第40名方案:我们如何在三天内从第1100名提升排名
首先,@shahules 和我想衷心感谢以下各位:@rhtsingh, @maunish, @jcesquiveld, @andretugan, @jacob34, @kurupical, @cdeotte 和 @markwijkhuizen。没有他们出色的工作和讨论,我们不可能取得今天的成绩。此外,我想特别感谢 @radek1 的精彩著作 Meta learning。这本书给了我很多灵感,我也将其中的一些想法应用到了这次比赛中。我强烈向所有数据科学家同行推荐这本书。这是我第一次认真参加 Kaggle 比赛。五年前我曾参加过几天的比赛,但没有坚持下去。但这次我坚持下来了 :) 再次非常衷心地感谢大家。两个月前我个人从未接触过 Transformers。多亏了这次比赛,我很高兴我发现了它。三天前我们还排在第1100名,所以我们真的很高兴能进入前40名。
受到 @rhtsingh 和 @maunish 的启发,我决定在比赛的前两个月公开分享我的所有进展。后来 @shahules 和我在正好一个月前相遇,并组建了团队。
我们意识到,在这场比赛中成功的关键在于以下几点:
- 稳定 Transformer 的训练
- 利用海量外部数据
- 优秀模型的良好集成
- 绝对不要过拟合
稳定 Transformer 的训练
在所有这些因素中,最困难的部分是稳定训练。我们的验证图表看起来像地震图。这是稳定前后的图表片段。
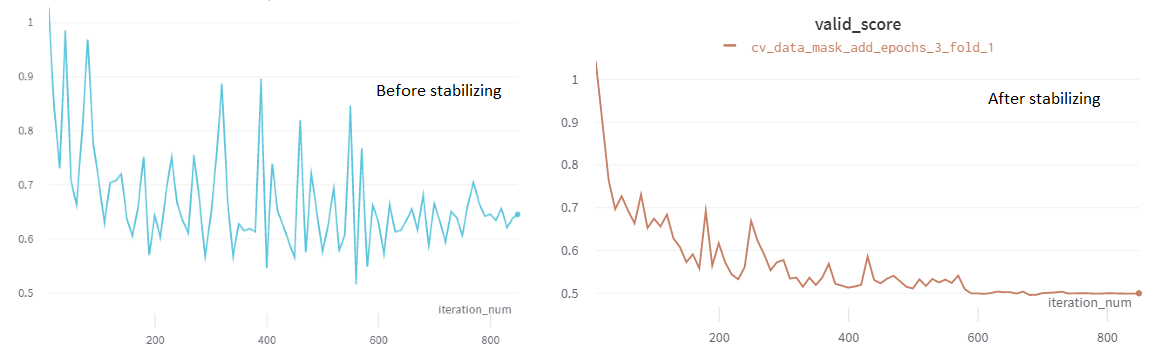
至少对于基础模型来说还可以,但对于大型模型来说简直是不可能的。我们也对每 N 次迭代进行评估感到非常不舒服。因此,我们花了大约二十天的时间专注于运行实验以稳定训练。那时我们发现了 @jcesquiveld 使用 差异化学习率 训练的模型。当我们第一次实现它时,感觉像魔法一样。训练非常稳定,不再有地震图了 ;) 这帮助我们避免了频繁的评估,也让我们能够舒适地在完整数据集上训练模型而无需验证。是的,在完整数据上训练而不是 K折交叉验证的想法来自 @cdeotte。你可以在 @abhishek 的 YouTube 频道上观看精彩的视频,其中4位特级大师分享了他们的成功秘诀。
工作设计
我们也意识到良好的集成是成功的关键,而独立性是成功集成的关键。因此,我们总是独立设计和运行实验,稍后再讨论结果,这样我们就不会互相产生偏见。为了便于进行相同的实验条件,也不做重复的工作,我们建立了一个包含所有管道组件的中央代码库,并遵循良好的编码原则。
选择模型且不过拟合
由于 CV(交叉验证)和 LB(排行榜)的相关性不大,我们有两个选择:我们可以探测 LB 并更多地了解测试数据,但我们几乎没有时间/提交次数了。我们的另一个选择是不仅仅根据 CV 分数来选择模型,而是通过观察验证图表,直观地评估训练和验证损失是否稳定,以及最终模型是否接近最佳模型(