第23名 银牌 - 平衡随机数据加载器
感谢 Kaggle 和 HuBMAP 举办了一场有趣的比赛。本次比赛的挑战在于设计一个能够处理大图像的训练数据加载器,以及编写一个能够处理大图像的成功推理笔记本。
训练数据加载器
我的训练数据加载器在每个 epoch 中从 15 张训练图像中各选择 128 个随机裁剪块。因此,它平衡了每张训练图像的贡献(它不会给予较大的训练图像更多的关注),因为我们不知道私有测试集中的图像是什么样子的。
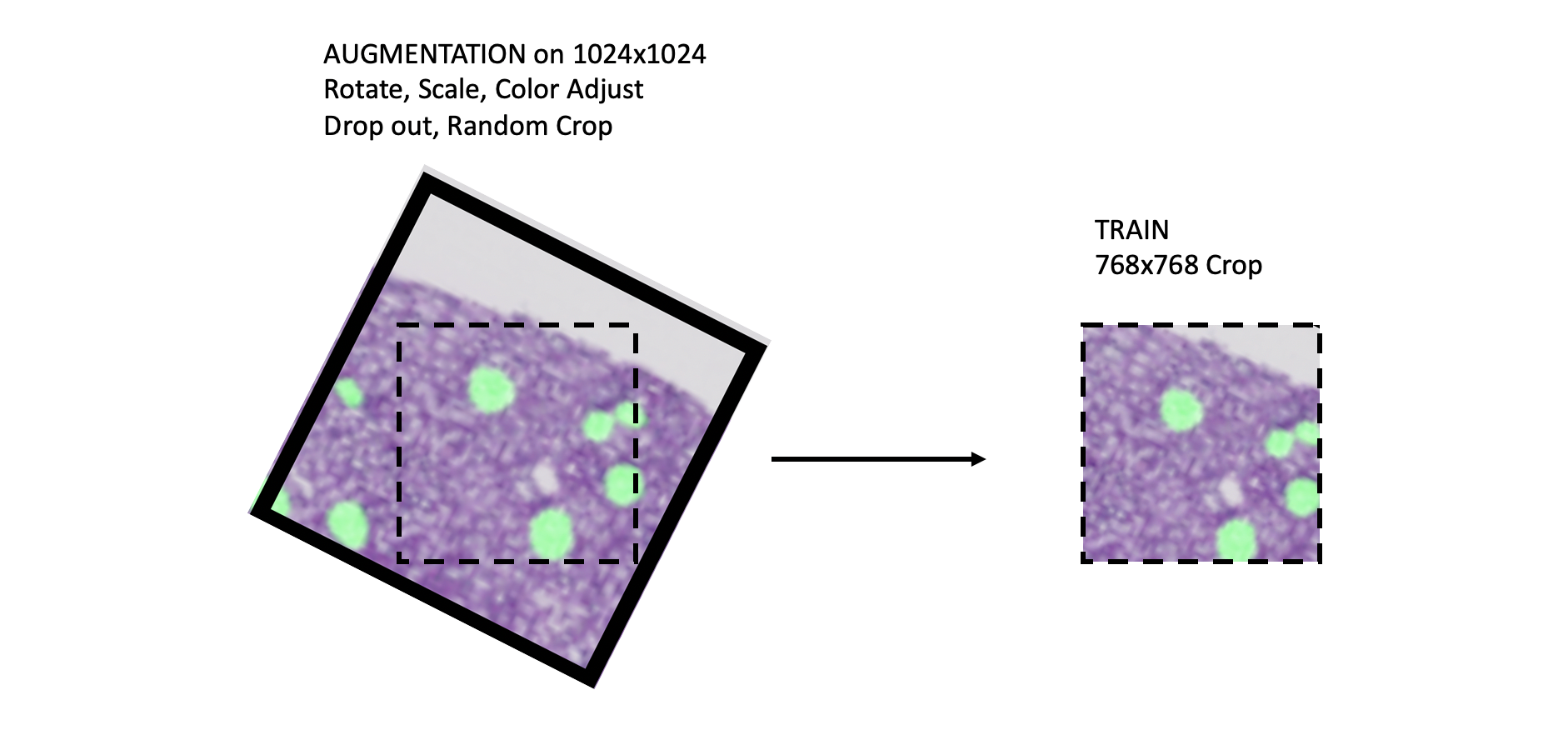
此外,训练图像首先通过 Numpy 技巧进行 2 倍、3 倍或 4 倍的下采样,例如 image = image[::2, ::2, ]、image = image[::3, ::3, ] 等。最后,数据加载器保证每个 1024x1024 的裁剪块至少包含 1 个分割标签。(如果不包含,则重新随机选择)。

之后,在 1024x1024 的裁剪块上应用 Albumentations 数据增强:
composition = albu.Compose([
albu.HorizontalFlip(p=0.5),
albu.VerticalFlip(p=0.5),
albu.ShiftScaleRotate(rotate_limit=25, scale_limit=0.15, shift_limit=0, p=0.75),
albu.CoarseDropout(max_holes=16, max_height=64 ,max_width=64 ,p=0.5),
albu.ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.25, p=0.75),
albu.GridDistortion(num_steps=5, distort_limit=0.3, interpolation=1, p=0.5),
albu.RandomCrop(height=768, width=768, p=1.0)
])最后,数据加载器从增强后的 1024x1024 随机裁剪块中提取一个 768x768 的随机裁剪。
