[已完成] 13天内排名第19的解决方案 - LB 0.937/0.939 (公开/私有) 5折模型
[摘要]
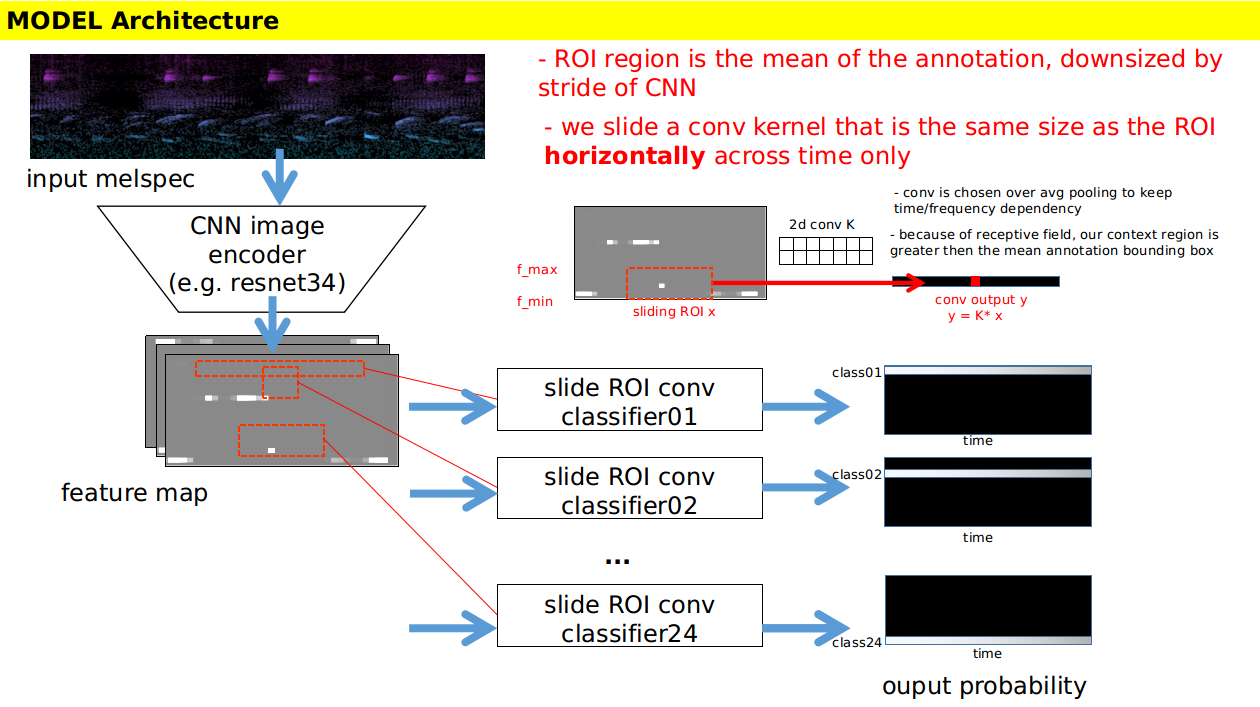
- 设计了一个滑动窗口卷积分类器网络。在 ResNet34 上使用 TP(真阳性)和 FP(假阳性)标注进行训练(未使用伪标签),该架构在 5 折模型中达到了 LB 0.937/0.939(公开/私有)。单折模型的得分为 0.881/0.888(公开/私有)。移除了 ResNet34 的第一个最大池化层,使主干的步长变为 16(而不是 32)。
- 最终提交的 LB 为 0.945/0.943(公开排名第 15/私有排名第 19),是该网络与不同 CNN 主干的集成结果。
感谢 Kaggle 和主办方 Rainforest Connection (RFCx) 组织了这次比赛。
作为 Z by HP 和 NVidia 的全球数据科学大使(https://datascience.hp.com/us/en.html.HP),HP 和 Nvidia 慷慨地为我提供了一台 Z8 数据科学工作站供我在本次比赛中使用。如果没有这台强大的工作站,我不可能在 13 天内从零开始实现我的想法。
