Public&Private 第37名方案 [Team CM, T0m 部分]
首先,感谢 Kaggle 和主办方举办这场有趣的比赛,也感谢我的队友 @teeyee314、@nazarov 和 @leecming。在这次比赛中,我从他们身上学到了很多。
由于这是我的第一次 NLP 比赛,我从阅读 BERT 论文开始,思考了很多关于如何稳定训练 BERT 以及如何设计回归模型的问题。
所以,我想讨论一下我为了实现上述目标所做的工作。
以下是我这部分的主要思路:
- 利用比赛数据进行二分类预训练。
- 高概率 Mixout(同时,BERT 层中的 Dropout=0)。
- 利用 Standard_error 进行加权损失计算。
- 针对每个隐藏层的自定义聚合层与 Head。
二分类预训练
我做了一个额外的预训练,这是受比赛目标的根源启发。它们实际上是 Bradley-Terry 值,来源于摘录对。
所以,我首先设计了一个二分类模型,然后将其权重用于主要的回归任务。
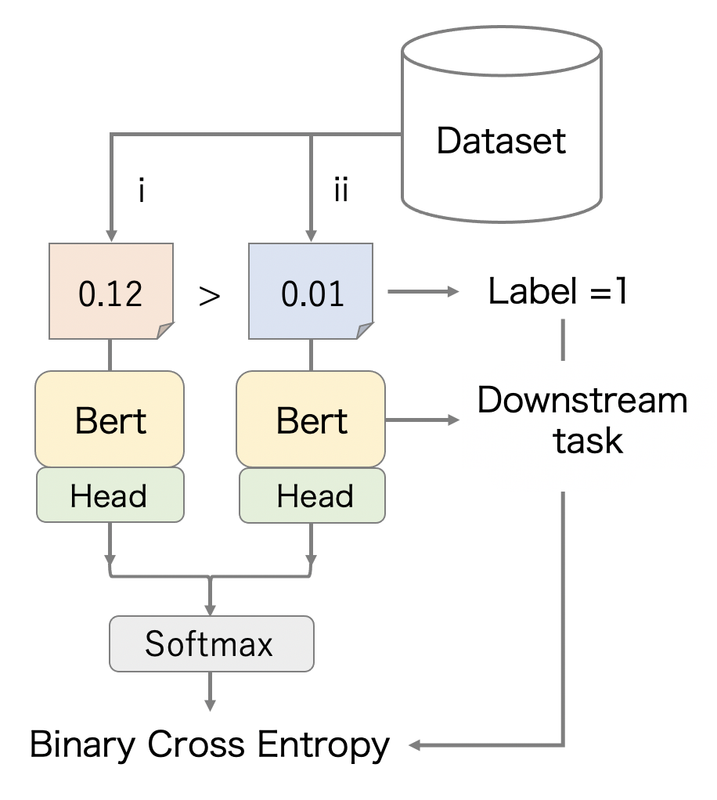
注意:
- BERT 的权重是共享的。
- 在训练阶段,样本对是随机采样的。
- 在验证阶段,样本对应该是固定的。
- 有很多采样策略(例如,采样目标差异大于阈值的样本对),但随机采样效果最好。
预训练权重使我的 CV 和 LB 提升了 0.002 ~ 0.01。
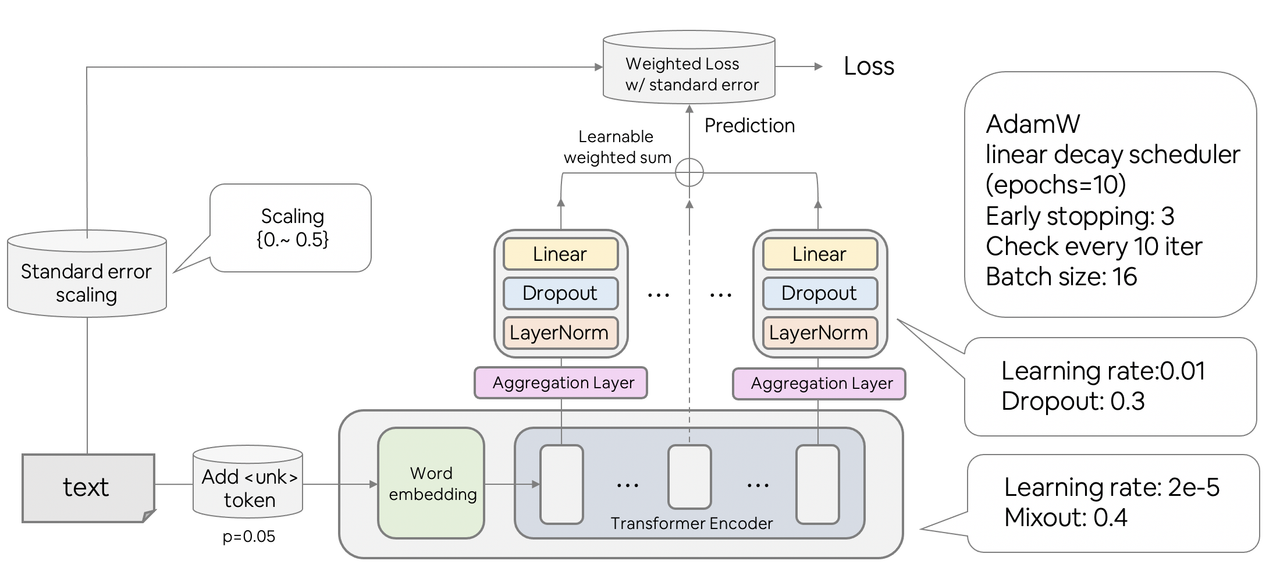
加权损失
为了使训练更加稳定,我使用了 standard_error 来计算训练损失。
细节如下:
- 将 standard_error 缩放到范围 {0. ~ 0.5}。
- 计算 MSELoss。
- 使用缩放后的 standard_error 对每个损失进行加权。
- 求平均值并反向传播。
# pytorch 简要示例代码
# 缩放
values = train["standard_error"].values
train["standard_error"] = 0.5 * (values - np.min(values)) / (np.max(values) - np.min(values))
~~~
# 训练
criterion = nn.MSELoss(reduction='none')
~~~
loss = (criterion(output.squeeze(), labels) * (1 - errors)).mean()
loss.backward()
针对每个隐藏层的自定义聚合层与 Head
我为每个 BERT 隐藏层添加了回归 Head,然后通过(可学习的)加权和来预测最终的目标值。
每个聚合层和 Head 的权重不共享。
class AggregationLayer(nn.Module):
def __init__(self, in_size, max_length):
super().__init__()
weights_init = torch.zeros(max_length).float()
self.seq_weights = torch.nn.Parameter(weights_init)
weights_init = torch.zeros(in_size).float()
weights_init.data[1:] = -1
self.dim_weights = torch.nn.Parameter(weights_init)
def forward(self, x):
w_dim = torch.softmax(self.dim_weights, dim=0)
w_seq = torch.softmax(self.seq_weights, dim=0)
x_dim = (x * w_dim).sum(1)
x_seq = (x * w_seq.unsqueeze(-1).expand(x.shape).float()).sum(1)
z = (x_dim + x_seq) / 2
return z
其他技巧
- 随机添加
<unk>token 提升了 CV 和 LB (p=0.05)。 - 强 Mixout 提升了 CV 和 LB (p=0.4)