模型采用 FPN 结构,主干网络为 EfficientNetB2,损失函数为 bce jaccard loss:
import segmentation_models as sm
def build_model():
inp = tf.keras.Input(shape=(None,None,3))
base = sm.FPN('efficientnetb2', encoder_weights='imagenet',
classes=1, activation='sigmoid')
x = base(inp)
opt = tf.keras.optimizers.Adam()
model = tf.keras.Model(inputs=inp, outputs=x)
model.compile(
optimizer=opt,
loss=sm.losses.bce_jaccard_loss,
metrics=[sm.metrics.f1_score]
)
return modelNvidia 4xV100 32GB
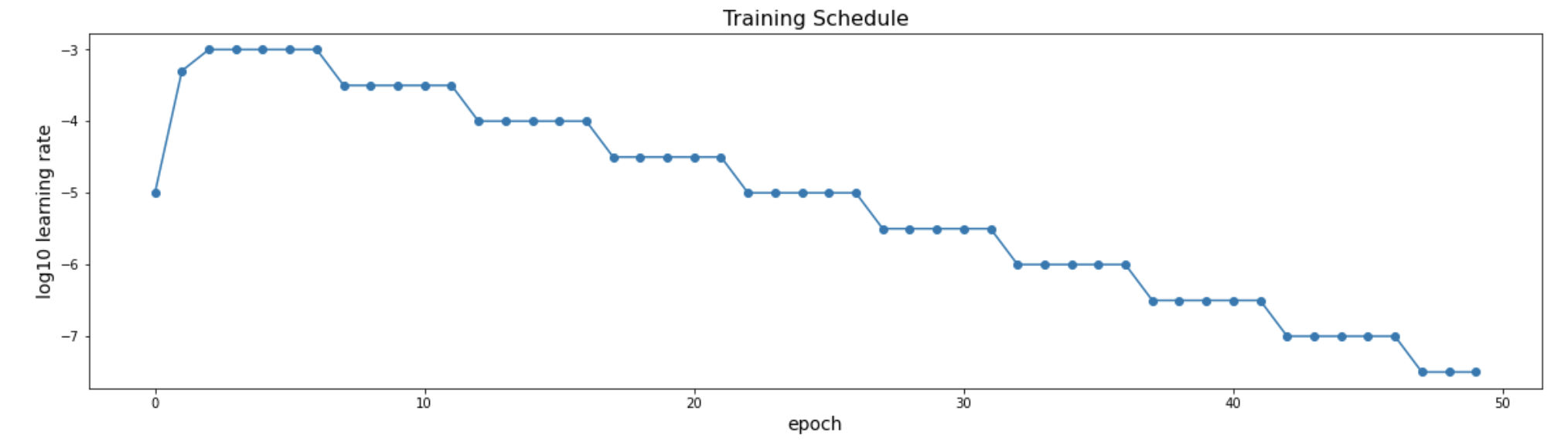
使用四块 Nvidia V100 32GB 显卡,模型训练了 50 个 epoch,批量大小为 24,图像大小为 768x768。
model.fit(train_gen(batch_size=24, image_size=(768,768)), epochs=50,
callbacks=[lr], use_multiprocessing=True, workers=4)
model.save_weights('model_weights.h5')每个 epoch,数据加载器都会从每张训练图像中随机选择 128 个裁剪块。训练使用以下学习率策略。每个 epoch 只需要几分钟。
模型集成
没有使用折交叉验证。模型使用 100% 的训练数据进行训练。一个模型使用 2 倍下采样图像训练,一个模型使用 3 倍下采样图像训练,还有一个模型使用 4 倍下采样图像训练。之后,使用 EfficientNetB0 主干网络重复此过程(图像大小 1280x1280 缩减为 1024x1024,批量大小为 16)。这 6 个模型集成后达到了公开 LB 0.920 和