第5名解决方案
很抱歉分享得这么晚,因为我当时正在参加另一场比赛。
我已经制作了图表,但附件功能被禁用了,等该功能恢复后我会编辑这篇帖子。
概述
我的训练流程可以分为三个步骤。在第一步中,模型最初使用所有11个目标进行了数十个epoch的训练,我们可以将其视为某种预训练或热身。在第二步中,基于三种类型的导管线(即ETT、NGT和CVC),将训练好的模型拆分为三个专家模型。为了简单起见,“Swan Ganz Catheter Present”被合并到CVC模型中。在第三步中,每个专家模型对NIH数据独立执行伪标签生成,并进行了几个epoch的微调。在推理时,每个专家模型负责预测其训练时对应的标签子集。
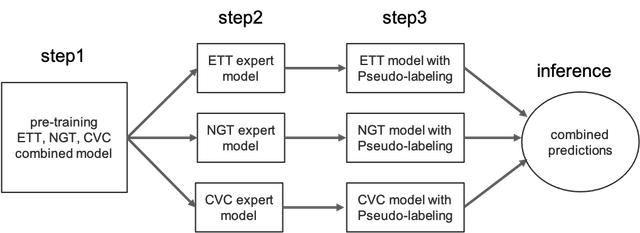
第一步与正则化
为了获得更好的结果,对神经网络的训练进行正则化并强制其关注导管线和端点非常重要,特别是在输入图像尺寸不够大的情况下。在我的工作中,我利用了 train_annotations.csv 作为分割掩码。为了更经济,我没有训练一个完整的分割模型,而是选择缩小分割掩码的尺寸,并让CNN的倒数第二个块将其作为辅助任务进行拟合。由于我们知道每张图像只有一个ETT,因此没有必要在分割掩码中绘制ETT。相反,对于每张图像,我从注释文件中提取ETT的端点作为具有两个值的单点,并添加了一个回归任务来指导ETT的训练。因此,分割掩码只包括CVC、NGT和SWAN,所有这些线都绘制在一个掩码中,我们可以使用一个1x1卷积层来连接特征图和掩码。在比赛后期,Konya博士分享了他的“5k气管分叉注释数据集”。这可以作为额外的地标或参考点,因此我添加了一个额外的回归头,强制网络预测气管分叉。在所有这些正则化任务中,训练期间会忽略没有注释的损失。下图总体展示了我的CNN训练情况。layer1、layer2……的命名更多是resnet实现的命名约定。左上角的子图代表了第一步的训练。
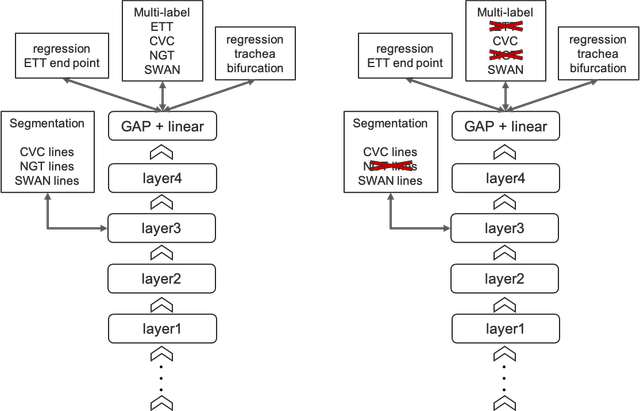
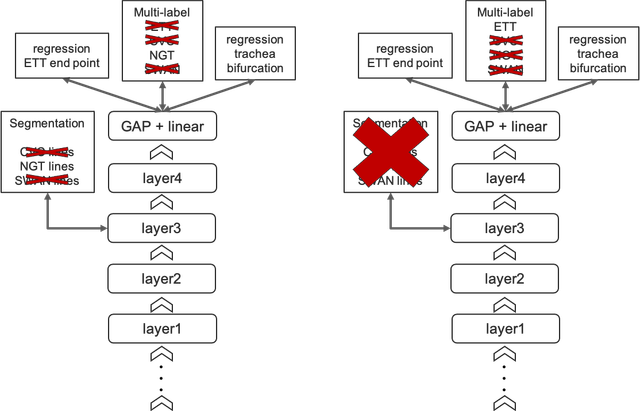
第二步:专家模型
我对第二步的最初想法只是微调来自不同epoch的第一步模型,因为不同类型的线可能在不同的epoch收敛。后来,我发现通过仅使用特定线类型的目标,性能可以进一步提高。如果将所有目标一起训练,优化过程中可能会存在一些干扰。因此,我调整了目标以及正则化任务,并训练了三个专家模型。详情可以在下图中找到。我在图中划掉了专家模型中不相关的部分。

第三步:伪标签
既然我们知道所有的私有测试数据都在NIH数据中,利用它们进行伪标签生成是很自然的。在第三步中,我首先使用imagehash将本次比赛的训练数据从NIH数据中排除,然后我在剩余的NIH数据(应该包含所有测试数据)上,用每个专家模型生成伪标签。由于添加这些感兴趣的线不存在的数据没有太大用处,我使用相关预测的总和进行过滤。例如,我将三个CVC预测值相加,并将其与阈值进行比较,以仅接受存在CVC的数据。对于CVC,大约有25000条额外数据被筛选出来用于伪标签;有趣的是,ETT或NGT只剩下大约2500条数据,这意味着与比赛数据中的测试/训练比例相比,这个比例要小得多。
模型与结果
我创建了一个6折划分,并设法完成了其中4折的模型训练。这四个模型是三个resnet200d和一个efficientnet-b7,图像输入尺寸为672x672。结果为:CV:0.9712,公共LB:0.9682,私有LB 0.9756。我的公共成绩比预期低很多。在比赛期间这有点令人沮丧,因为我看到许多参赛者很早就轻松获得了更好的分数。我检查了很多次我的提交内核,没能发现任何问题。我很高兴我在这段旅程中没有放弃。