第一名解决方案
感谢 Google 和 Kaggle 主办这次年度比赛。探索和学习有关全局、局部描述符以及匹配相似图像的算法的过程非常有趣。
简要总结
我们的解决方案是由 7 个仅使用全局描述符的模型组成的集成模型,这些模型均使用 ArcFace Loss 进行训练。我们通过对扩展版训练数据集进行 KNN 来分类地标,并利用与非地标图像的余弦相似度有效地对预测进行重排序和过滤噪声。我们没有使用任何局部描述符。
详细总结
下面我们将详细描述我们的解决方案,其中架构只是很小的一部分。
我们介绍该解决方案的视频内容可在以下链接观看:
- NVIDIA Grandmaster Series Ep2: https://youtu.be/VxNDH6qLZ_Q
- Chai Time Data Science: https://youtu.be/NRl3lMlixPc
流程管道 (Pipeline)
我们希望利用这次比赛的机会来改进我们的流程和编码技能。虽然在过去的主要在本地使用 Jupyter Notebooks 的比赛中,这次我们转向了使用带有 Git 版本控制的脚本进行协作开发。经过一段时间的适应,我们明显看到了由以下工具组成的流程带来的好处:
- Github: 版本控制和代码共享
- Neptune: 日志记录和可视化
- Kaggle API: 数据集上传/下载
- GCP: 数据存储
在实践中,我们从 Google Storage 下载预处理过的数据,使用 PyTorch Lightning 训练模型,并用 Neptune 记录日志,然后将最新版本的 Git 仓库和模型权重上传到 Kaggle 数据集,以便在推理内核中使用。这使我们能够快速进行实验和迭代。
我们计划在清理完成后在 GitHub 上发布我们的代码。
架构
我们的集成模型包含 7 个模型,使用了 timm 库中可用的以下骨干网络。我们没有使用大量的数据增强,而是使用 albumentations 在不同的图像尺度上训练模型。
- 2x seresnext101 - SmallMaxSize(512) -> RandomCrop(448,448)
- 1x seresnext101 - Resize(686,686) -> RandomCrop(568,568)
- 1x b3 - LongestMaxSize(512) -> PadIfNeeded -> RandomCrop(448,448)
- 1x b3 - LongestMaxSize(664) -> PadIfNeeded -> RandomCrop(600,600)
- 1x resnet152 - Resize(544,672) -> RandomCrop(512,512)
- 1x res2net101 - Resize(544,672) -> RandomCrop(512,512)
在将图像输入预训练骨干网络之前,我们使用 ImageNet 数据集的均值和标准差对其进行归一化。所有模型都使用 GeM 池化来聚合骨干网络的输出。我们使用一个简单的 Linear(512) + BN + PReLU 颈部网络,然后输入到一个 Arc Margin Head 中,m 值范围从 0.3 到 0.4,用于预测 81313 个地标之一。我们使用颈部网络的 512 维输出作为图像嵌入(即全局描述符)。下图展示了我们 SEResnext101 骨干网络的设置。
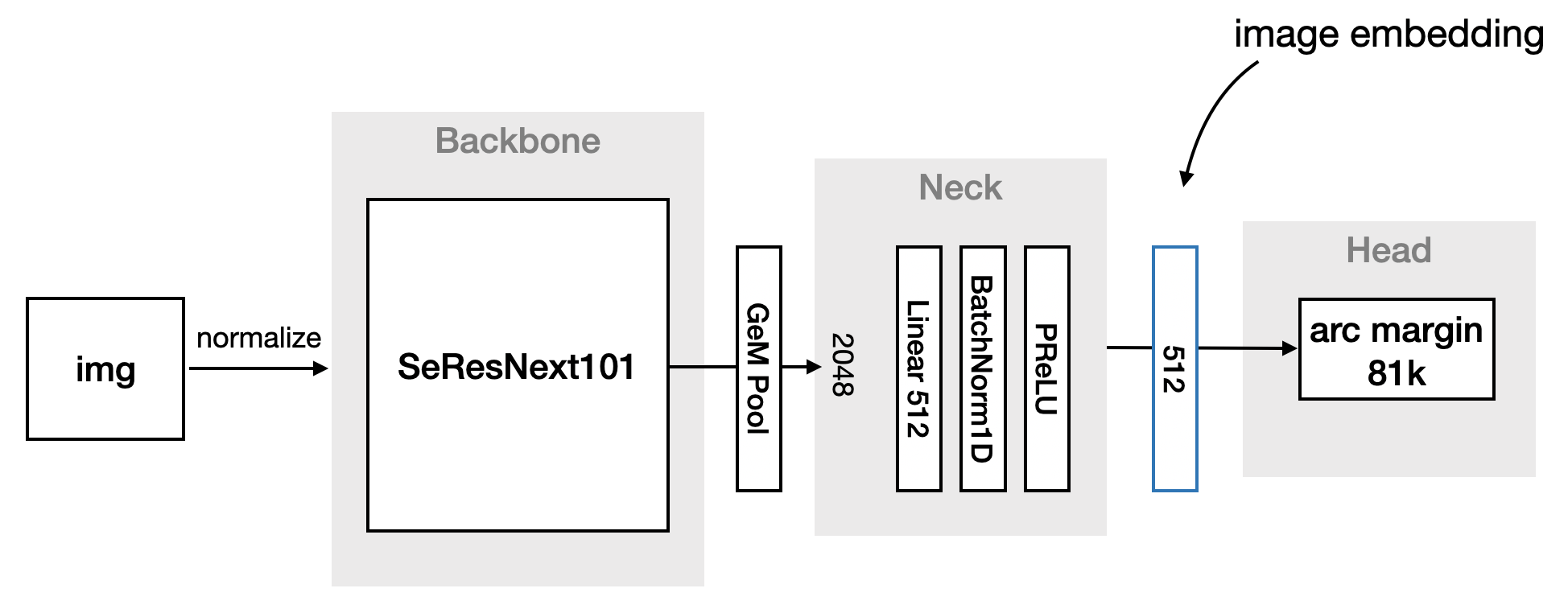
训练策略/计划
我们仅在 gldv2 clean 数据上训练所有模型。每个模型训练 10 个 Epoch,使用包含一个 Warm-up Epoch 的余弦退火调度器。我们在所有模型中使用 SGD 优化器,最大学习率为 0.05,权重衰减为 1e-4。
排序后处理
正如往届比赛所示,正确地对预测进行排序和重排序对于改善 GAP 指标至关重要,该指标对