第四名方案
感谢所有参与者、Kaggle,特别是这场有趣且重要的比赛的组织者!感谢你们做出了贡献!
摘要
我的解决方案基于两阶段模型:第一阶段基于图像,第二阶段基于检测,其中第一阶段的输出作为元数据与检测裁剪图像一起输入第二阶段模型。该设计的主要动机是东非地区的混合物种群。两阶段流程针对六个区域分别进行了训练。在两个阶段中均使用了单一的模型架构,即基于ImageNet预训练的EfficientNet B3,图像被裁剪/调整为400x400。两个阶段都使用了少量的图像增强。该系统使用PyTorch Lightning实现。
数据准备
为了识别未知位置并将其分配到区域,我采用了双重方法。在第一阶段,我利用图像注释中提供的关联物种对位置进行聚类。在第二阶段,我使用了一个监督分类模型(ResNet-18),标签为已知区域,在原始图像上运行,下采样至224x224。
在全图和检测级处理中,图像均被转换为numpy 3x400x400 uint8数组——这是在速度和存储之间的一种折衷。所有其他元数据存储在关系数据库中,主要反映了从json文件派生的iNaturalist注释结构。
使用Google Colab在所有图像上运行MegaDetector V4,并专门使用了V4的检测结果。
在东非地区的初步探索性数据分析(EDA)中,我注意到每个序列中有多个物种,图像可能根据少数成员进行标记(例如,一群黑斑羚(#96)中有一只斑马(#111),可能被标记为斑马)。序列级别可能采用了一种可预测的标记策略,但我没有花时间去寻找它。相反,我强调了每张图像只有单次检测的图像,从而将弱标签转换为强标签。这对许多物种效果很好,但我认为对于那些很少单独出现的物种(例如家羊(#72))有局限性。
采用了三种策略来处理类别不平衡。第一种是随机欠采样最常见的类别。使用加权随机采样器对稀有类别进行过采样。在某些情况下使用的第三种方法是合并其他区域的物种数据。例如,在最南端的南美地区,训练数据中美洲狮(#6)、美洲豹(#24)和领西貒(#8)的样本很少,但这些物种在更北的地区很丰富。这仅在检测级别进行,因为模型呈现的背景图像量最少。
模型
