第15名方案:8天的努力
大家好,
首先,我要感谢 Kaggle 和组织者的辛勤工作,让这场比赛得以顺利进行,重置后的数据质量非常好。在重置之后,我们原本不确定是否要继续参加这场比赛,因为我们当时正忙于其他比赛,但我还是要感谢 @nischaydnk 和 @shivamcyborg 加入了我,尽管他们在结束 SIIM Covid 比赛后已经筋疲力尽,当时距离比赛结束仅剩 8 天。
摘要
我们的方法与排行榜前列的其他方案非常相似,只是由于时间紧迫,我们错过了几个关键点。
我们的建模包含三个阶段:
1) 在旧训练数据上预训练
2) 在新训练数据上微调
3) 在旧测试数据和新测试数据(伪标签)上进一步微调
我们在数据的 "ON" 阶段(即 [0,2,4])训练了所有模型,以便在数据量巨大且时间紧迫的情况下快速迭代,而且这对我们来说效果似乎更好。
第一阶段:训练
在比赛重置之前,我们在没有利用数据泄露的情况下排名第 6,拥有许多强大的模型。因此,我们大部分模型的第一阶段训练实际上已经完成。我们妥善记录了所有内容,这帮助我们迅速重启了比赛。
第二阶段:训练
重新加入比赛后,我们没有从头开始训练任何模型,而是加载了所有在先前有泄露的训练数据上训练过的模型,并开始在新数据上进行训练。
我们在这一阶段训练了以下模型,这些模型全部用于我们的最终集成:
- Effnet B5
- Effnet B7
- Eca-nfnet_l0
- Effnetv2m
我们使用了非常轻量的数据增强(垂直翻转、水平翻转、随机亮度对比度、Cutout),因为我们担心如果使用重型增强会丢失微弱的信号。所有模型都训练了 20 个 Epoch,并使用分层 5 折交叉验证(CV)。
第三阶段:训练
我们知道新的训练数据和测试数据分布不同,所以我们开始仅对高置信度的标签进行伪标签处理,只选取了 5000 个样本。这有助于提高 CV 分数,但没有反映在 LB(Leaderboard)上,当然我们也没有时间去分析为什么会这样。我们认为旧测试数据的分布可能与新测试数据相似,因此最终我们决定在所有旧测试数据和所有新测试数据(用我们当前最佳的融合模型进行伪标签处理)上重新训练模型。
在第三阶段,我们使用了类似的增强,但降低了学习率并减少了 Epoch。
寻找“魔法”的征途
通过上述技术,我们达到了 CV:0.901 和 LB:0.795,最后几天的时间都花在了寻找“魔法”上。从主办方的评论中,我们都知道训练集中存在一组不同的信号,我们使用最佳模型的嵌入进行聚类并生成 TSNE 图,以分离出这些图像。
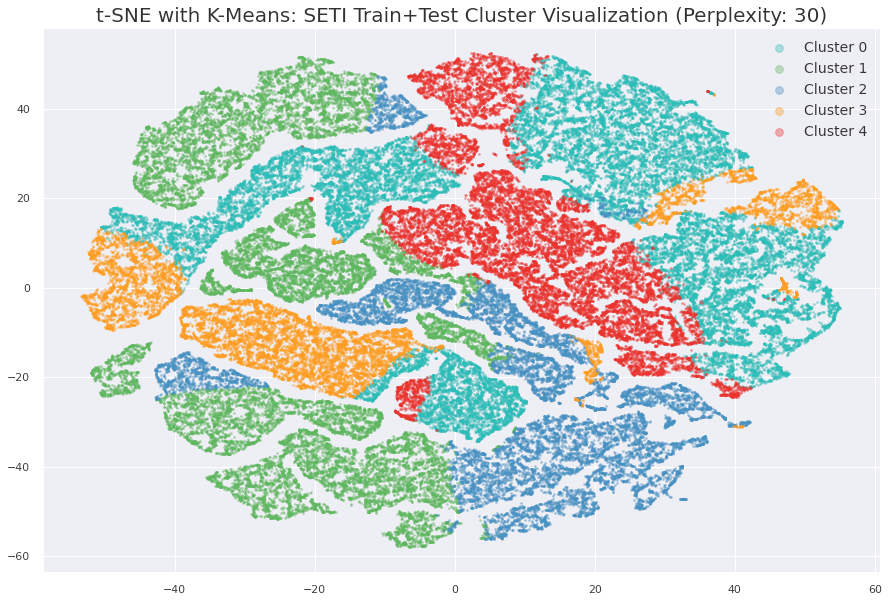
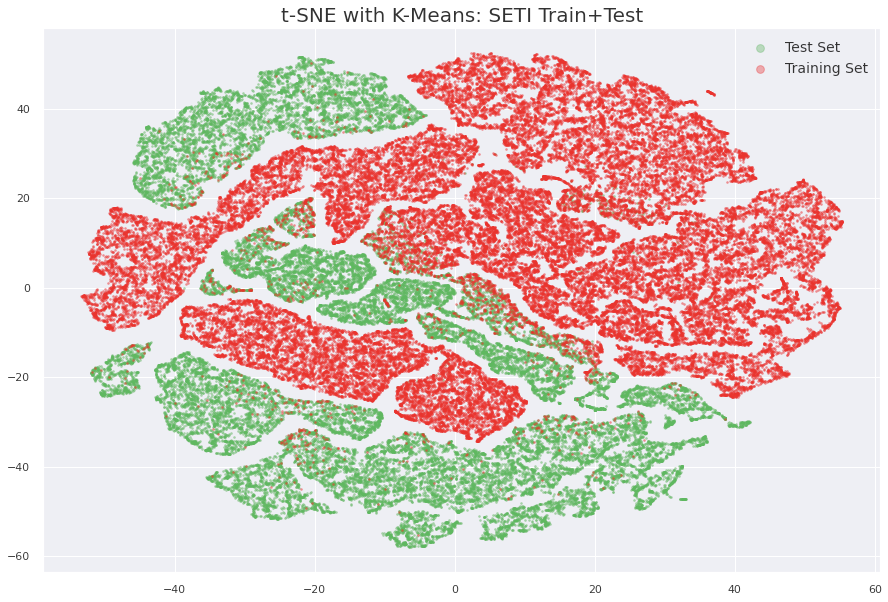
从上面的图表中,我们清楚地看到超过 50% 的测试数据与训练集几乎没有重叠,而且我们能够看到聚类 1 主要属于测试集,因此我们开始查看其中的图像,并最终分离出了新的信号。
然而,我们未能有效地利用这一点。
那些没起作用的方法
- Qishen ha 的 Alaska 比赛技巧(移除 EfficientNet 的最后几块并在顶部添加卷积层),类似于这里的方法。
- 减少 Conv Stem 中的模型步幅,以便在高分辨率下进行更长时间的训练。
- 残差 Bi-LSTM 头部。
- 来自这里的上一次 SETI 比赛的获胜方案。
经验教训
在阅读了顶级解决方案后,我们意识到由于