第47名解决方案与代码
总结
首先,让我祝贺所有的获胜者,并感谢比赛主办方——这真是一个非常有趣的挑战!能够参与一个同时需要计算机视觉(CV)和自然语言处理(NLP)技能的比赛,并且拥有如此大的数据集和非常小的排名波动,真是太棒了。
有趣(也不那么有趣)的是,我一直确信比赛的截止日期其实是在两天后,即6月5日。我错误地创建了截止日期的日历条目,并且从未检查过它是否正确。令我惊讶的是,昨天查看比赛页面时,我才意识到距离结束只有10个小时了!😅
我的解决方案是七个CNN-LSTM编码器-解码器模型的集成。所有模型均使用PyTorch实现,并在配备Quadro RTX 6000 GPU的本地机器上进行训练。
代码
- Kaggle Notebook:复现我的提交和集成流程
- GitHub 仓库:包含完整的训练代码
数据
- 按照分子长度分层的单一80/20训练/测试划分
- 使用RDKit从
extra_approved_InChIs创建了300万张额外图像(感谢 @tuckerarrants) - 在每个epoch中,我使用所有训练图像 + 随机选取的100万张额外图像进行训练
分词器
- 我的分词器与 @yasufuminakama 在其出色的流程中提出的非常相似
- 使用训练数据 + 额外数据来拟合分词器,因此由于数据中包含更多不同的分子,最终增加了约20个token
图像增强
- 使用cv2形态学变换使线条和字母变粗:
image = cv2.morphologyEx(image, cv2.MORPH_OPEN, np.ones((2, 2))) image = cv2.erode(image, np.ones((2, 2))) - 训练期间进行小幅图像旋转:
ShiftScaleRotate(0.01, 0.01, 0.10) - 裁剪具有大空白边框的图片(感谢 @markwijkhuizen)
- 旋转高度 > 宽度的测试图像(感谢 @hengck23)

基础模型
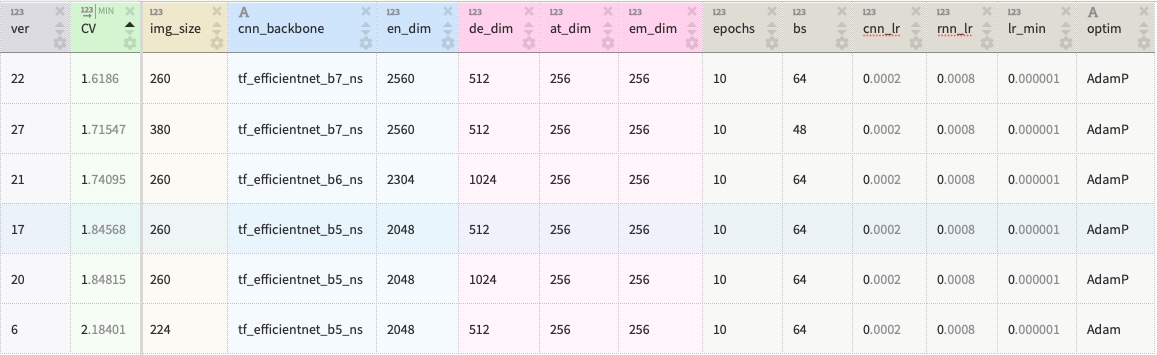
所有模型均使用基于EfficientNet的CNN编码器和基于LSTM的RNN解码器。下表来自Neptune.ai,显示了我顶级模型的主要架构和训练参数:
集成与后处理
- 在大多数基础模型上使用k = 5的束搜索(感谢 @tugstugi)
- 使用RDKit归一化每个模型的预测结果(感谢 @nofreewill)
- 使用多数投票法集成基础模型的预测
- 将“不自信”的预测设置为根据RDKit具有有效预测的最低CV模型产生的预测(再次感谢 @nofreewill)
我计划尝试的其他内容
- 添加图像元数据(如像素分辨率和高宽比)作为输入特征
- 使用单独的模型迭代预测InChI的不同部分(分子式、/c和/h部分),这些模型将图像和前一部分的预测作为输入
- 切换到Transformer。我几天前才开始研究Transformer流程,由于资源有限,没有足够的时间来训练重型模型
最终解决方案在公共排行榜上达到了1.32,在私人排行榜上达到了1.31(第47名)。希望这个总结对你们中的一些人有用。很乐意在评论中回答任何问题,下场比赛见!😊