第15名团队 “Trust Your CV” —— 相信你的CV,也要相信多样性!
感谢 Kaggle 和 CommonLit 举办这场有趣而激动人心的比赛。感谢团队所有成员的精诚合作! @mobassir @ragnar123 @datafan07 @ivanaerlic @cdeotte 我们的团队策略是采用多样化的 NLP transformer 模型,因为训练数据集很小,过拟合的风险很大。除了骨干网络的多样性,我们的“秘密武器”是大量创造性的模型头部和创造性的训练计划,其中包括 RAPIDS cuml SVR 头部,它让 CV 和 LB 提升了 +0.002!
祝贺 Mobassir 和 Ragnar 成为竞赛大师!
@mobassir 和 @ragnar123 多年来一直与 Kaggle 社区分享高质量的 Notebooks 和讨论。他们的代码和讨论分享曾亲自帮助我在之前的比赛中获得金牌!我很高兴能见证他们此次获得金牌并成为 Kaggle 竞赛大师的成就。请大家和我一起祝贺他们。干得好,伙计们!
介绍
我们的团队最初由 @mobassir 和 @ragnar123 组成,他们在 3000 支队伍中进入了前 50 名。当他们邀请我加入他们的团队时,我很高兴,因为我当时正苦苦挣扎在进入前 200 名的路上!作为一个三人团队,我们决定多样性是本次比赛的最佳策略。我们邀请了 @datafan07 和 @ivanaerlic 加入我们的团队。这两位 Kagglers 在之前的比赛中已经证明他们能够构建富有创造性、多样性且强大的单模型。他们再次成功了!感谢 @datafan07 和 @ivanaerlic ,你们的模型太棒了!
相信你的 CV(交叉验证)
对于每个模型,我们都计算了 CV 和 LB 分数。如果两者都很好,我们就将该模型加入集成。我们最终的集成模型 CV 为 0.452,Public LB 为 0.451,Private LB 为 0.450。请注意,CV、Public LB 和 Private LB 之间存在很强的相关性。
Mobassir - PyTorch - DeBERTa-Large
配置 (CV 0.472 LB 0.463):
- 使用单一种子 (63)
- 使用自注意力头
- 使用分层学习权重衰减
- 训练了 7 个 epoch
- AdamW 学习率为 0.00003
- Batch size 和验证频率 = 8
- max_length = 300
- 使用 abhishek thakur 的基于分箱的分层5折交叉验证 (stratified5fold)
- 尝试了 SVR 头,但无法进一步提高 CV,因为我们认为自注意力头已经训练得非常好
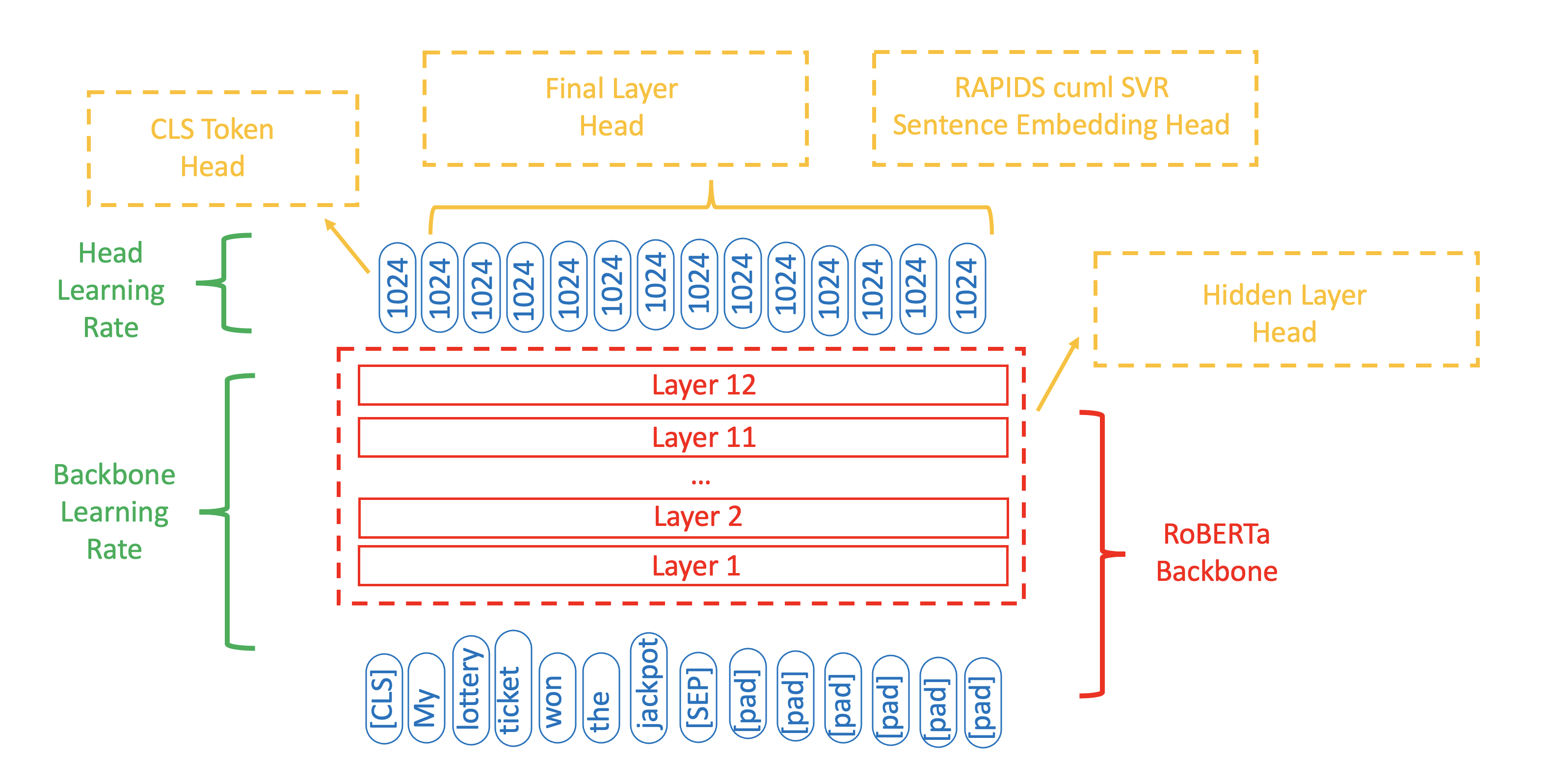
Ragnar - TensorFlow - RoBERTa-Large
- CV 0.462 LB 0.459
- 前两个头 - cls token 头,最后隐藏层头
- 第三个头 - SVR 头
- 两阶段训练:分别进行冻结骨干网络和不冻结骨干网络的训练
Ertugrul - PyTorch - Electra-Large, Funnel-Large, RoBERTa-Large
- CV 0.458 LB 0.454
- Huggingface
- Sentence Transformers
- 贝叶斯岭回归 头
- dropout = 0 (解释见 <a href