第一名 - 使用 RAPIDS cuDF cuML 进行快速 GPU 实验
感谢 Kaggle 举办另一场有趣的 playground 比赛!我的 六月 playground "预测最佳肥料" 解决方案使用了过去 6 个月 playground 解决方案中的技术。以下是带有更多信息的旧解决方案链接。我将在下面再次简要描述这些技术。
往期 Playground 比赛使用 GPU 加速的技术!
| 日期 | 名称 | 指标 | 技术 | 解决方案链接 | 排名 |
|---|---|---|---|---|---|
| 2024 年 12 月 | 保险比赛 | RMSLE | RAPIDS cuDF 特征工程 |
链接 | 第 1 名 |
| 2025 年 1 月 | 预测比赛 | MAPE | Boosting 残差提升 | 链接 | 第 2 名 |
| 2025 年 2 月 | 背包比赛 | RMSE | 使用 原始数据 | 链接 | 第 1 名 |
| 2025 年 3 月 | 降雨比赛 | AUC | RAPIDS cuML | 链接 | 第 2 名 |
| 2025 年 4 月 | 播客比赛 | RMSE | cuML 堆叠 (Stacking) | 链接 | 第 1 名 |
| 2025 年 5 月 | 卡路里比赛 | RMSLE | GPU 爬山算法 (HillClimbing) | 链接 | 第 1 名 |
RAPIDS cuDF 特征工程
本次比赛的秘诀是 cuDF 特征工程,特别是 目标编码 (Target Encoding)。比赛数据有 8 个特征,每个都可以视为类别型特征。
首先我们制作所有两两组合,即 28 个新列。然后制作所有三三组合,即 56 个新列。接着制作所有四四组合,即 70 个新列。从这 162 = 8+28+56+70 个列中,我们使用 cuML 目标编码器 对 7 个二分类目标进行编码,y==0?, y==1?, ..., y==6?。这产生了 1134 个新列。然后我们使用原始数据集进行目标编码,又产生了 1134 个新列。最后我们使用所有这 2268 个列训练一个 XGBoost 模型!
使用原始数据
使用相关的外部数据有助于所有 Kaggle 比赛。这项技术在 Kaggle 的 playground 比赛中尤为重要,因为每场比赛都是基于原始数据集生成的合成数据。因此我们想要利用原始数据。
有两种方式使用外部数据(如原始数据集)。我们可以将数据作为 新行 添加。或者我们可以将数据作为 新列 添加。大多数公开 Notebook 使用了前者。但没有公开 Notebook 使用后者。(在我们最终的爬山算法集成中,我们需要前者训练的模型和后者训练的模型)。
要使用后者,我们首先创建一个类别型列(通过使用原始列或原始列的组合)。一旦有了类别型列,我们就使用原始数据对其进行目标编码。
TE = original_data.groupby(CAT_COL)[TARGET].agg("mean")
TE.name = f"TE_{CAT_COL}_orig"
train = train.merge(TE, on=CAT_COL, how='left')堆叠 (Stacking) (使用 cuML)
堆叠对于喜欢校准概率的 MAP@3 指标特别有益。我们训练一个 神经网络 (NN) 第二层 堆叠模型,使用分类交叉熵损失,无论第一阶段模型是否校准都没关系。
对于第一阶段模型,我们甚至不需要多分类。我们可以训练单个模型来预测单个二分类,目标是 y=0 吗?,目标是 y=1 吗? 等等。我们使用 XGBoost, CatBoost, NN, cuML 线性回归预测 OOF 概率。然后我们训练一个使用分类交叉熵损失的第二层 NN 堆叠模型来预测多分类概率。这利用了所有第一阶段模型的知识,并产生校准的多分类第二阶段预测!
我们还构建了一个 GBDT 第二层 堆叠模型,使用 XGBoost 和 objective='multi:softprob'。NN 第二层 和 GBDT 第二层 的平均值比每个第二阶段模型 individually 都要好!
