第21名方案 - FP协同教学与损失函数改进
恭喜获得顶尖名次的选手们!
我的完整解决方案在这里:https://github.com/MPGek/mpgek-rfcx-species-audio-detection-public。我保留了最终提交中使用的最佳配置。
摘要
我的解决方案摘要:
- 结合频带增强的通用增强方法:
- 频带滤波
- 频带混合
- TP(真阳性)训练:对置信样本使用BCE损失,对噪声样本使用LSoft 0.7损失的混合损失。
- FP(假阳性)训练:对置信样本使用BCE损失,忽略噪声样本的损失。
- FP协同教学训练:使用协同教学论文中描述的损失,但增加了针对高损失样本的额外损失。
- TP、FP、FP协同教学结果的集成。
声谱图与随机裁剪
在训练中,我使用了以样本为中心的10秒随机裁剪和6秒随机裁剪。
在验证和预测中,我使用了6秒裁剪,步长为2秒,并最大化输出。
对于梅尔声谱图,我使用了以下参数:
- 梅尔频带数:380
- FFT:4096
- 窗口长度:1536
- 跳跃长度:400
- 最小频率:50
- 最大频率:15000
因此,一个6秒的样本生成了一个大小为720 x 380像素的图像。
数据增强
提升LB分数的增强方法:
- 高斯噪声
- 随机裁剪 + 调整大小(尺寸减少40和20像素)
- 频带滤波 - 基于样本的f_min和f_max,我将所有低于f_min或高于f_max的梅尔频带值设为0,并使用sigmoid过渡来消除尖锐边缘。
- 频带混合 - 对于某些样本,我使用了频带滤波,然后将其与高于f_max频带的不同样本以及低于f_min频带的样本混合。这样我就得到了一张包含3个混合样本的图像。
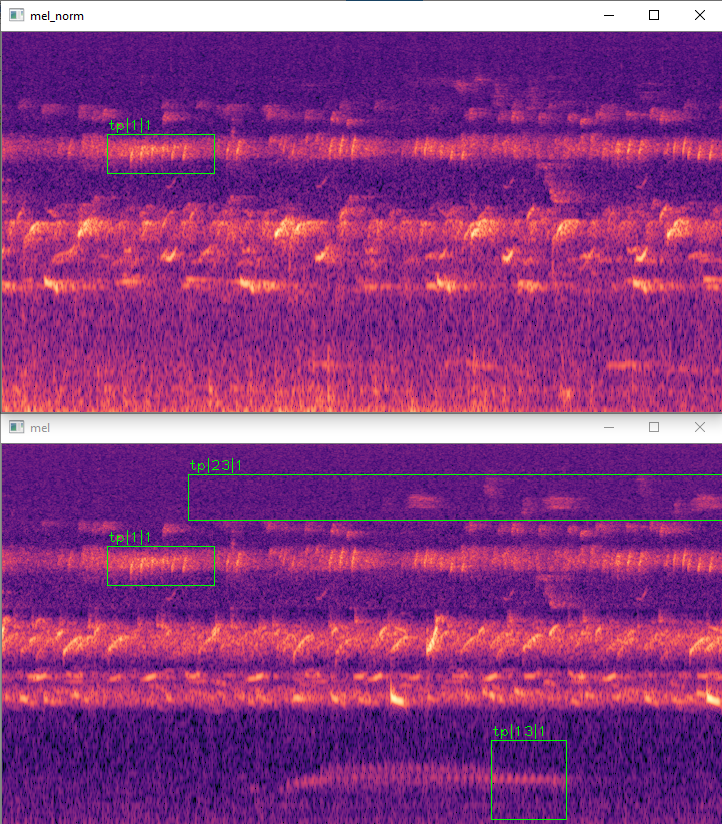
频带滤波示例(上:原始样本,下:滤波后样本):

频带混合示例(上:原始样本,下:混合后样本):
未能提升LB分数的增强方法:
- SpecAugment
- 求和混合
网络拓扑结构
我在EfficientNetB2、B4、B7(Noisy Student权重)上获得了最佳结果,在自适应平均池化后接一个简单的全连接层输出24个类别。
我尝试使用不同的头部,但它们给出的结果相同或更差:
- 超列
- 带有辅助损失的超列(每次池化后)
- 额外的空间和通道注意力块 - CBAM
- 密集卷积
TP训练
基于描述每个声音文件都可能存在未标记样本的帖子,我不得不处理噪声样本。
我将所有样本分为置信样本和噪声样本:
- 置信样本 - train_tp.csv文件中存在的类别的所有sigmoid输出(目标张量中为1)
- 噪声样本 - train_tp.csv文件中未描述的类别的所有sigmoid输出(目标张量中为0)