第5名方案分享:一种可学习的池化方法
恭喜获奖者,也感谢 Google 和 Kaggle 主办了如此有趣的比赛!
这是我第一次参加地标识别/检索比赛。在阅读了往届的获胜方案后,我也对我有限的计算资源(最初只有 1 张 3090 显卡)感到焦虑。因此,我决定寻找一种更适合该任务的(负担得起的)模型架构,而不是遵循常见的“网络+GeM+ArcFace”方法。
基于“更大的输入图像会带来更好的准确率”这一观察,我尝试使用主干网络中的中间特征图。根据我在 Youtube8M 视频分类中的经验,我发现 NeXtVLAD 在聚合和合并来自这些不同特征图的特征方面表现相当不错。
模型架构
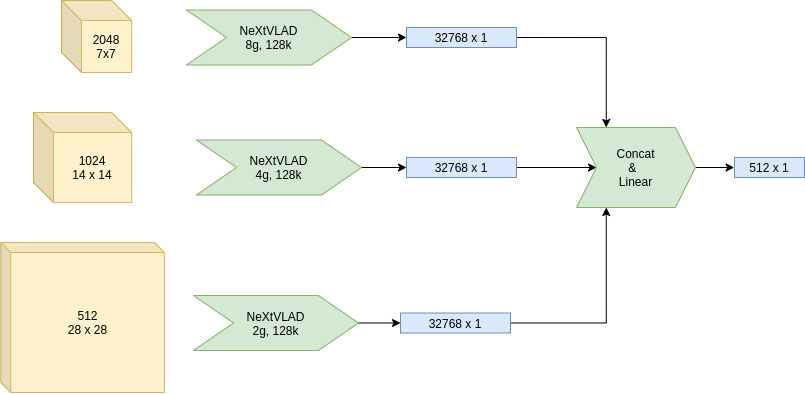
如您所见,每个特征图通过 NeXtVLAD 聚合为一个高维的一维特征,然后这些特征被拼接并输入到一个简单的线性投影层(输出维度=512)。在我的实现中,我还通过另一个 SE-gating 层增加了更多的非线性(实际上发现这并没有太大帮助)。最后,我们使用 ArcFace 乘积和动态边际作为损失函数。
训练设置:
V2X:320 万张图像,包含 81313 个地标
V2C:160 万张图像,包含 81313 个地标
V2Full:410 万张图像,包含 203094 个地标 + 非地标
1) 固定主干网络的权重,仅用 V2X 训练可学习的池化层 10 个 epoch,这 surprisingly(令人惊讶地)获得了非常高的本地验证分数(约 90%)。[AdamW,初始学习率 0.001,衰减率 0.8]
2) 用 V2C 微调整个模型 10 个 epoch(本地验证准确率约 94%)。[AdamW,初始学习率 0.0001,衰减率 0.9]
3) 仅更改 ArcFace 层为 203095 个类别(使用 2019 年测试集中的非地标数据真的很有帮助)。再次固定主干网络的权重,仅用 V2Full 调整可学习的池化层。(本地验证 10 个 epoch 后准确率约 95-96%)。[AdamW,初始学习率 0.001,衰减率 0.8]
可学习池化层的优势在于:
- 训练速度超快,因为您在第 1 步和第 3 步只需要训练可学习的池化层。
- 我在第 1 步和第 2 步使用了 256x256 的图像输入尺寸。然后仅在第 3 步增加图像尺寸,此时主干网络是固定的(所以我从不需要用大尺寸输入图像训练 EfficientNet)。
例如,使用该设置,在单张 3090 GPU 上训练一个 swin-base-224 只需要大约 3 天。
我在 9 月初仅凭一张 3090 就进入了前 10 名。然后我的队友 @marbury 给我提供了另外 2 张 V100,这样我就可以扩展到不同的主干网络。我的最终方案是以下模型的集成:
- swin-base-224
- swin-base-384
- swin-large-224
- resnest101(第 3 步输入尺寸为 512)
- efficientv2-m(第 3 步输入尺寸为 512)
最终的 LB(Leaderboard)分数与主干模型在 ImageNet 上的准确率高度相关,我想这表明这种可学习池化方法具有良好的迁移学习能力。
看看这种模型架构配合更复杂的主干网络(包括 efficientb5-b7、efficientv2-large 和 swin-large-384)能达到什么效果将会很有趣。仍有很大的改进空间,希望能激发更多在明年的比赛中使用可学习池化模块的想法和工作。代码整理干净后我会分享出来。
其他见解
- 在推理过程中使用整个 v2full 作为索引集对于保持前 10 名的成绩非常重要。