第10名:即时合作
大家好!
首先,我要感谢组织者和参与者举办了如此有趣的比赛。
在这里,我将介绍我们模型的细节。该模型是三个预测结果的加权集成。前两个由我的队友介绍,第三个由我介绍。
我是 Len(Leheng) Li,我介绍网络部分,我的队友 Emil 介绍模型集成。
我们的主要工作基于 BBN(CVPR2020 oral,代码),其主要贡献是动态关注尾部数据。我们将 resnet50 替换为 resnest101 和 Efficient net b3。
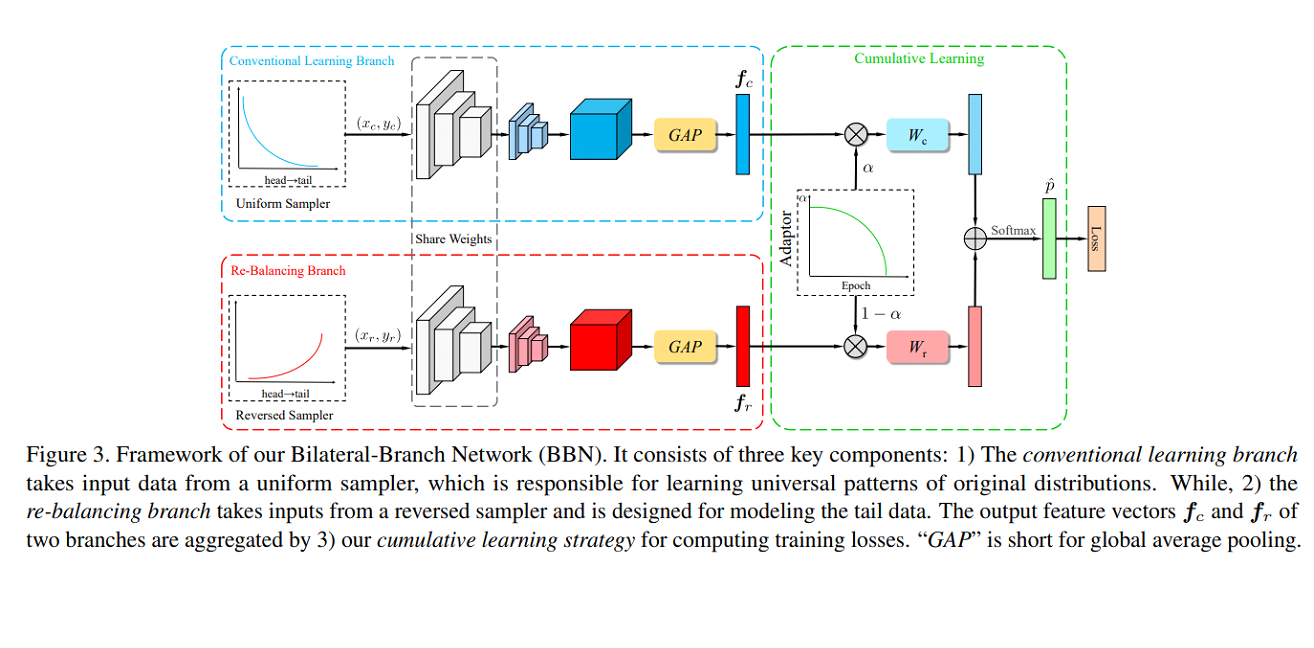
对于 resnest101,我们首先对 650*650 的图像进行中心裁剪,并调整为 256*256。得分达到了 0.61094。
对于 Efficient net b3,我们首先对 650*650 的图像进行中心裁剪,并调整为 300*300。得分达到了 0.60282。
我使用的是 4*2080ti 和 1*v100 16g,对于这次挑战来说这只是杯水车薪。我只训练了 20 个 epoch。如果训练更多次,我认为性能会更高。
最后,非常感谢我的队友 Emil,这是我第一次与外国人合作(中俄合作)。我非常享受与 Emil 的合作经历。也感谢组织者举办这次挑战。
以下是我的部分:
1. 模型描述
我试图尽可能从 se_resnext50_32x4d 特征生成器中挖掘潜力。主要的思想来源是这个“一袋免费技巧”视频。有 32k 个类别,它们分层排列在具有较少不同标签的超类中。在我的模型中,我在损失计算前以不同的权重追求所有类别。损失函数采用的是本文中的加权 FocalLoss。我详细分析了这对性能的提升程度,但显而易见的是,应该尝试对这种不平衡的数据进行加权。正如信息所说:
每个类别在训练和测试数据集中都至少有 1 个实例。请注意,测试集分布与训练集分布略有不同。训练集包含具有数百个示例的物种,但测试集中每个物种的示例数量上限为最多 10 个。
我收集了整个数据集的均值和方差统计数据来归一化输入图像,这带来了一点提升。我引入的下一个改进是衰减优化器学习率。它从 30e-5 开始,每 5 或 10 步除以二。我使用了 Adam 优化器。曾尝试在训练期间从 Adam 切换到 SGD 优化器,反之亦然。我称这种模式为 AdamEva 优化器。该尝试因 pytorch-lightning 框架的限制而失败,该框架允许你使用多个优化器,但每个优化器都有自己的训练调用。
最后,关于数据增强和 TTA(测试时增强)。随机裁剪、植物标本图像的随机翻转可以提高性能,但 Color Jitter(颜色抖动)不行,这是我的见解。对于 TTA,我采样了 4 个输入。我进行了 3 次训练增强,然后又进行了 1 次仅归一化和调整大小。之后,这四个样本的 logits 被平均以产生输出 logits。
2. 其他未奏效的尝试
- 度量学习:我还没弄清楚如何为具有如此多唯一标签的大型数据集进行度量学习。我已经设计了如何存储这些数据的方法,但还没设计出使用它的方法。
- 判别器网络:主要思想是训练一个网络来预测图像是来自训练集还是测试集。这可能有助于创建一个稳健的验证集作为训练集的一部分。好的验证集让你能够了解你的机器学习模型有多好。听起来很明显,但当你的数据集非常不平衡时,这并不容易找到。顺便说一句,我使用了训练集的一个随机子集作为验证集,这是不对的。在我看来,这是未来首先要解决的极端问题(验证集选择问题)!
3. 最终方案(最佳提交)
我用两种方法混合了我们的模型:概率平均和 logits 平均。前者效果不佳,而后者显示出的结果比我们两个网络单独的结果都要好。