38 名公开榜,46 名私有榜解决方案 (Uni-Mol/XGB)
这是我首次参加 Kaggle 比赛,很高兴能取得当前的成绩。本文旨在梳理我在此次比赛中的完整流程与思路,希望能为其他参赛者提供一些参考,也恳请各位专家不吝赐教。如有疏漏之处,还请多多包涵。
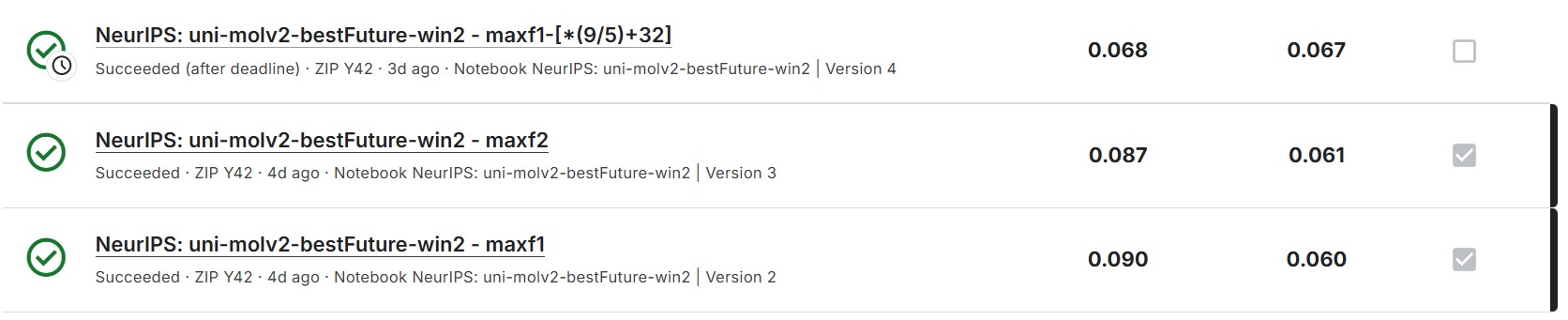
作为初学者,我们的工作主要围绕 Uni-Mol 进行参数调优,并结合 XGBoost 模型进行预测。下表展示了我们的最终成绩(包含将 Tg 单位从摄氏度转换为华氏度后的成绩)。
方法复盘
本节将介绍我们最终提交方案的形成过程。
1. 环境搭建
为确保 Uni-Mol 能够顺利运行,作为初学者,我遇到了不少问题,也花费了大量时间。非常感谢师兄 ShengSheng Wei 的指导,帮助我少走了很多弯路。在 Kaggle 平台上,只需安装 addict-2.4.0 与 rdkit-2025.3.5 即可保证 Uni-Mol 的正常运行。
2. 数据清洗
我们整合了官方提供的全部数据以及 Kaggle 平台上的公开外部数据集,包括 JCIM_sup_bigsmiles.csv, Tc_SMILES.csv, TgSS_enriched_cleaned.csv, data_dnst1.xlsx, data_tg3.xlsx。
Uni-Mol v2 模型在处理无法生成 3D 构象的 SMILES 字符串时会报错并中断训练(Uni-Mol v1 则无此问题)。因此,我们对所有训练数据进行了清洗,移除了这部分数据,大约占总训练数据的 8%。
Uni-Mol 支持多目标回归。考虑到大部分 SMILES 字符串同时包含 Density 和 Rg 两个目标值,我们尝试将它们共同训练。最终,我们将数据集按目标属性分成了四份:FFV、Tc、Tg 以及 Density_Rg。
3. 模型训练
考虑到 GPU 显存限制(RTX 4090 24G)以及不同属性训练集的样本数量差异,我们针对性地选择了模型参数和 batch_size。
下表列出了我们最终提交方案中所使用的训练参数,该方案取得了我们 Public Leaderboard (LB) 的最好成绩。当然,这未必是全局最优的参数组合。
| 属性 | 模型 | epochs | batch_size | learning_rate | kfold | early_stopping |
|---|---|---|---|---|---|---|
| Density_Rg | 164m | 80 | 4 | 0.0001 | 5 | 10 |
| FFV | unimolv1 | 80 | 12 | 0.0001 | 5 | 10 |
| Tc | 84m | 80 | 8 | 0.0001 | 5 | 10 |
| Tg | 84m | 80 | 4 | 0.0001 | 5 | 10 |
4. 预测
由于 Uni-Mol v2 无法处理不能生成 3D 构象的 SMILES,我们首先将测试集分为“有效分子”(可生成 3D 构象)和“无效分子”。随后,我们分别使用 Uni-Mol v2 对“有效分子”进行预测,使用 XGBoost 模型对“无效分子”进行预测,最后合并两部分结果。
我们的 XGBoost 模型基于 Multi-Seed Ensemble of GBDTs and a Neural Network 与 Extra Data with FS (Starting Point) 这两个公开 Notebook,并在其基础上进行了参数微调。
比赛回顾
在比赛过程中,我们进行了一些有益的尝试,也走了一些弯路。
1. 探索阶段
