第一名解决方案
模型
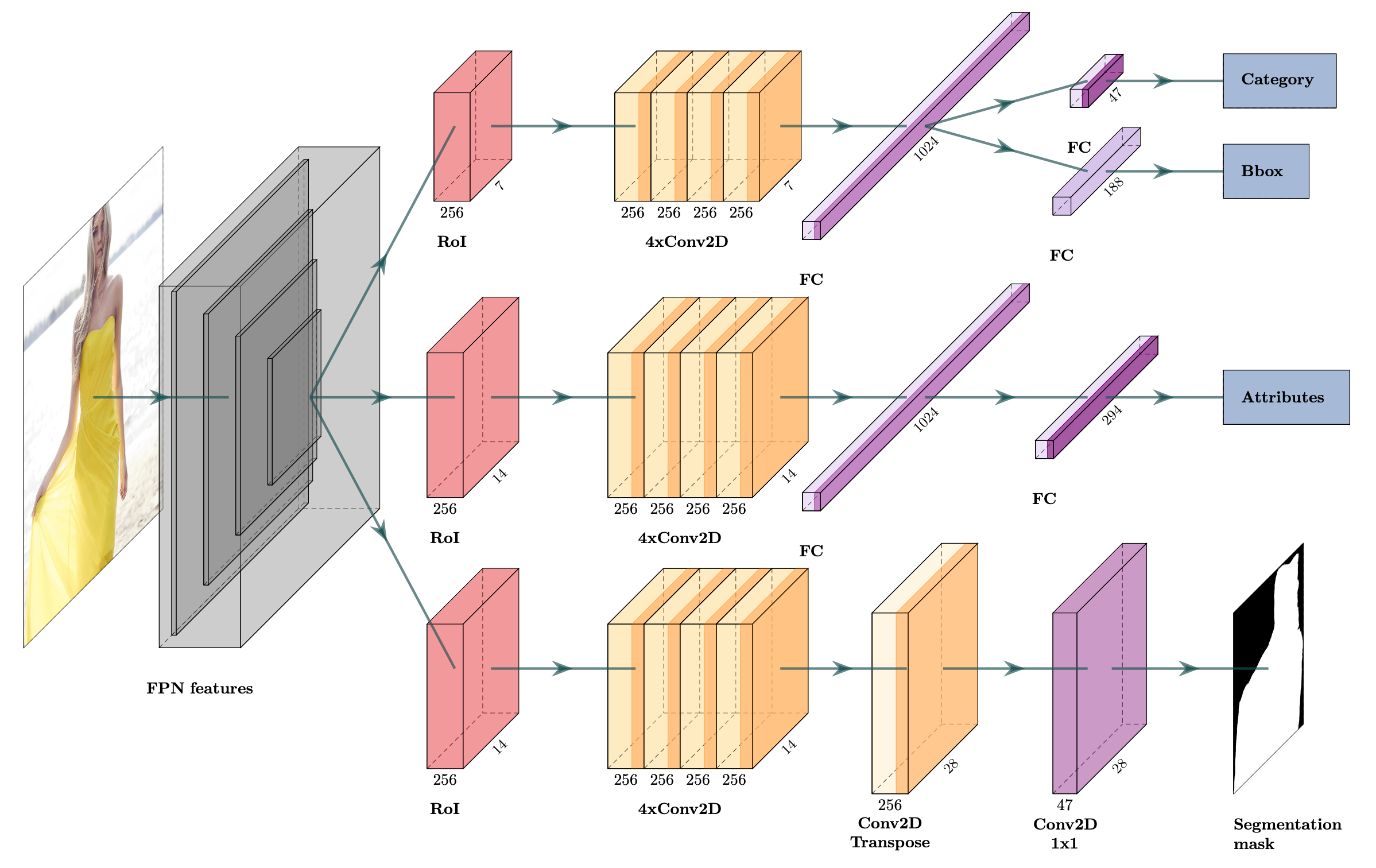
我使用了一个带有 SpineNet-143 + FPN 骨干网络的单一 Mask R-CNN 模型,并增加了一个额外的头部来对属性进行分类。属性头部使用 Focal Loss 进行训练。在数据增强方面,我使用了 AutoAugment 策略之一(详情见下文)。推理过程中未使用 TTA(测试时增强)。
所有更改均基于 TPU Object Detection and Segmentation Framework。你可以在 这个代码库 中找到最佳模型的代码和权重。
从 ResNet-50 切换到 SpineNet-96 骨干网络使我的 LB(Leaderboard)分数提高了约 +0.07(Private),+0.05(Public)。不过我不确定 SpineNet-143 骨干网络具体好多少,因为我使用了稍有不同的配置进行训练。
数据
我将训练数据拆分为训练集和验证集,拆分方式确保验证集包含每个类别和每个属性至少 10% 的图像。最终我得到了 39932 张训练集图像和 5691 张验证集图像。
训练
- 该模型是在 COCO 数据集预训练权重的基础上进行训练的。
- 训练分辨率为 1280x1280。
- 属性头部使用 Focal Loss 进行训练。切换到 Focal Loss 使分数提高了约 +0.012(Private),+0.018(Public)。
- 关于数据增强,我使用了随机缩放(0.5 - 2.0)以及 Google AutoAugment 实现中的 v3 策略。我修改了代码以使其支持掩码,因为目前它仅支持目标检测的情况。
该模型在 v3-8 TPU 上以 64 的批量大小训练了 91.6k 步,耗时约 69 小时。非常感谢 TensorFlow Research Cloud 为我提供免费的 TPU 访问权限,这对我帮助很大!
预测
属性
对于属性预测,我使用了能够最大化每个类别中单个属性 F1 分数的阈值(即 294*46=13524 个阈值,但其中大多数实际上 >1,因为没有训练样本)。
最佳预测
我认为本次比赛使用的评估指标并不好。不幸的是,它完全没有考虑假阴性预测。这基本上意味着每张图像仅预测 1 个结果仍然可以达到 1.0 的分数(我最初在这个讨论中询问了关于假阴性的问题,后来我也发邮件联系了组织者确认这不是失误,但他们向我保证指标没问题)。
起初,我每张图像只使用了一个置信度最高的类别预测。但高类别置信度并不一定意味着分割或属性预测得好。因此,接下来我尝试计算每个预测的分数,即类别置信度、类别掩码 AP 和类别属性 F1 分数的平均值,然后利用它为每张图像选择 1 个最佳预测。这使我的 LB 分数提高了约 +0.041(Private),+0.036(Public)。
最后,我实现了比赛中使用的评估指标,计算每个模型预测的 AP(基于验证集),并训练了一个回归模型来预测 Mask R-CNN 预测结果的 AP。然后,像往常一样,我根据预测的 AP 每张图像只