第二名方案 (通过 GAT 和 LGB 进行匹配预测)
恭喜所有获奖者,感谢主办方举办了如此精彩的比赛!
感谢我的队友 @tkm2261 的巨大贡献!
我们的提交代码已发布在 https://www.kaggle.com/lyakaap/2nd-place-solution
摘要
这是一场涉及多模态数据的有趣比赛。
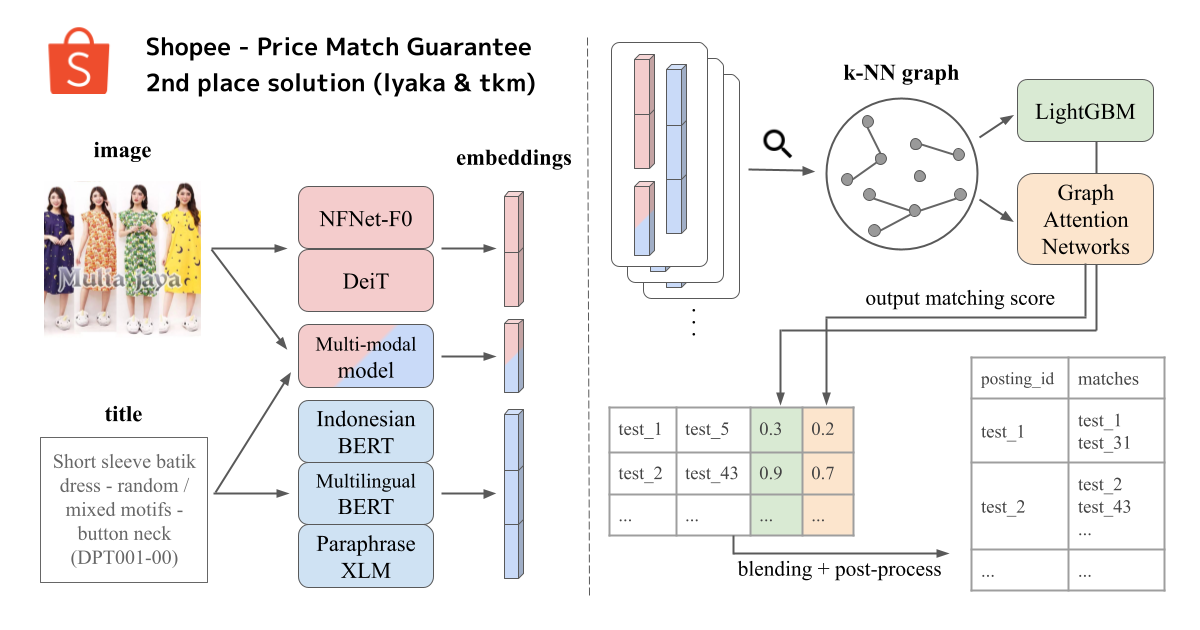
我们流程的概述如下:
- 第一阶段: 训练度量学习模型,以获取图像、文本和图像+文本数据的余弦相似度。
- 第二阶段: 训练“元”模型,对一对项目是否属于同一标签组进行分类。
- 使用了 LightGBM 和 GAT (图注意力网络)。
我们发现融合 lyakaap 和 tkm 的模型带来了巨大的提升。当我们合并队伍时,我们的分数分别是 0.767 和 0.765。令人惊讶的是,合并后的分数达到了 0.777。实际上,我们也不确定为什么分数会有如此大的提升。
我们将在下面详述我们的解决方案细节。如果您发现了一些可能性,请告诉我们 :-)。
特征工程
图像相似度
- NFNet-F0, ViT 嵌入的余弦相似度。
- 损失函数:CurricularFace (优于 ArcFace 和其他)。
- 优化器:SAM (优于 Adam, SGD 和其他)。
- 拼接相似度,例如:
F.normalize(torch.cat([F.normalize(emb1), F.normalize(emb2)], axis=1))。
文本相似度
- Indonesian-BERT, Multilingual-BERT, 和 Paraphrase-XLM 嵌入的余弦相似度。
- TF-IDF,正如许多公共内核中所使用的。
多模态 (图像 + 文本) 相似度
- 使用 NFNet-F0 和 Indonesian BERT 训练的模型 (在最终特征层拼接)。
图特征
- 每个项目 Top-K 余弦相似度的平均值和标准差
- K=5, 10, 15, 30 等。
- 归一化平均值,使其 mean=0, std=1
- 用于处理训练集和测试集之间的分布差异。
- Pagerank。
杂项
- 文本长度。
- 单词数量。
- Levenshtein 距离 (编辑距离)。
- 图像文件大小。
- 图像的宽度和高度。
- 查询扩展
- 获取一个加权平均邻居的增强嵌入。
- 拼接原始嵌入和增强嵌入,例如:
F.normalize(torch.cat([F.normalize(orig_emb), F.normalize(qe_emb)], axis=1))。 - 它使我们的分数提高了 0.001。
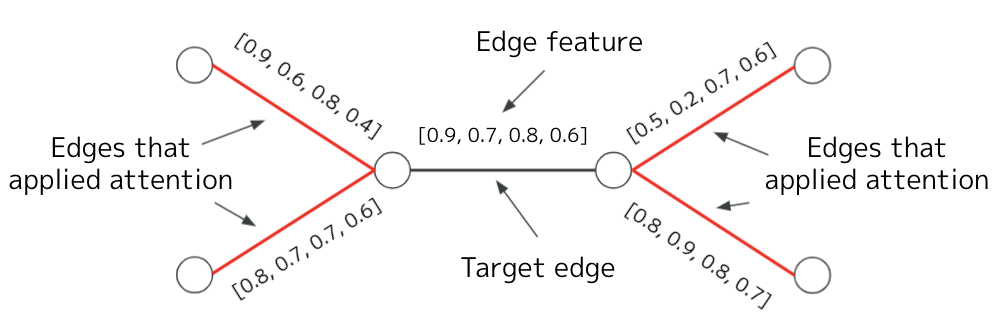
图注意力网络
- 构建一个基于图注意力网络 的模型
- 选择 GAT 的原因是其简单性和可定制性。
- 仅使用 4 个特征:image/bert/multi-modal/tf-idf 相似度。
- 将图注意力应用于“连接到目标边的节点所连接的其他边”作为邻域。
基于图的后处理
- 递归移除具有最高介数中心性的边 (项目匹配)。