因为我可以极快的速度完成实验(Z8 配备了 Quadro RTX 8000,NVlink 96GB),当实验反馈几乎是即时的时候,我对模型训练和模型设计获得了很多见解。我想与 Kaggle 社区分享这些见解。
因此,我开启了另一个话题来指导和监督那些想要提高训练技能的 Kaggle 用户。目标是帮助他们从银牌提升到金牌水平。你可以参考:
https://www.kaggle.com/c/rfcx-species-audio-detection/discussion/220379
https://www.kaggle.com/c/hpa-single-cell-image-classification/discussion/217238
数据预处理
- 带有改进型 PCEN 去噪(逐通道能量归一化)的对数梅尔频谱图。一个 10 秒的片段具有尺寸为 128x938 的梅尔频谱。
n_fft = 2048win_length = 2048hop_length = 512num_freq = 128
数据增强
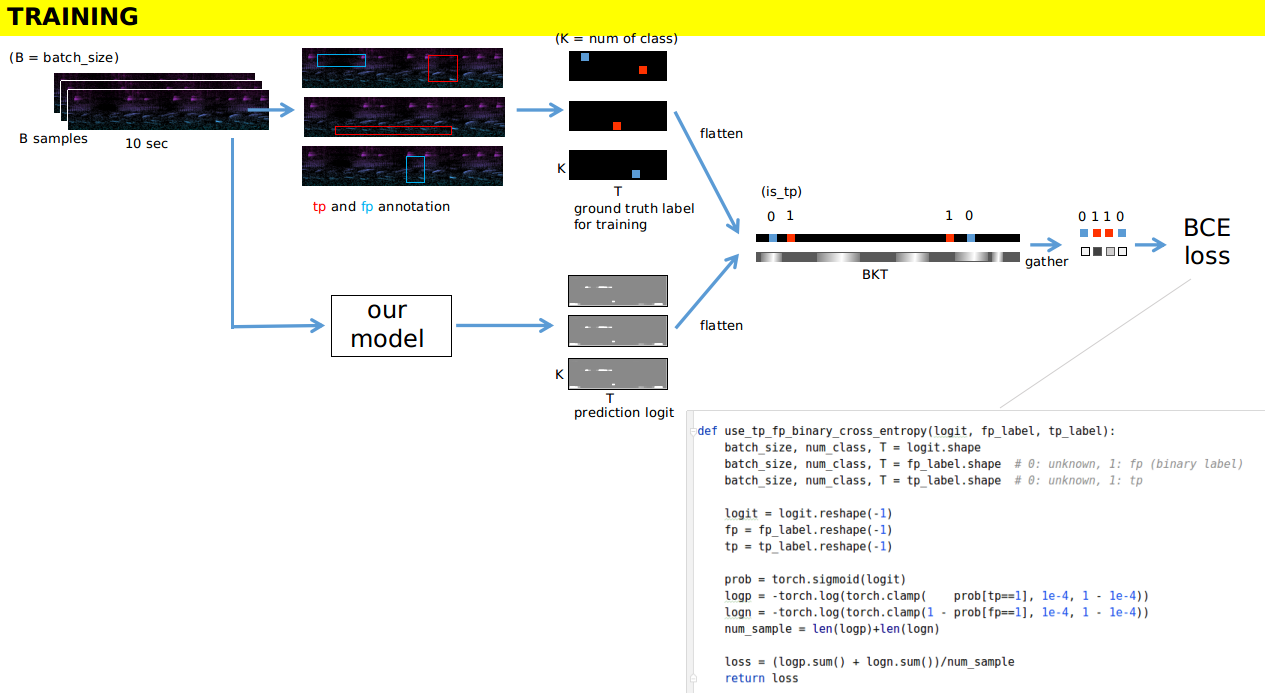
