第21名方案 - 3个SAINT++模型的集成
大家好!
看到大家都在分享自己的解决方案,本着同样的精神,我们决定也分享我们的方案。
我们运行了一个修改版的 SAINT+,其中包括了讲座、标签和一些聚合特征。
我们所有的代码都在 github 上可用。我们使用了 Pytorch/Pytorch Lightning 和 Hydra。
我们的单模型公共 LB 分数为 0.808,通过集成我们将其提升到了 LB 0.810(最终 LB 0.813)。
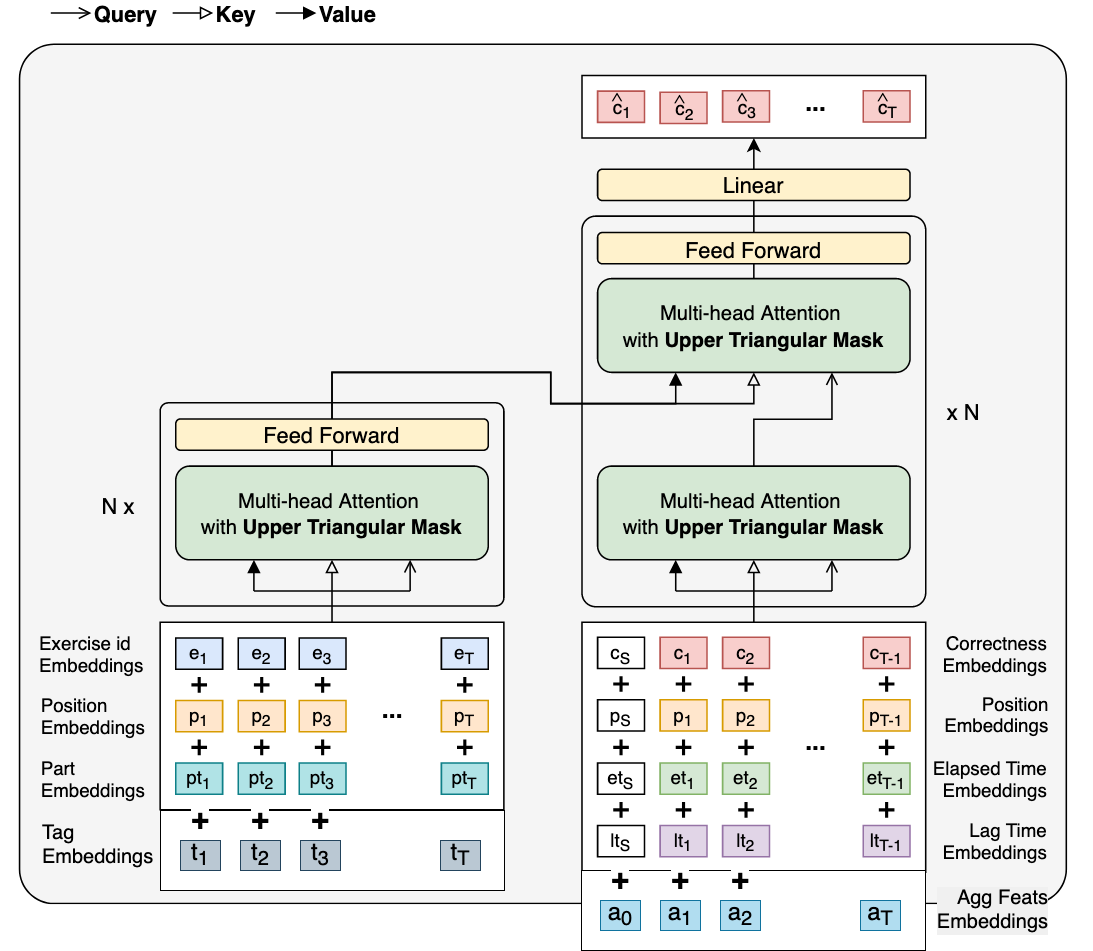
对原始 SAINT 的修改:
讲座:讲座被包含在内,并有一个特殊的可训练嵌入向量代替答案嵌入。讲座步骤的损失没有被掩盖。我们测试了包含和不包含讲座的情况,差别并不是很大。它们带来的最大好处是让一切处理起来变得简单得多,因为我们不需要过滤任何东西。
标签:由于问题最多有六个标签,我们将长度为 6 的序列传递给标签嵌入层并将输出求和。因此,我们的标签嵌入是为每个标签学习的,然后求和以获得问题/讲座中所有标签的嵌入。填充部分简单地返回一个 0 向量。
聚合特征:这是我们在公共 LB 上获得 0.002 健康提升的原因。通过在解码器中包含 12 个聚合特征,我们能够利用我们在以前 LGBM 实现中的一些经验。
聚合特征
我们使用了以下聚合特征:
- attempts:当前问题的先前尝试次数(限制在 5 次以内并归一化为 1)
- mean_content_mean:用户直到此步骤为止所见的所有平均问题准确率(总体而言)的平均值
- mean_user_mean:用户直到此步骤为止的平均准确率
- parts_mean:七维(用户在每个部分的平均准确率)
- m_user_session_mean:当前用户会话中的平均准确率
- session_number:当前会话编号(到目前为止有多少个会话)
注意:会话只是一种划分问题的方法,如果问题之间的时间差大于两小时,则划分会话。
浮点数 vs 类别型
在最后几天,我们转而使用答案的浮点表示。不幸的是,这对我们的 LB AUC 似乎影响不大,但在本地有效果。其想法是,由于我们对答案进行自回归,我们会将模型显示的不确定性传播到未来的预测中。
所有聚合特征和时间特征都是通过线性层(无偏置)运行的浮点数。它们都被归一化为 [-1,1] 或 [0, 1]。
所有其他嵌入都是类别型的。
训练:
早期产生巨大差异的是我们的采样方法。与公共内核中的大多数方法不同,我们没有采用以用户为中心的方法来采样训练样本。相反,我们只是基于 row_id 进行采样,并为每一行加载之前的 window_size 历史。
例如,如果我们采样了第 55 行。那么我们会找到该行对应的用户 ID,并加载他们的历史记录直到该行。窗口的大小将是 min(window_size, len(history_until_row_55))。
我们使用 Adam 优化器,学习率为 0.001,早停机制,并在训练期间根据 val_auc 进行学习率衰减。
验证
对于验证,我们保留了一个 250 万行的留出集(像测试集一样),并随机生成一定比例保证有新用户。我们在训练期间只使用了 250,000 行进行实际验证。
对于验证中的每一行,我们会选择 1 到 10 之间的随机推理步数。然后我们推断这些步骤,不允许模型看到真实答案并被迫使用自己的预测。
推理
在推理期间,当为单个用户预测多个问题时,我们将模型先前的预测作为答案反馈到模型中。这种自回归有助于传播不确定性并提高了 AUC。
我看到一篇文章