✔️ 第9名解决方案
大家好,
很高兴看到我进入了前10名。如果没有这个很棒的社区以及大家这个月分享的许多优秀作品,我不可能做到这一点,非常感谢大家!我也想分享我的解决方案和我学到的一些东西。这是我的堆叠策略。
预处理
我根据哪个模型能提供最佳的交叉验证(CV)分数,对不同的模型使用了不同的缩放方法。我尝试了所有方法,曾对二值化寄予厚望,但最终在大多数情况下使用了 Standard/Robust 缩放器。我的许多模型仅基于所有特征的子集进行训练,尤其是那些训练时间较长的模型,如 KNeighbors、多层感知机、AdaBoost、GBMs 等,还有一些仅基于二值特征进行训练——例如二次判别分析。
我将从其他人作品中借用的特征根据其创建者命名为 max_features、luca_features 和 mottchan_features 🙂
以下是他们的笔记本:
- Tabular play Oct 2021 - Feature selection (idea) 作者:@maxdiazbattan
- Feature Selection using Boruta-SHAP 作者:@lucamassaron
- TPS - Oct 2021_KMeans++ 作者:@motchan
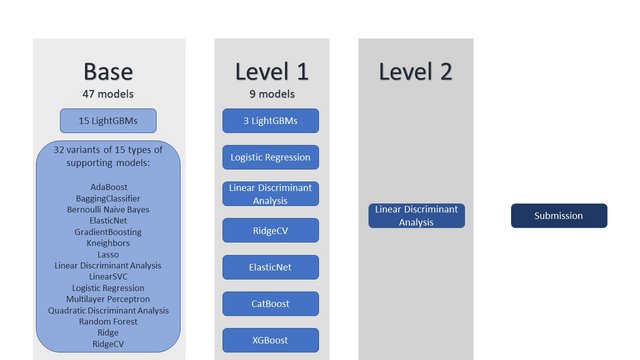
基础模型
我使用了15个 LightGBM 模型,每个模型在20个随机种子上训练并取平均值。我已经公开了我的笔记本和数据集,你可以在这里查看。为了增加堆叠的多样性,我添加了15种其他类型的模型的32个变体。其中大多数是受 @davidcoxon 的优秀笔记本启发的非树模型。
元模型
对于我的第一层模型,我总共使用了9个:3个 LightGBM、逻辑回归、ElasticNet、线性判别分析、RidgeCV、CatBoost 和 XGBoost。对于我的第二层模型,我选择了线性判别分析。
我非常享受这个月的比赛,希望在下一次比赛中见到你们中的许多人!