第20名解决方案 (公开榜第18名)
首先,感谢 Kaggle 和 INGV 主办这场有趣且充满挑战的比赛。其次,祝贺所有跻身前列的团队。同时,也要感谢那些公开基准方法的人,特别是 @carpediemamigo 和 @ajcostarino,他们的笔记本对我提高分数帮助很大。接下来,我想分享我对这个问题的解决方案。
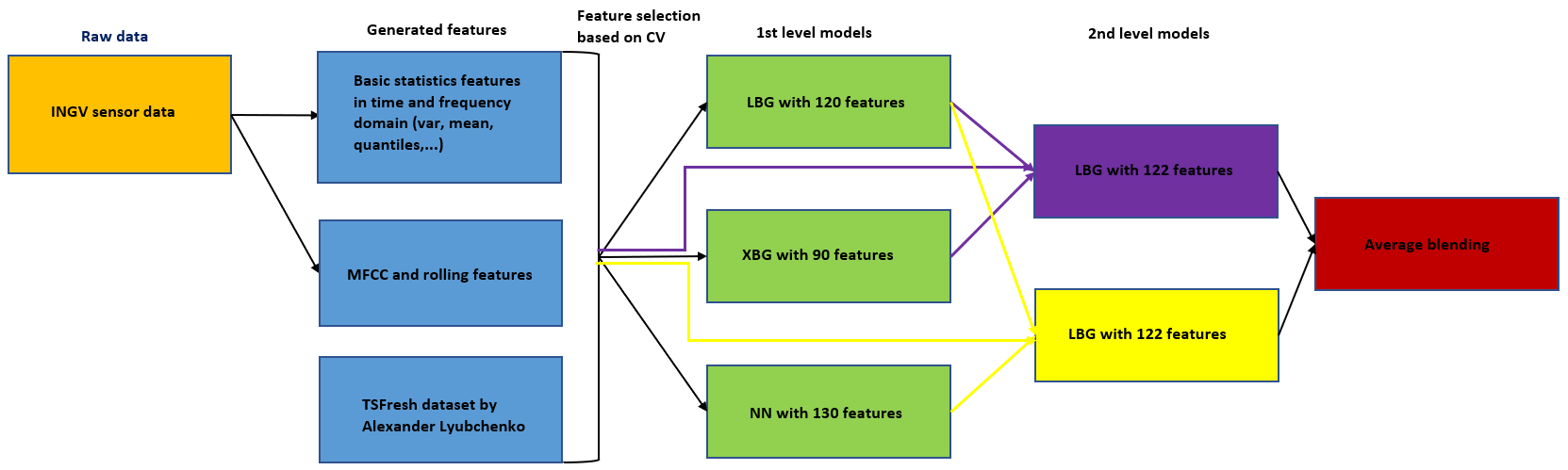
1) 特征工程
首先,我为每个传感器生成了代表基本描述性统计数据的特征,即在时域和频域(信号的傅里叶变换)中的均值、方差、分位数等。然后,我添加了一些其他特征(梅尔频率倒谱系数、在滚动窗口上计算的标准差分位数),这些特征的灵感来源于 LANL 地震预测比赛的获胜方案。最后,我使用了 @carpediemamigo 使用 tsfresh 生成的 7730 个特征。因此,我最终有大约 8000 个特征可供选择。
2) 验证和特征选择
我使用了一个简单的打乱 5 折交叉验证(CV)进行本地验证。正如许多其他参赛者所指出的,CV 和 LB(Leaderboard)之间存在巨大差异。这是因为训练集和测试集截然不同。由于两个数据集的数据点数量相似,且公开测试集约占整个测试集的 50%,这场比赛是一个我们可以高度信任 LB 分数的例子。排行榜几乎没有变动也证实了这一点。
尽管如此,我在做建模决策时还是尽量依赖 CV,因为:i) 我们每天的提交次数有限,ii) CV 的提升会转化为 LB 的提升,尤其是在开始阶段。我根据 CV 误差通过逐步前向选择来挑选特征。遵循 LANL 比赛获胜方案的直觉,我尝试使用少量的特征,最终在我的每个模型中使用了大约 100 个特征。
3) 第一层模型
虽然我尝试了许多不同的模型,但我最好的解决方案在第一层使用了三个模型:LightGBM、XGBoost 和 NN(神经网络)。其中 LightGBM 的表现最好。我保存了袋外(OOF)预测以及用于第二层堆叠模型的测试预测,并且我使用了固定的验证折。我的目标是找到性能相似但预测结果相关性不高的模型,因此这些模型通常也使用不同的特征集。
4) 第二层模型
我创建了两个第二层堆叠模型,这些模型的基础是第一层的 LightGBM 模型。
- 将 LightGBM 和 XGBoost 的 OOF 预测添加到第一层 LightGBM 模型中
- 将 LightGBM 和 NN 的 OOF 预测添加到第一层 LightGBM 模型中
5) 平均融合
最后,我对两个第二层模型的预测结果进行了平均。每个模型的误差大约在 450 万左右,但它们的相关性约为 0.95,因此平均后误差降至约 438 万。
我的建模方法可视化如下所示。代码库可以在 这里 找到。