[第3名] 我的工作总结
2021-09-10 更新
最终排名是第3名!谢谢大家 :) 我的源代码有点乱,但你可以在这里查看:GitHub 仓库 和 Kaggle Notebook。
首先,我要感谢主办方组织了这次比赛。
这是一场非常艰难的比赛,但我从中学到了很多东西。
我不知道我的最终排名会是多少,但我会和大家分享我所做的工作。
模型策略
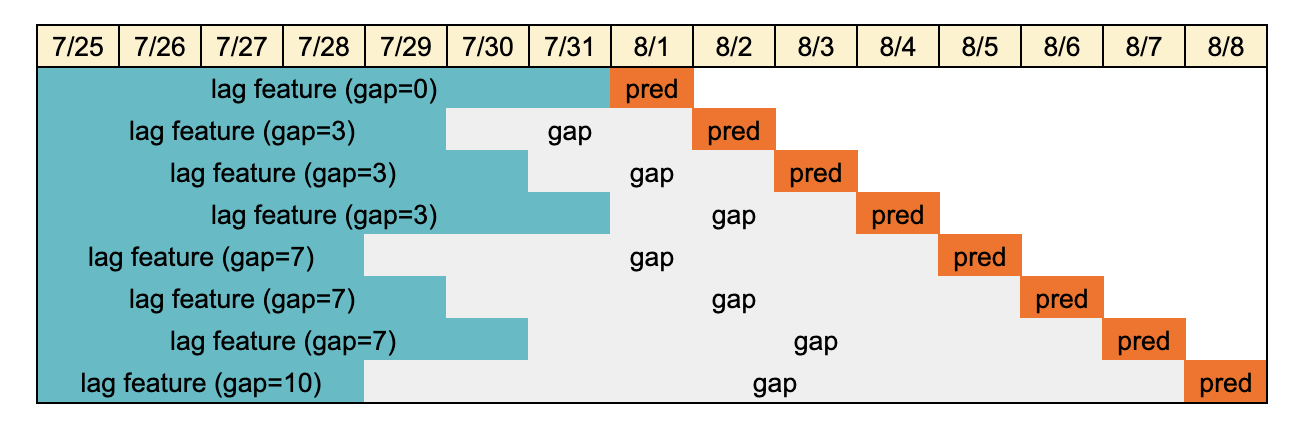
滞后特征在本次比赛中非常有用,但我们不能在测试数据期间使用目标信息。因此,我们需要在预测日期和滞后特征数据之间设置适当的“间隔”。
例如,如果你想对 8/4 进行预测,
你需要创建至少 3 天的间隔,因为你不能使用 8/1 到 8/3 的目标信息。
我将测试数据分为 8 个时期,并在每个时期使用具有不同间隔的不同模型(间隔:0、3、7、14、21、28、35、45 天)。
模型
三个模型进行了集成,每个目标有不同的权重。
- LightGBM
- MLP (多层感知机)
- 1DCNN (一维卷积神经网络)
1DCNN 与 MoA 比赛第 2 名的方案相同。
验证
基于时间的划分。
- 更新前的验证集:2019/8, 2020/8, 2021/4
- 更新后的验证集:2020/8, 2021/6, 2021/7
基本上,我只采纳了在所有时期都能提高分数的想法。
特征
我使用了约 440 个特征。除了基本表的连接和 asof 合并外,还使用了以下特征:
- 每位球员的滞后特征
- 过去 7/28/70/360/720 天的平均值
- 赛季期间的平均值
- 去年同期平均值
- 有比赛/无比赛日的平均值
- 事件数量、投球事件数量、动作事件数量
- 距离上次名单、奖项、交易和比赛数据的日期天数
- 过去 7/30/90 天的比赛数据总和
- 当天的比赛和事件数量
- 事件级元特征
- 基于事件表训练的模型预测值的聚合
- 按 (日期, 球员ID), (日期, 球队ID) 和 (日期) 分组
累积计数泄露
从时间序列 API 获取的数据框的累积计数与目标之间存在奇怪的相关性。
我在比赛结束前 3 天注意到了这个问题。我没有在讨论区发布它,因为这可能会困扰参赛者,而是立即联系了主办方。
将此累积计数添加到特征中只能稍微提高 CV(交叉验证)分数,所以它可能是某种伪影或其他东西,但即使它不能大幅提高 CV,最好还是打乱测试数据,因为行的顺序有意义这件事本身就很荒谬。
我最终没有在最终提交中使用这个泄露信息。
实现笔记
在 Jupyter Notebook 中使用时间序列 API 构建复杂的数据管道可能非常痛苦。我会分享我的一些努力。
- 在 GitHub 上维护源代码,并将 BASE64 编码的代码粘贴到 Jupyter Notebook 中
- 推理 Notebook 也在 GitHub 上维护,并通过 GitHub Actions 自动上传为 Kaggle Kernel
- 避免使用 Pandas,而是使用 NumPy 数组字典来管理状态更新
- 对训练数据和推理使用相同的特征生成函数