我要感谢我的队友 @matthieuplante 和 @seb6084 邀请我加入他们的团队。我一直想学习更多关于目标检测的知识,而我的队友们是完美的老师。
当我一周前加入他们时,他们已经有了完整的流程来训练 VFNet、YoloV5、EfficientDet4 等模型!我们一起调整了模型,构建了一些分类器模型,并使用加权框融合和贝叶斯统计将所有内容集成在一起!
相信你的交叉验证(CV) - mAP 0.488
我们的最终解决方案是三个目标检测模型的集成:
- VFNet,输入 1024x1024,推理 800x800 - CV mAP 0.463,Public LB 0.287,Private LB 0.289
- Yolov5,输入 1024x1024,推理 768x768 - CV mAP 0.464,Public LB 0.268,Private LB 0.290
- EfficientDet4,输入 1024x1024,推理 1024x1024 - CV 0.460,Public LB 0.237,Private LB 0.282
以及三个15类分类器(即15个二分类输出),集成的“无发现”类别 CV AUC 为 0.9934:
- EfficientNet B4,输入 512x512 - 针对“有发现/无发现”输出的 CV AUC 为 0.990
- EfficientNet B4,输入 768x768 - 针对“有发现/无发现”输出的 CV AUC 为 0.991
- DenseNet201,输入 768x768 - 针对“有发现/无发现”输出的 CV AUC 为 0.991
关于如何集成折和模型,以及如何将目标检测模型与分类器模型结合的所有决定,都是通过本地验证确定的。
通过集成,我们获得了 0.488 mAP 的验证分数,Public LB 0.272,以及 Private LB 0.296。为了用我们的验证集模拟测试集,我们随机只保留每张图像每个类别的一位医生的预测,否则验证将不像 LB 评分那样。
竞赛指标类似于 AUC
对于给定的类别,你预测的每个边界框置信度分数都需要从最可能到最不可能进行排序。就像 AUC 指标一样。这不是针对每张图像,而是针对每个类别的整个 CSV 文件。如果你预测类别 0 总共有 30,000 个边界框,那么所有 30,000 个边界框的置信度分数都需要正确排序,从最可能是类别 0 到最不可能是类别 0。
