第43名解决方案
首先,非常感谢 Kagglers。我在讨论区从大家那里获得了很多想法,这非常有趣。
我的解决方案总结如下:
- 高分辨率的声谱图
- 使用移动平均进行后处理
- 针对缺失标签的师生模型
第一阶段:SED (声音事件检测)
我从SED的基础实验开始。为什么选择 SED?因为我认为 SED 在多标签任务中表现强劲。
我使用 log mel-spectrogram(对数梅尔声谱图)作为 SED 的输入。基础实验包括数据增强(高斯噪声、SpecAugment 和 MixUP)、骨干模型选择以及调整 log mel-spectrogram 的分辨率。结果显示,以下条件对我来说是最好的:
- 不注入噪声
- 使用 MixUp
- 最佳模型架构是 EfficientNet
- log mel-spectrogram 的分辨率越高,结果越好。
分辨率
最重要的是分辨率。最近在 Kaggle 的计算机视觉解决方案中,图像分辨率越高,结果往往越好。在声谱图中,可能也会发生同样的现象。在 mel-spectrogram 中,可以通过调整 "hop_size" 和 "mel_bins" 来改变分辨率。以下是在 ResNest50(单模型)上改变分辨率的结果。
| 分辨率 (宽-高) | Public LB 分数 |
|---|---|
| 1501-64 (PANNs 默认) | 0.692 |
| 3001-128 | 0.805 |
| 6001-64 | 0.725 |
| 1501-256 | 0.761 |
| 751-512 | 0.823 |
| 1501-512 | 0.821 |
分辨率至关重要!根据实验结果,好的分辨率是“高”且接近正方形的。751-512 看起来不错。最终,我选择了 858-850。配置如下:
model_config = {
"sample_rate": 48000,
"window_size": 1024,
"hop_size": 560,
"mel_bins": 850,
"fmin": 50,
"fmax": 14000,
"classes_num": 24
}后处理
我使用帧级输出进行提交。它包含时间和类别信息。但是帧级输出中有很多假阳性信息。因为它们没有经过长时间信息的处理。因此,帧级输出中的短事件应该被删除。我为帧级输出准备了后处理方法,即移动平均。
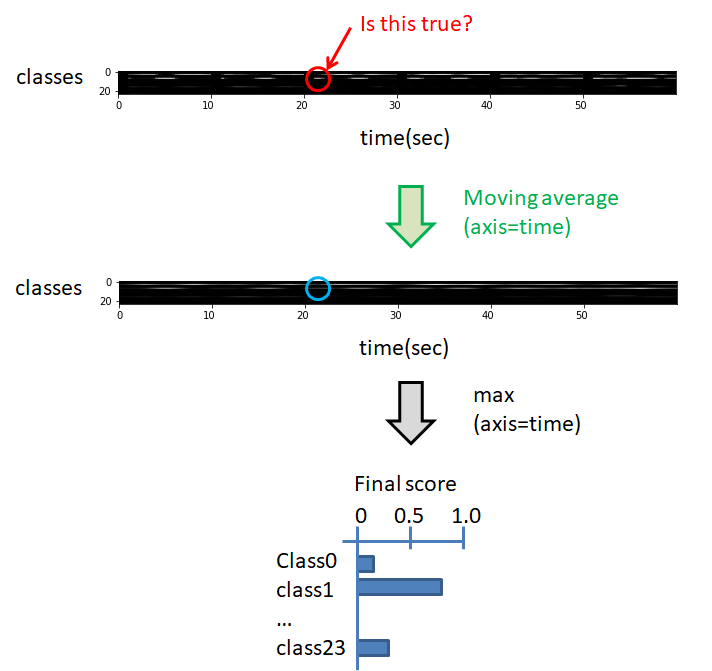
通过在每个类别的时间方向上取移动平均,我们可以删除短事件。这个想法基于该论文[1]。示例代码如下:
def post_processing(data): # data.shape = (24, 600) # (classes, time)
result = []
for i in range(len(data)):
result.append(cv2.blur(data[i],(1,31)))
return result我通过使用移动平均提高了 LB 分数。以下是比较 EfficientNetB3(单模型)后处理的结果。
| </ |
|---|