我的解决方案基于两阶段级联模型,一个基于图像,第二个基于检测(见图)。训练了六个独立的模型,每个区域一个;使用位置将训练和测试数据按区域划分。我在两个阶段都使用了基于ImageNet预训练EfficientNet B3模型的单一模型架构。第一阶段模型处理调整大小的相机陷阱图像和相关图像元数据(每序列帧数、帧号、检测数、一天中的时间、一年中的某天)。图像通过EfficientNet的特征提取层运行,然后与元数据结合并输入到一个小的全连接分类器。来自阶段1的整个类别预测向量,连同原始图像元数据(加上缩放),作为元数据输入阶段2分类器。此外,从全图中截取每次检测的图像,调整大小并输入EfficientNet的特征提取部分。2阶段模型的最终输出是每次检测的类别预测向量。
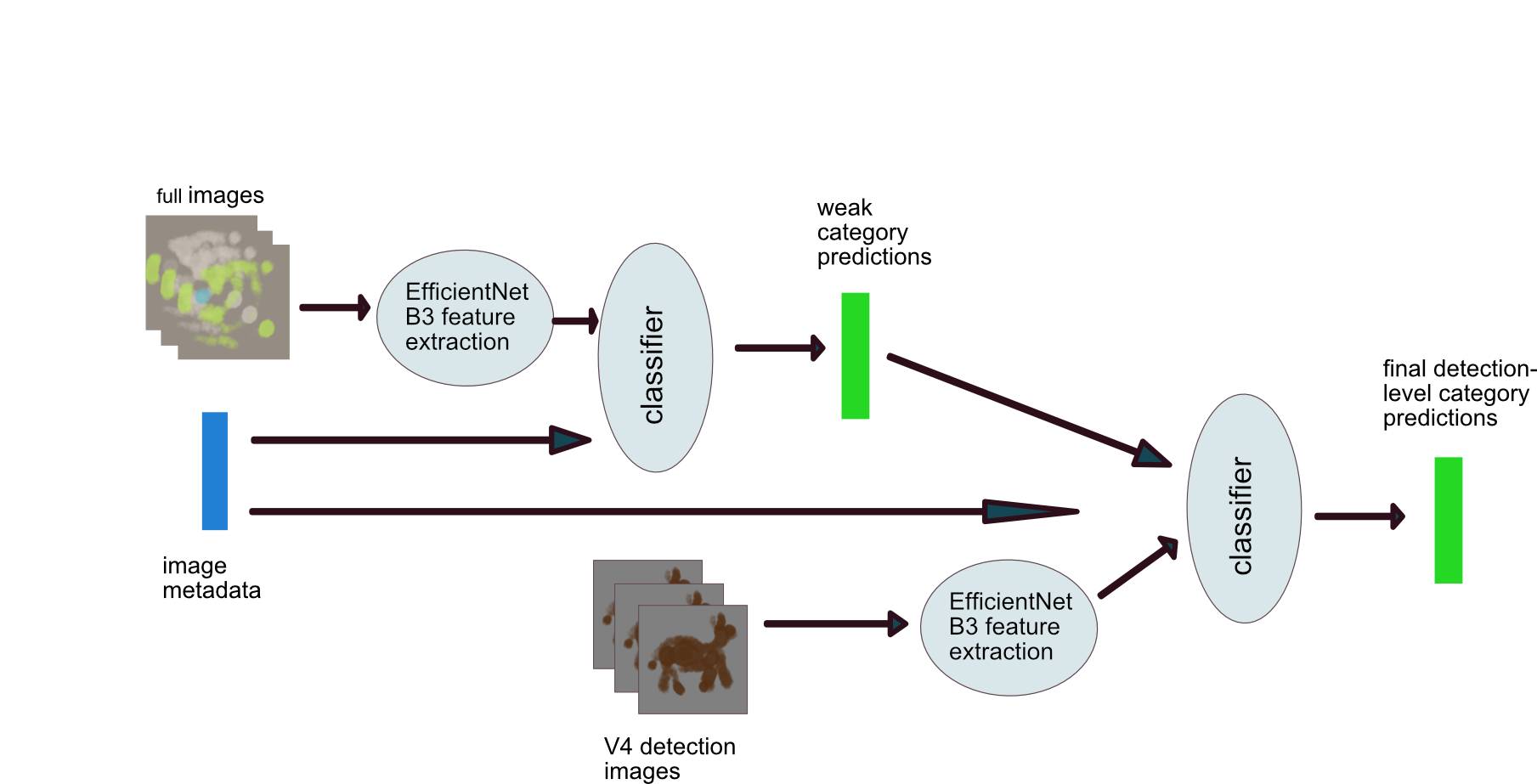
我在模型训练中使用了微调方法。最初保持EfficientNet权重冻结,训练分类器,然后对预训练网络进行微调。最终解决方案使用MultiLR调度器来降低微调阶段的训练学习率。两个模型中的损失函数均为CrossEntropyLoss。根据验证损失的停滞使用早停。
数据在每个区域内按位置分层,并进行五折交叉验证。唯一的集成是这5个折。两个阶段都使用了轻微的增强(随机水平翻转、随机擦除和随机灰度)。最后一步合并了每个区域的预测,对报告的检测应用每个物种的阈值。
那些奏效了但中途被放弃的方法……
我在早期进行了许多实验,结果非常有希望,但由于某种原因未能进入最终解决方案。
训练数据在检测级别进行了伪标记。单检测图像用于训练初始模型,然后预测多检测图像。高置信度的检测被添加到训练数据中,重复该过程直到达到固定点。其结果在许多情况下非常有希望且可预测(例如非洲的许多群居动物)。在其他情况下(例如白唇西貒(2)、家羊(#72)),效果不佳——可能是因为单例样本太少,或者当它们聚集时检测太密集。
另一个有希望但从未超越实验阶段的领域是预处理检测数据,消除同一位置内的静态检测。有许多固定树枝被归类为动物角或尾巴的情况,但鉴于它们在许多序列中的出现,它们本可以被安全移除,从而降低误报。
我在使用预训练ResNet-18自编码器后跟K-Means聚类将最初未知的位置分组到区域方面取得了部分成功。我使用Landsat 8波段4和5计算NDVI图像,然后复制它们以提供ResNet模型所需的