边界框置信度分数的顺序很重要
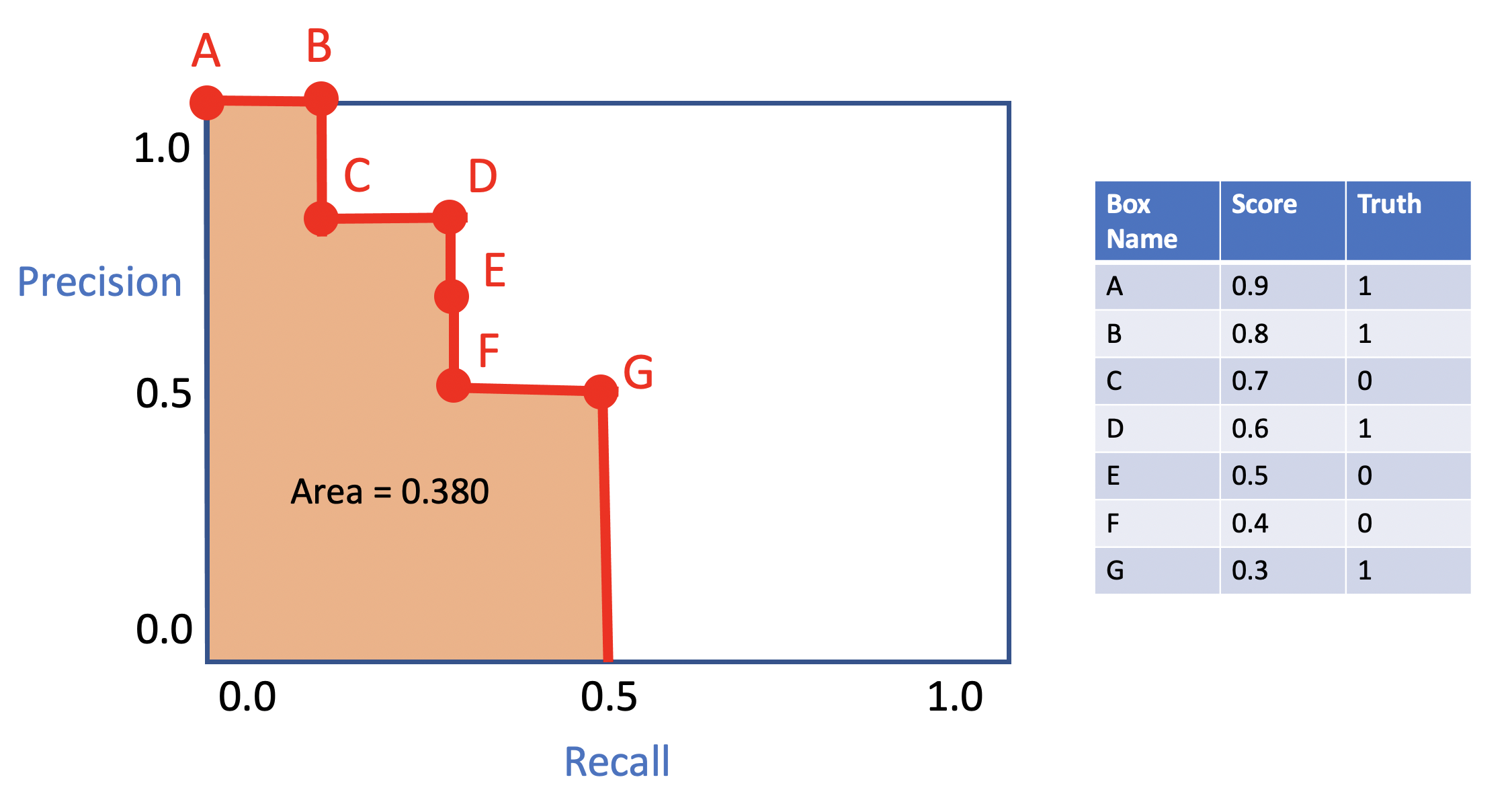
只需调整边界框的置信度分数而不改变它们的 xmin、xmax、ymin、ymax,你就可以提高你的 CV 和 LB 分数!在下面的例子中,整个图代表 1 个类别,每个点代表 1 个边界框,数字是置信度分数。如果更改边界框 D 和 G 的置信度分数,该类别的 mAP 会增加 +0.12!!因此,校准边界框概率非常重要。
顺序 1
顺序 2
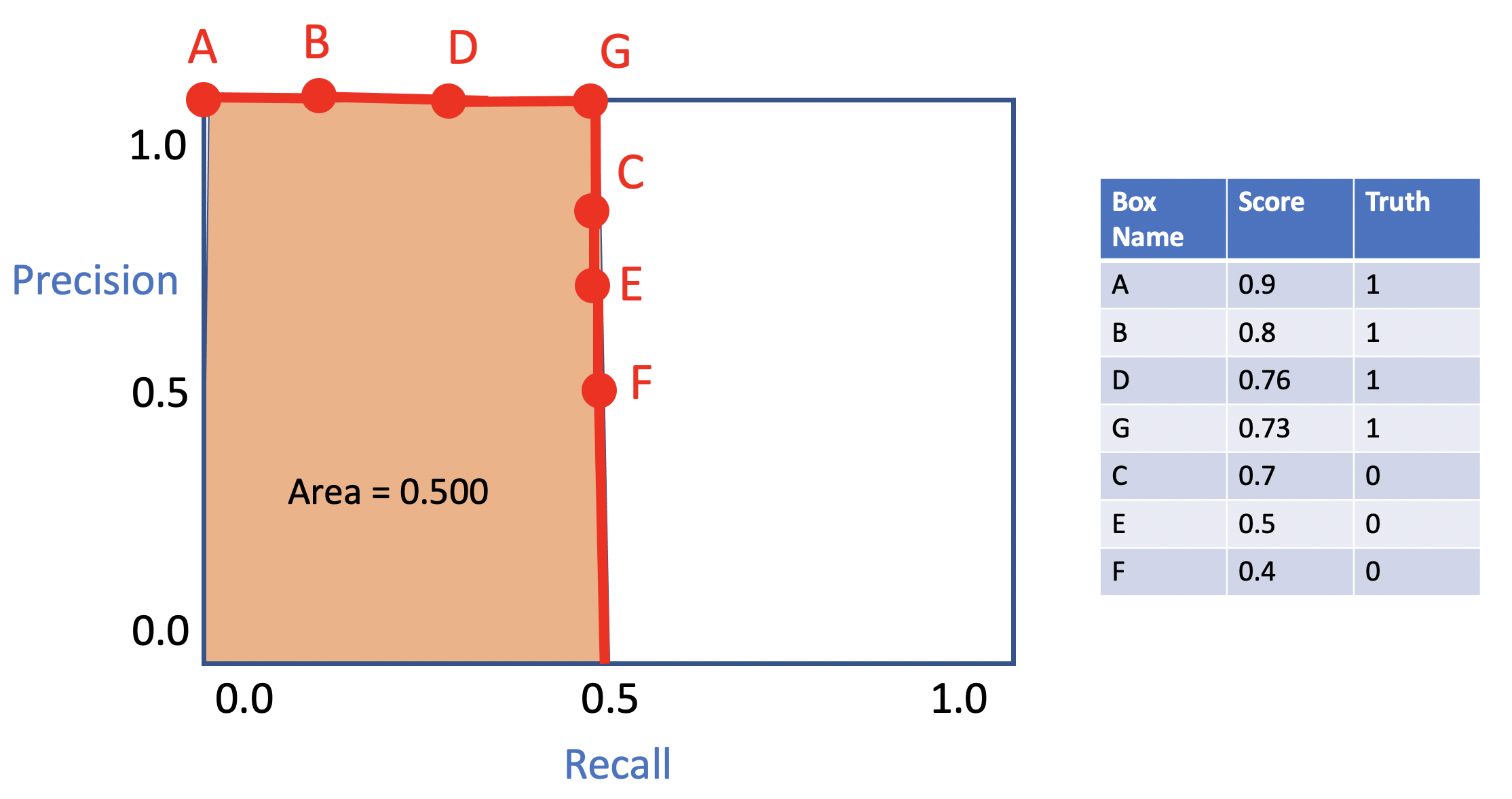
添加更多边界框没有惩罚
如果你添加新的边界框,且其置信度分数低于该类别在整个 CSV 文件中的最低置信度分数,那么你的 CV LB 只会增加,不会减少!因此,与其移除边界框,不如校准概率,即降低不太可能的边界框的概率。
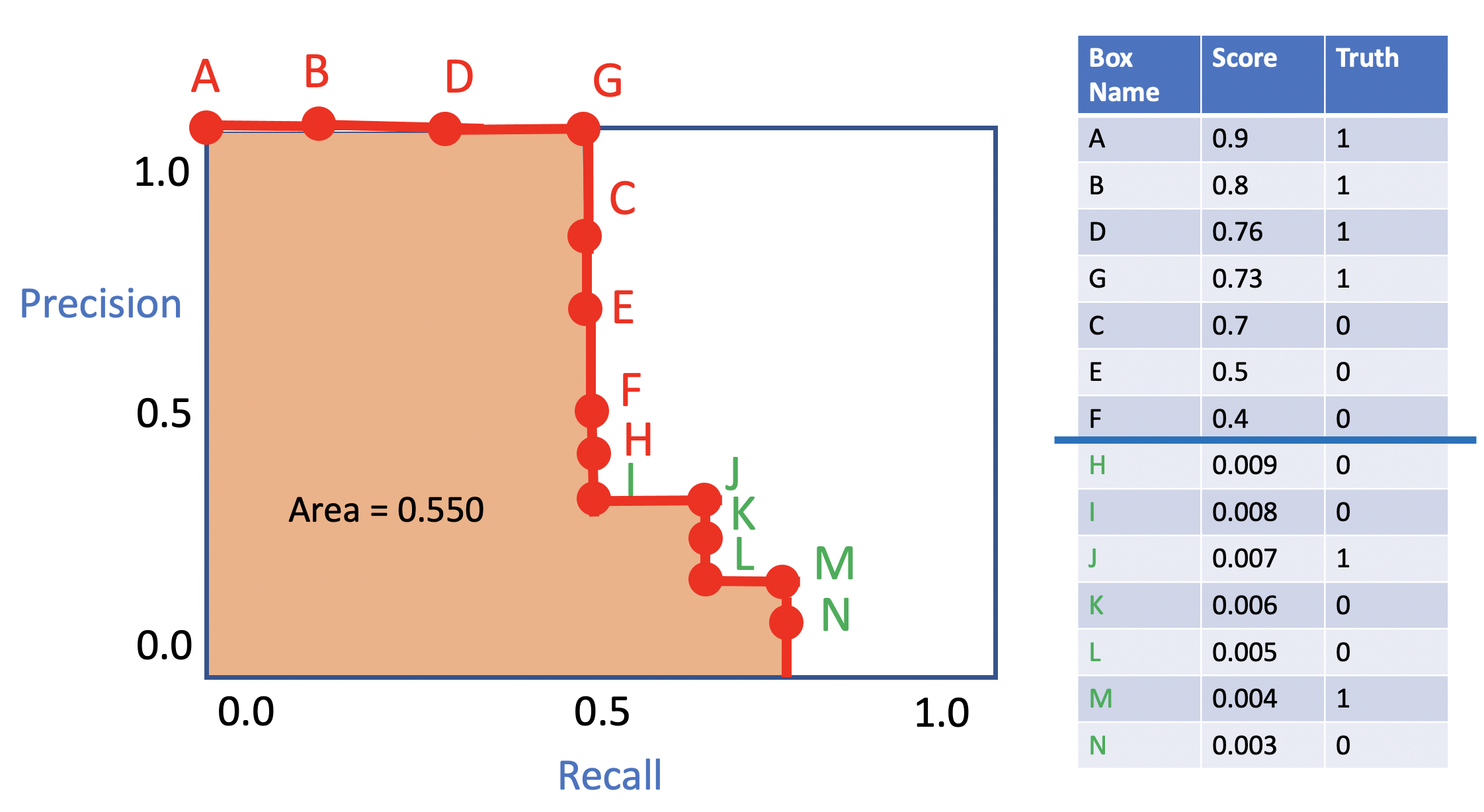
校准置信度分数
训练目标检测模型最有效的方法是移除所有没有任何边界框的图像。这样做之后,你的目标检测模型将预测一个置信度分数等于:
$$ \text{