Fair Cell Activation Network 和 Swin Transformer,第一名解决方案
恭喜所有获奖者,感谢 Human Protein Atlas 团队和 Kaggle 主办了如此有趣的比赛。
1. 简介
本次比赛的主要挑战是找到一种方法来标记标记图像中的每个细胞,这是一种新类型的弱监督挑战,因为我们提供了一个细胞分割模型,这意味着这不是像弱监督目标检测或分割那样被广泛讨论的问题。
解决此问题的常用方法是在细胞上寻找 CAM 或注意力,但 CNN 网络的激活集中在图像中最具辨别力的部分,这导致召回率较低,为了解决这个问题,我基于 Puzzle-CAM 开发了一种称为 Fair Cell Activation Network (FCAN) 的网络。
在从 FCAN 获得每个细胞的预测后,我通过规则将细胞重新标记为 5 个等级,标签为 [1.0, 0.75, 0.5, 0.25, 0 ],并训练了一个 Swin Transformer 模型来预测细胞标签。
这两个模型的集成以及通过降低图像边界上细胞的置信度的后处理可以在私人 LB 上以 0.555 获得第一名,一个更复杂的包含 6 个模型的集成解决方案可以在私人 LB 上达到 0.566。
2. 方法
2.1 Fair Cell Activation Network
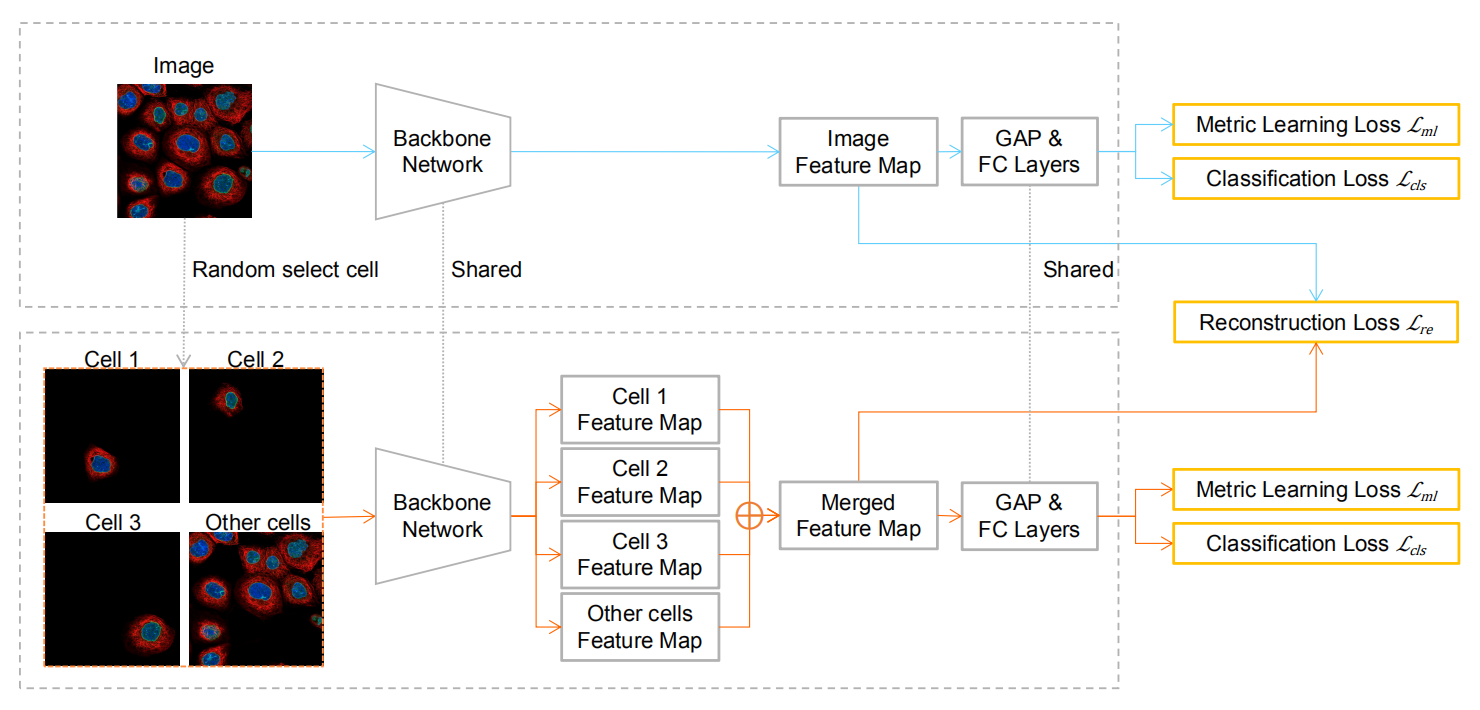
尽管存在许多实例,但 CNN 在图像特征图上的激活集中在一个类别中最具辨别力的实例上。我将这种现象称为不公平激活,为了解决这个问题,基于 Puzzle-CAM 提出了一种网络。
训练
推理
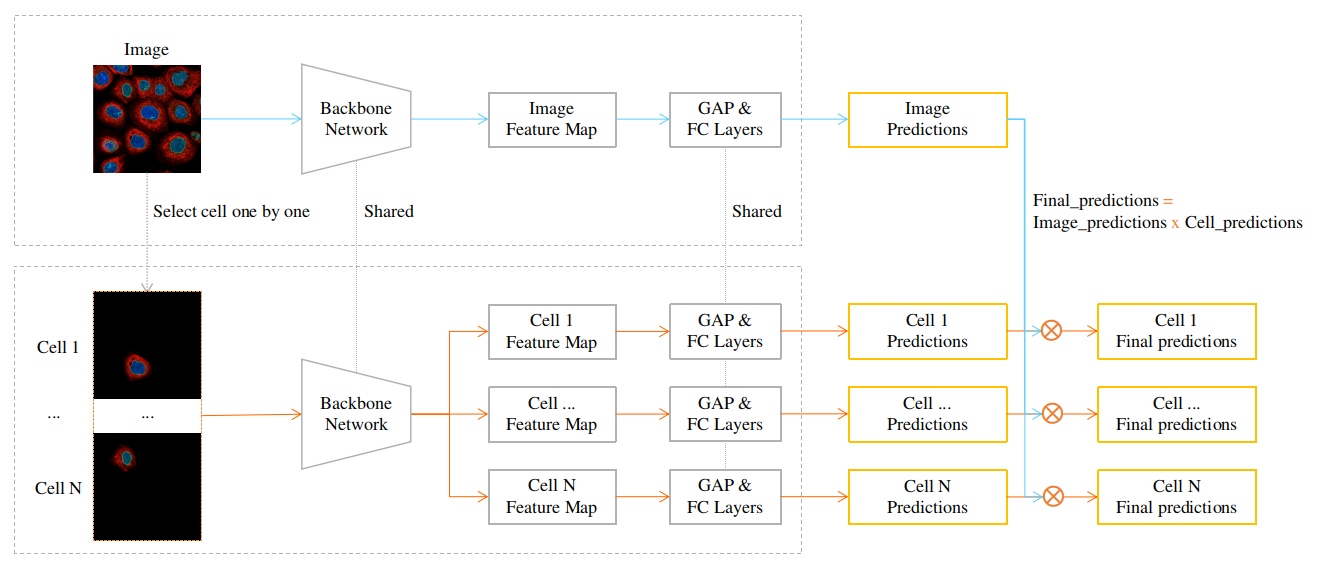
该模型与 Puzzle-CAM 在训练部分的主要区别在于我们可以选择细胞而不是将图像分割成网格。