- 初步尝试:完全使用 Uni-Mol v1 在 Kaggle 平台上进行训练和预测。但成绩不理想,且训练过程非常耗时。 Notebook 链接: https://www.kaggle.com/code/zipy42/neurips-unimol-test

- 离线优化:进行离线训练并对 Uni-Mol v1 进行参数调优,但 LB 成绩始终未能突破 0.070。
- 模型升级:转而使用 Uni-Mol v2 进行训练和预测,取得了 0.072 的成绩。经团队讨论,我们发现成绩不佳的原因在于 v2 模型无法预测那些“无效分子”。
2. 融合模型阶段
- 模型融合:尝试将 Uni-Mol v2 与 XGBoost 模型( https://www.kaggle.com/code/zipy42/neurips-test0623 )进行融合。成绩取得了重大突破,进入了 0.063 的银牌分数区间。我们随即确定了两种提分策略:提升 Uni-Mol v2 的预测精度,以及提升 XGBoost 的预测精度。
- Uni-Mol 调优:通过 40 余次提交对 Uni-Mol v2 进行参数调优,尝试了增加 epochs、
batch_size、k-fold 折数,也尝试了分开训练 Density 与 Rg,并增加了额外的训练数据。这些尝试带来了一些成绩提升。 - XGBoost 优化:更换为表现更好的公开 XGBoost 模型,成绩有微小提升。
3. 误区与反思
增加 k-fold 的折数可以提升模型成绩,但同时也显著增加了提交评分的时长(从 1.5 小时增至 2 小时)。由于初次参赛经验不足,我们错误地认为这 2 小时全部是 Leaderboard (LB) 的评分时间,并担心 Private Leaderboard (PB) 的预测无法在规定时间内完成。因此,我们开始尝试缩短模型的预测时间。
- 减少 k-fold 折数:将 k-fold 减少到 1、2、3,发现评分时间显著缩短,但成绩也明显下降。
- 增大预测
batch_size:临近截止日期,未能深入研究如何有效增大预测的batch_size,仅仅修改了模型配置文件。结果发现评分时间反而更长,但成绩有微小的意外提升。 - 使用小参数模型:选择参数量更小的模型可以加快评分速度,但成绩同样明显下降。
在权衡之后,我们最终选择了两个方案进行提交:一个是我们 LB 最优成绩的模型(预测时间长),另一个是预测时间较短但成绩稍差的方案(部分属性 kfold=3,部分为 5)。事实证明我们此前的担忧是多余的,比赛的评分时间足以完成 LB 和 PB 的计算。
经验总结
无效尝试
- 降低
batch_size:不仅增加了训练时间,还导致了性能下降。 - 过度优化“无效分子”:投入过多精力优化处理“无效分子”的 XGBoost 模型,但对总成绩的提升微乎其微。
有效或有潜力的尝试
- 增大模型参数:使用更大的模型参数能显著提升成绩(尤其是从 Uni-Mol v1 升级到 v2)。遗憾的是,受限于显存,我们无法训练 310m 以上参数的模型。
- 混合模型策略:使用机器学习模型(如 XGBoost)来处理“无效分子”,这是我们取得当前成绩的关键。
- 超参数搜索:很遗憾当时未能想到使用 Optuna 对 Uni-Mol 进行超参数搜索,这或许是一个有效的提升方向。
结语
感谢您阅读至此。通过这次比赛,我收获颇丰,尤其是在 Kaggle 社区中,大家积极分享代码和思路的氛围让我受益匪浅。
当然也存在一些遗憾。我相信 Uni-Mol 模型仍有潜力取得更好的成绩,可能我们未能找到最优的参数组合,或受限于硬件条件无法训练更大的模型。希望在未来的比赛中我能不断进步,取得更优异的成绩。
作为一名初学者,我将继续深入学习机器学习领域的知识。最后,再次感谢所有参赛者的分享与启发。