个特征
- 原始特征:u_in, u_out, R (one-hot), C (one-hot)
- 工程特征:u_in_min, u_in_diff, inhaled_air, time_diff
- 数据增强:我们使用了三种类型的数据增强
- 掩码:随机掩盖 R 或 C
- 洗牌:随机打乱我们的序列
- 混合:选择两个序列并进行混合
- 损失函数:我们使用了多任务 MAE 损失
- 压力的 MAE
- 压力的差值
- 集成:我们使用了迭代伪标签和种子集成
- 使用中位数的种子集成
- 第一次伪标签
- 第二次伪标签
正文
我将按照以下六个结构描述我们的解决方案:验证策略、模型、特征、数据增强、损失函数和集成。
验证策略
比赛中最重要的什么?依个人拙见,是为了避免比赛结束时出现排名剧烈波动,因此需要设计良好的验证集来避免这种情况。虽然验证集对于本次比赛不是最重要的,但这就是为什么我在比赛开始时首先关注验证策略的原因。
通过这篇讨论(感谢 @cdeotte),我们知道 R 和 C 的类型在本次比赛中非常重要,我们为每个折叠制作了具有相同 R 和 C 比例的验证集。
详细的伪代码如下。
cols = ['breath_id', 'R', 'C']
meta_df = train_df.groupby('breath_id')[cols].head(1)
meta_df['RC'] = meta_df['R'] + '_' + meta_df['C']
meta_df['fold'] = -1
kf = StratifiedKFold(12, random_state=seed, shuffle=True)
for fold, (_, val_idx) in enumerate(kf.split(meta_df, meta_df['RC'])):
meta_df.loc[val_idx, 'fold'] = int(fold) 通过这种方式,我们能够创建与测试数据高度相关的验证集,但我认为即使只使用普通的 KFold 也能创建出好的验证集。
模型
设置好验证集后,我们专注于仅使用原始特征来提升模型性能。
由于 Limerobot(Transformer 魔法师)在我们的团队中,一些 Kaggler 预期我们会使用 Transformer,但我们只使用了简单的 LSTM 模型(感谢 @tenffe 的 notebook)。
详细的模型架构如下。
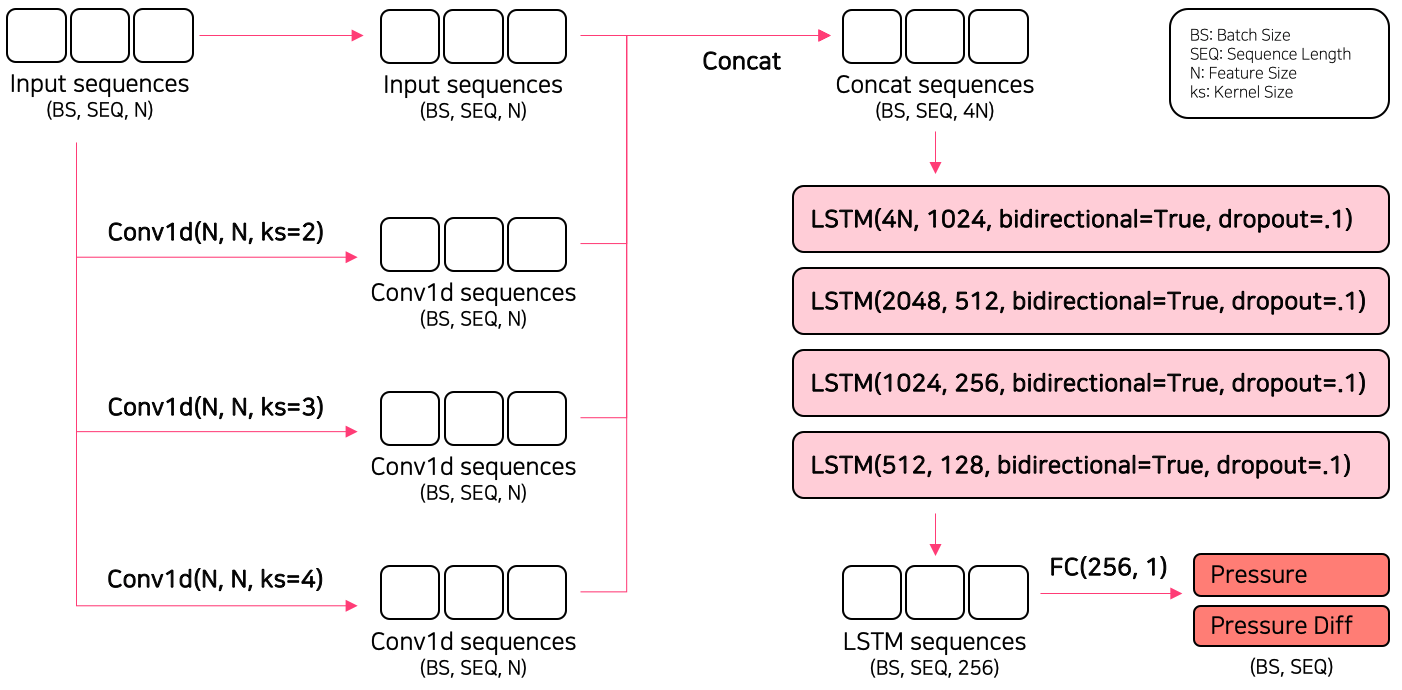
我们针对 PyTorch 和 TensorFlow 库相关的模型进行了试错。最初,大多数高分公开 notebook 都是用 TensorFlow 实现的,我们尝试将其移植到 PyTorch 版本。然而,由于 TensorFlow 和 PyTorch 在模型初始化方法上的差异,PyTorch 的得分较低(感谢 @junkoda 分享的 notebook)。像 TensorFlow 这样的模型初始化方法使我们能够在 PyTorch 中开发模型。
详细代码如下(来自 JUN KODA 的 notebook)。
for name, p in self.named_parameters():
if 'lstm' in name:
if 'weight_ih' in name:
nn.init.xavier_normal_(p.data)
elif 'weight_hh' in name:
nn.init.orthogonal_(p.data)
elif 'bias_ih' in name:
p.data.fill_(0)
# Set forget-gate bias to 1
n = p.size(0)
p.data[(n // 4):(n // 2)].fill_(1)
elif 'bias_hh' in name:
p.data.fill_(0)
if 'conv' in name:
if 'weight' in name:
nn.init.x