第4名解决方案
首先,我要感谢 Kaggle、SIIM、FISABIO 和 RSNA 举办了这场精彩的比赛,也要感谢这个社区不断的分享。祝贺所有的获胜者、奖牌得主以及这个社区中了不起的人们。
感谢我们团队的所有成员 @cdeotte @zaber666 @nexh98 @artemenon。没有你们,这一切都不可能实现。特别感谢 @cdeotte 与我们组队。我们从您身上学到了很多。毫无疑问,您是最好的 Kaggler 之一。
数据处理:
- 数据清洗:我们手动移除了分类和检测任务中的重复数据。对于检测任务,我们没有采用每位患者只取一张图片的方法,而是仅移除了未标注的图片。因此,我们的 CV 分数相比大多数人较低,但我们与 LB 有很好的相关性。
- 交叉验证:StratifiedGroupKFold。
研究级别:
- 预训练:我们在 CheXpert 数据集上预训练了我们的模型。因此,我们所有的模型都使用了该预训练权重(Chris 的 aux-loss 模型除外)。
- 模型:EfficientnetB6 和 EfficientnetB7。(其他模型对我们来说效果不佳,甚至包括
effnetv2、resnet200d、nfnet、vit)。 - 损失函数:CategoricalCrossEntropy(分类交叉熵)。
- 标签平滑:0.01
- 数据增强:水平翻转、垂直翻转、随机旋转、CoarseDropout、随机平移、随机缩放、随机(亮度, 对比度)、Cutmix-Mixup。
- 学习率调度器:WarmpupExponentialDecay。
- 图像尺寸:512, 640, 768。
- 伪标签:BIMCV + RICORD + RSNA。
- 知识蒸馏(KD):我们使用了大约 5 个最好的模型来生成软标签,我们的一次提交使用了 3 个 KD 模型。
- Aux-Loss:我们的一次提交使用了 @cdeotte 的 aux-loss 模型,该模型使用 FPN 和 EfficientnetB4 作为主干。您可以查看此处的帖子了解更多详情。我们还使用了 @hengck23 讨论中的 aux-loss,并用它为 KD 模型生成软标签。
- 后处理:我们使用几何平均重新排列我们的置信度分数(灵感来自 @cdeotte 在 VinBigData 比赛中的解决方案)。我们的 4cls 模型表现非常强势,以至于这对分数的影响微乎其微。所以最终我们决定不使用它,尽管它确实稍微提高了 CV。
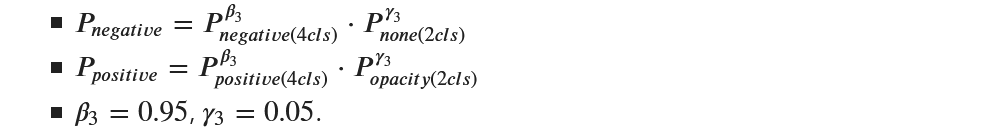
2cls 模型:
我们只使用了一个 2cls 模型。增加更多模型并没有太大影响。
- 模型:EfficientNetb7
- 图像尺寸:640
- 外部数据:我们使用了 RICORD 数据集及其标签,标签由 @raddar 发布在此处。我们简单地采用最大投票法来获取不同标注者的标签。
图像级别:
- 预训练:我们预训练了检测模型的所有主干网络。
- 外部数据:RSNA - 仅包含 `opacity` (不透明度) (6k+)。
- 模型:yolov5x-transformer(感谢 @hengck23 发布)、yolov5x6、yolov3-spp。
- 数据增强:水平翻转、垂直翻转、随机(亮度, 对比度)、Mosaic-Mixup。 <li