第11名方案:监督对比预训练 + 查询与数据库扩展
感谢 Google 和 Kaggle 组织了这场有趣的比赛!
祝贺获胜者们!
对于 @ofitserovlad、@evgenysidorov 和 @joven1997 这两支队伍来说,这是第一次参加大规模比赛。我们在实验上花费了大量时间,并在比赛接近尾声时构建了一个强大的流程。虽然我们最终与金牌擦肩而过,但我们仍然对结果非常满意,并且非常享受这次比赛。
方案概览
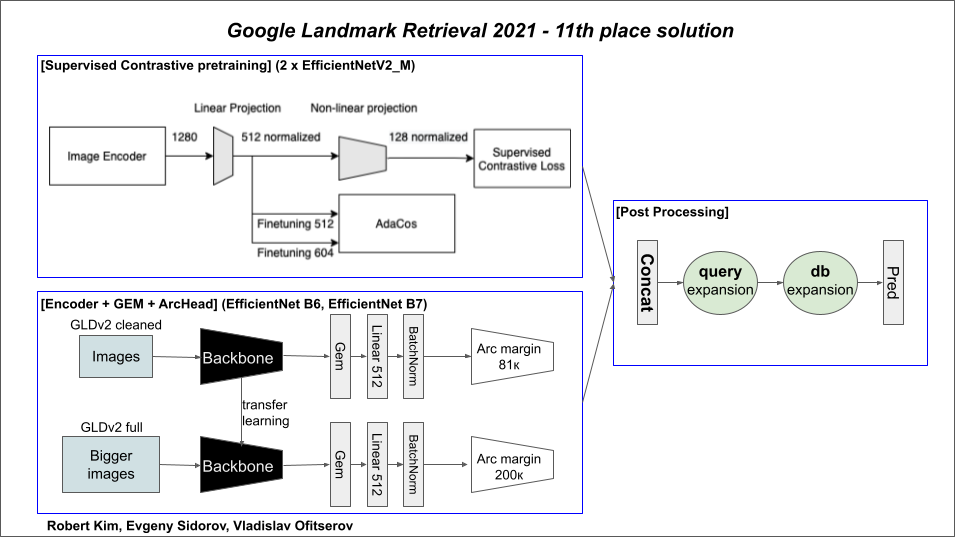
1. 监督对比预训练
模型
Efficientnetv2_m
验证
使用 Google 仓库中的索引数据(采样 10 万条)和测试数据(1 千条)计算 mAP。CV(交叉验证)和 LB(公开排行榜)有很好的相关性,LB 几乎总是比 CV 低 0.015-0.02(例如:CV 0.380 -> LB 0.360)。
训练流程
Fat Cat 队在比赛中稍晚(结束前 1.5 周)确定了一个相当强的 3 阶段训练过程:
- 在 448 分辨率和干净数据集上进行带有类别平衡温度的人工采样监督对比预训练。
- 在干净数据集上使用 AdaCos 和带有类别平衡的 Focal Loss 进行 512 分辨率的微调。
- 与第 2 阶段相同,但分辨率为 604 并使用完整数据集。
带有类别平衡温度的人工采样监督对比预训练
预训练部分受这篇论文启发。在这个阶段,模型应该学习简单的图像特征,并在微调阶段之前具有更好的泛化能力。该论文的前提与 SimCLR 非常相似,即对图像的 2 个增强(颜色抖动、随机翻转)随机裁剪进行操作,并使它们在余弦空间中接近。监督对比论文的扩展是使批次中同一类别的图像裁剪也彼此接近。该论文还在将图像嵌入输入非线性投影头之前对其进行归一化。投影头的输出随后用于监督对比损失。
原始论文实现的主要问题在于他们使用了巨大的批量(8192)且只有 1000 个类别,这样做在一定程度上保证了批次中会有多个同类实例。当我尝试使用 256 的批量进行这种方法时,CV 只有约 0.180,这清楚地表明批次中出现同类别的概率非常小。
在结束前 1.5 周,我意识到我可以人工将不同图像的同类裁剪采样到一个批次中。我以这种方式打乱数据集:每 4 张连续图像都是同一类别的增强裁剪。这种预训练方式在 10 个 epoch 后 CV mAP 达到了 0.273(并且比裁剪同一图像的两个部分快得多)。图表显示,如果给予更多时间,它可能达到 0.300。预训练我使用了带有余弦预热和退火的 SGD。
此外,使用了每个类别的单独温度。它是使用类别平衡策略导出的,并省略了最终归一化(即权重之和等于类别数量)。
微调
微调使用了 Adaptive Cosine Loss。它是 ArcFace 的扩展,也被去年的获胜者使用。监督对比预训练是微调期间更快收敛的关键步骤。如果没有预训练,在干净数据和 512 分辨率上训练 1 个 epoch 后,CV mAP 为 0.210;而有了预训练,它从 0.31 开始,并在使用 SGD 和余弦调度训练 10 个 epoch 后达到 0.35。然而,如果有更好的超参数,它可能会攀升得更高。随后,分辨率增加到 604 并在完整数据集上进行微调。
在比赛最后,我们为来自亚洲、非洲和大洋洲的地标增加了额外权重,试图匹配 Google 论文中描述的测试数据分布。这有助于