细胞的置信度是图像级预测和细胞级预测的乘积。
细节
- 图像调整为 512x512 px
- 主干网络: EfficientNet-B0。
- 损失函数:
- Lcls 是 FocalLoss + SymmetricLovaszLoss + HardLogLoss
- Lml 是由 antibody-id 监督的 ArcFaceLoss 度量学习。
- Lre 是 MSELoss
- 增强:
- 翻转、转置、缩放、旋转、裁剪
- 将高置信度的有丝分裂纺锤体添加到其他图像以生成更多该类型的正样本(导致提升 0.02)
- 测试时间增强 (TTA): default, flipud, fliplr, transpose。
- 验证: 在公共测试集中选择 433 张图像(可以在 public-hpa 数据集中找到),并将它们从模型的训练集中移除。
模型分数对比
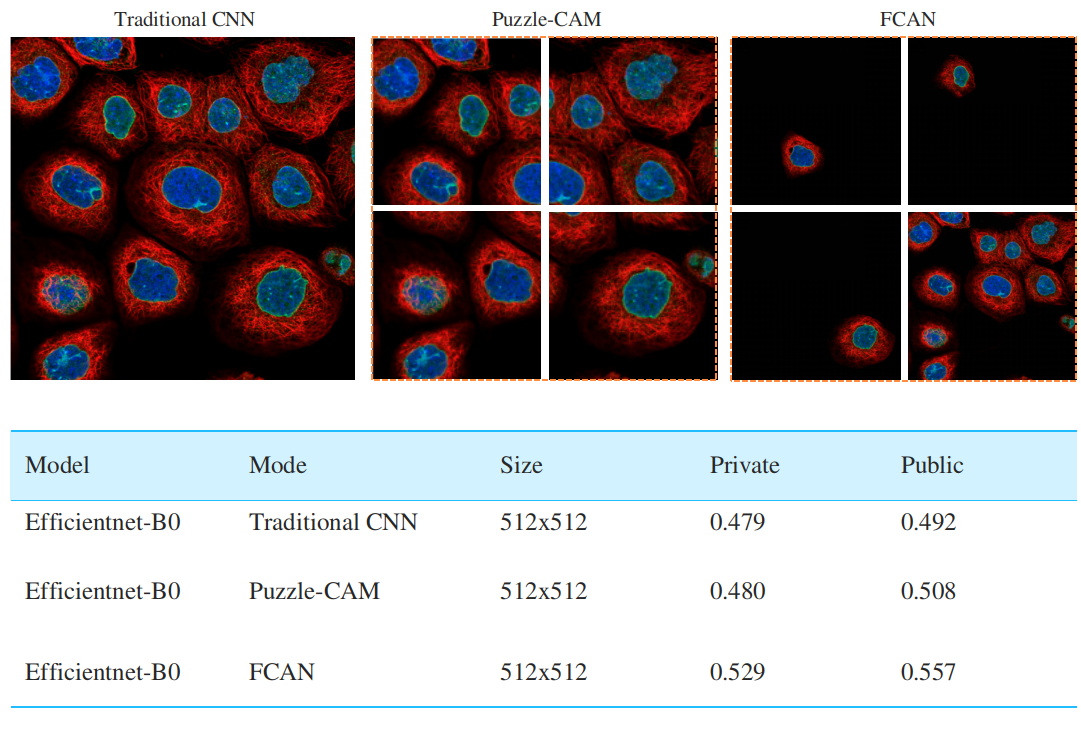
模型真实图像对比
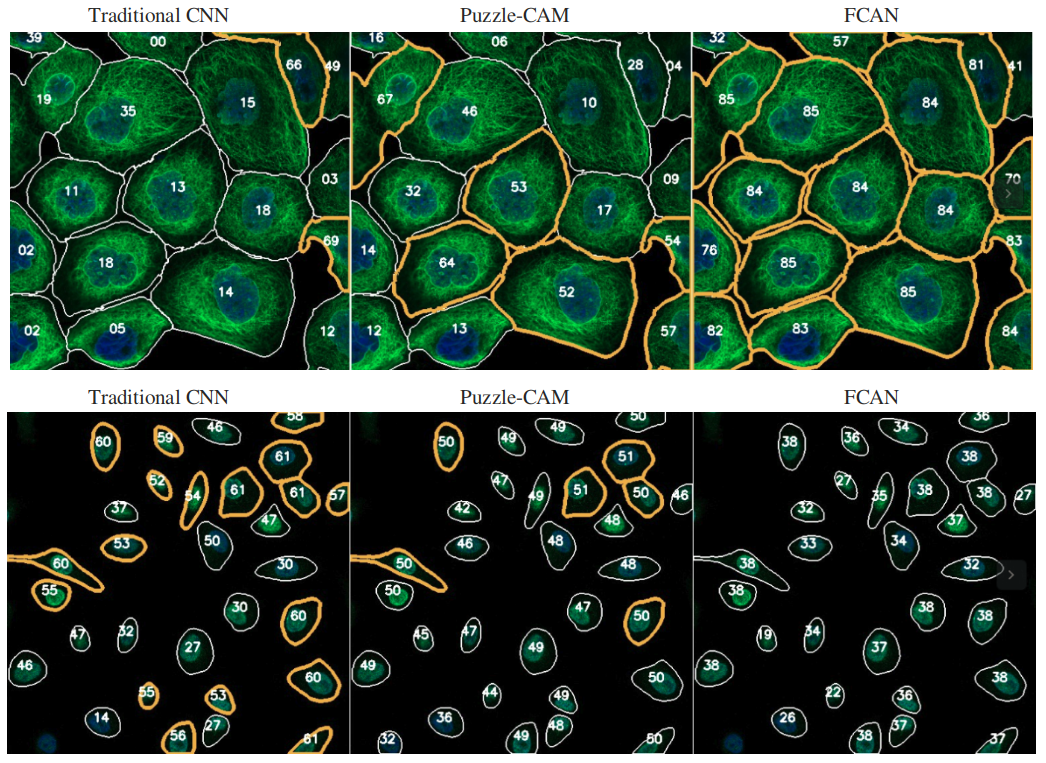
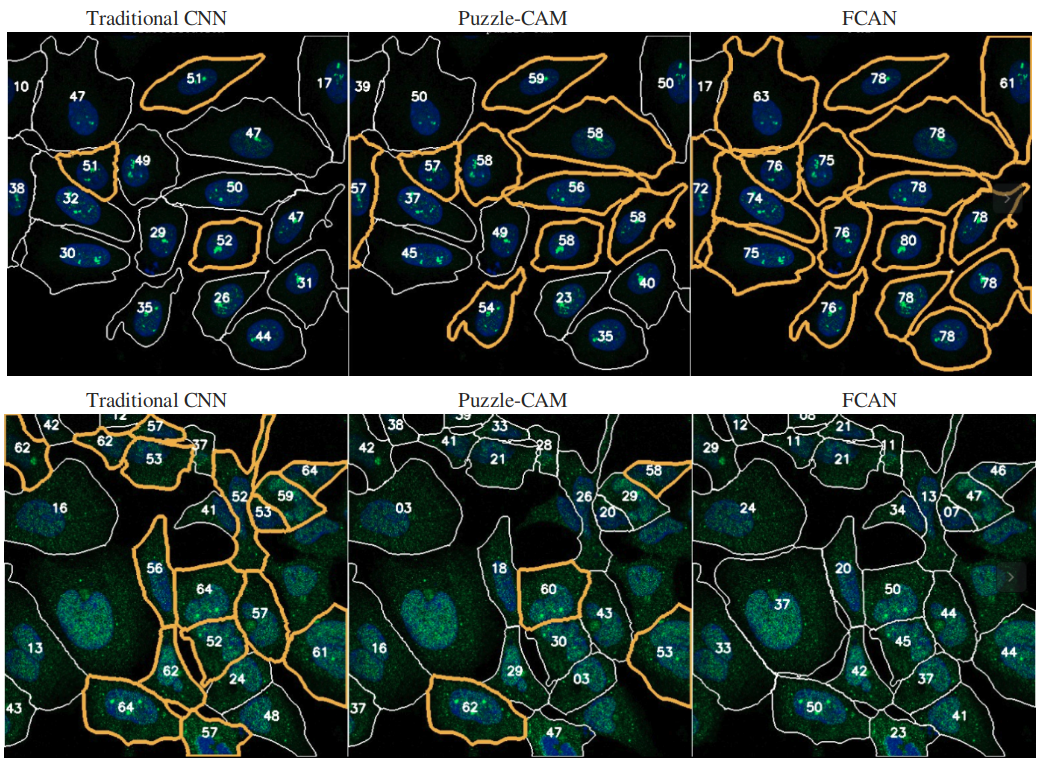

这些图像的左侧是传统 CNN 模型的结果,中间是 puzzle-cam 的结果,右侧是 FCAN 的结果。
每个图的上半部分是带有正标签的图像。底部是负图像。
每个细胞上的数字是该细胞的置信度。
2.2 基于 Swin Transformer 的细胞分类模型
数据
使用细胞分割模型裁剪图像中的细胞。
细胞被标记为 5 个等级,标签为 [1.0, 0.75, 0.5, 0.25, 0 ],这是一个基于规则的过程,在从上面介绍的 FCAN 获得训练集的所有细胞的输出后,如果图像概率和细胞概率高,我们可以给出更高的标签值,并且来自标签为 A 的图像的细胞被赋予至少 0.25 的