- 我还没尝试太多的增强。对于 TP 标注,随机偏移 0.02 秒。对于 FP 标注,随机偏移标注的宽度,然后随机翻转、混合、剪切和粘贴原始标注及其偏移版本。
- 增强是在时间域中完成的,因为我的代码是这样写的。(这不是最好的解决方案)
- 可以观察到,如果我增加 FP 增强,验证集 FP 的 BCE 损失会降低,公开 LB 分数也会提高。
- 模型中使用了大量的 Dropout。
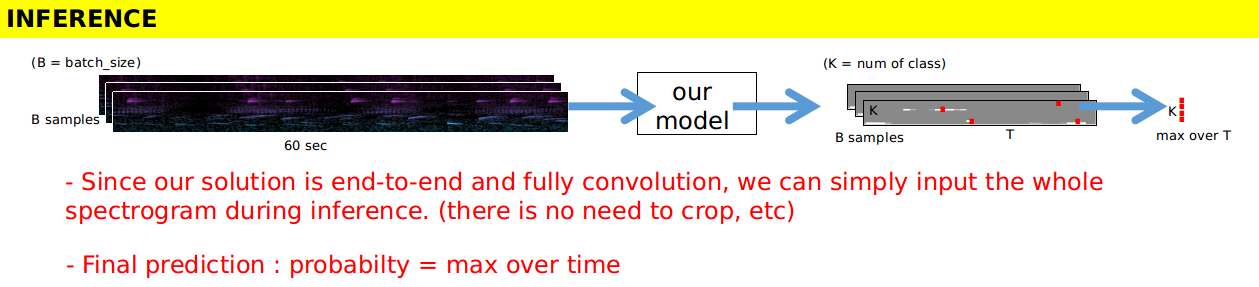
模型与损失
- 请看下方的图片。
- 在训练过程中,我分别监控验证集 TP 和 FP 的对数损失。我还使用了假设只有一个标签的 LRAP(即 Top-1 准确性)。这是为了决定何时早停或降低学习率。这些并不是最好的方法。

每日进度
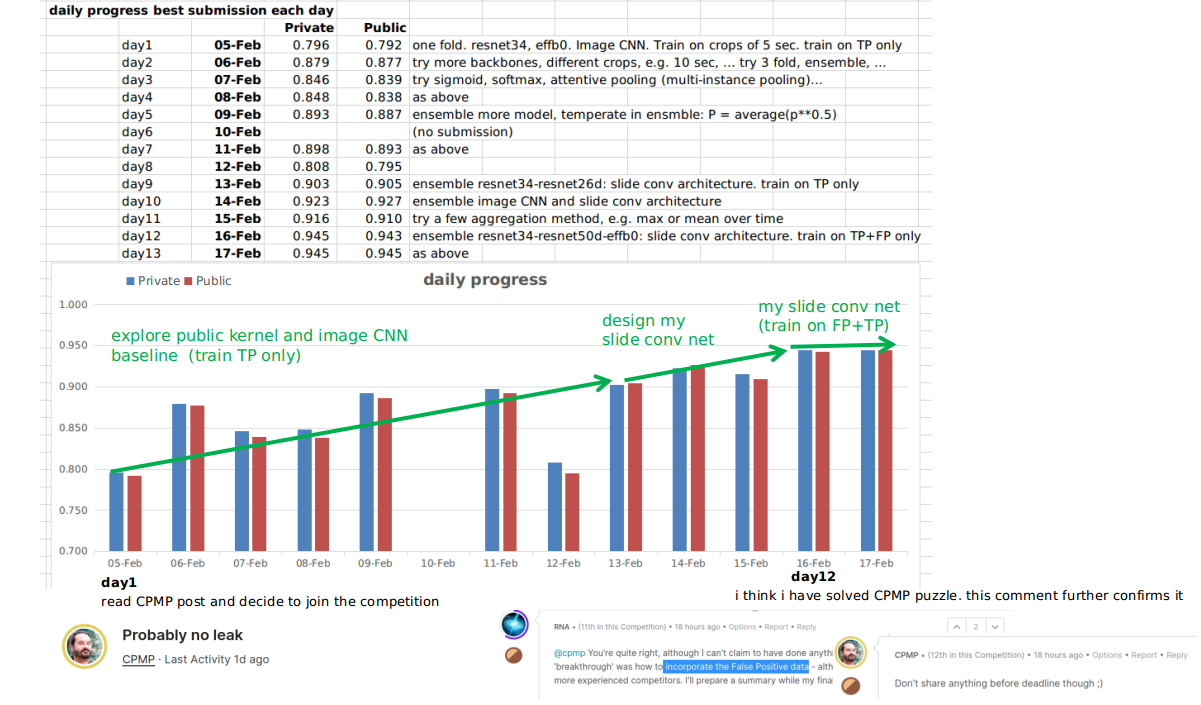
我在阅读了 CPMP 的帖子后参加了比赛,他说他在第一次提交时就达到了 0.930 LB。哇!细读之下,这意味着:
- 公开内核的做法是“错误”的。可能是问题设置、网络架构、数据或某些神奇的特征。有一些非常基础的东西可以比公开内核做得更好。