重复 K 折交叉验证 (Repeated KFold)
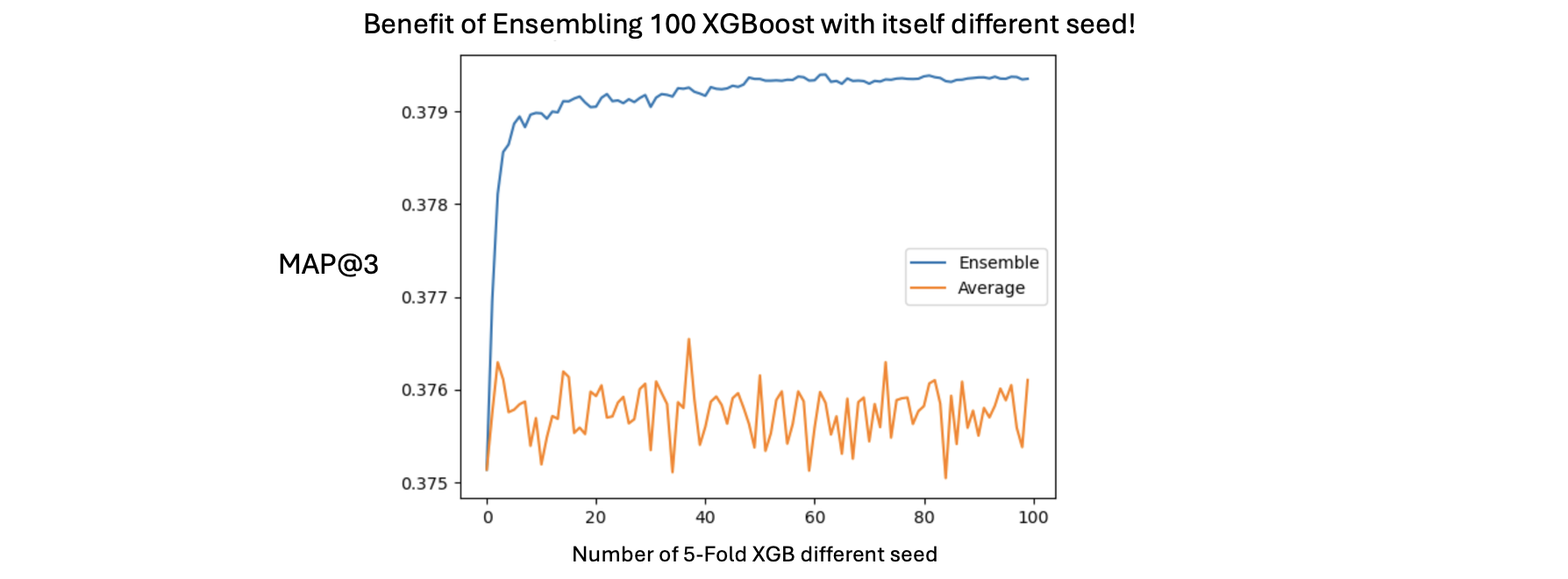
Bizen250 发布了一个漂亮的公开 Notebook 在此,说明了关于 MAP@3 指标的一个重要概念。该指标对训练的随机性(以及预测概率)非常敏感。因此,提高 MAP@3 指标的一个简单方法是用不同的种子再次训练相同的模型,并在为 MAP@3 选择前 3 名之前平均预测概率。
例如,我将所有 NN 训练 100 次,并在选择前 3 种肥料之前平均概率。我将所有 GBDT 使用 100% 数据训练数十次,并在选择前 3 名之前平均概率。
在下图中,我们看到每个 5 折 XGB 的每个折的平均 MAP@3=0.376,但当我们平均 100 个 5 折 XGB 的概率然后计算 MAP@3 时,我们达到了 0.380!
爬山算法 (Hill Climbing) (使用 cuML)
爬山算法的有效性来自于创建多样化的模型集合。然后当我们用加权平均组合它们时,结果比任何单个模型都要好。表格数据爬山算法的关键要素是构建多样化的 GBDT、NN 和 ML 模型。产生 ML 模型最快的方法是使用 RAPIDS cuML。
残差提升 (Boosting over Residuals)
注意我们可以给 XGBoost 提供初始预测。首先我们训练一个 cuML 线性回归模型。然后我们使用 XGBoost 的 dtrain.set_base_margin(LINEAR_REGRESSION_LOGITS) 从线性回归模型的预测开始提升。这是一个被忽视的 XGBoost 技巧!
伪标签 (Pseudo Labeling)
在所有比赛的最后几天,一个有用的技巧是添加用你最佳集成标记的测试数据。对于分类,NN 自然处理软目标概率(使用它们的默认交叉熵损失)。对于 XGB,我们编写一个自定义目标函数来用软目标训练多分类。
使用 100% 训练数据重新训练
在所有比赛的最后几天,另一个有用的技巧是使用 100% 训练数据重新训练最终集成中所有最重要的模型。对于 XGBoost,从 5 折到 100% 时,我们使用固定的迭代次数,等于早停期间平均固定次数的 125%。对于 NN,我们只是根据 5 折早停的平均减少 plateau 创建一个固定步长的学习计划。
相信你的交叉验证 (Trust Your CV)
对于我的最终提交,我选择了最好的 CV 集成,这也是我最好的 LB 分数。下面描述的我的 CV 集成具有 CV MAP@3 = 0.386!哇!
最终提交 - CV 0.386
我的最终提交是 9 个模型 的集成,每个模型都用不同的种子训练 多次。CV 分数为 0.386,私有排行榜 (Private LB) 为 0.38652,公共排行榜 (Public LB) 为 0.38450!
- XGBoost cuDF 特征工程 - 使用原始 数据作为列,树 深度 = 4。(并用 100% 数据训练 10 个模型)
- XGBoost cuDF 特征工程 - 使用原始 数据作为列,树 深度 = 10。(并用 100% 数据训练 10 个模型)
- 堆叠 NN 带有许多第一阶段模型(并训练 25 个模型)
- XGBoost 重复分层 K 折 (RepeatedStratifiedKFold) - 使用原始 数据作为行 - 来自 @bizen250 的公开 Notebook 在此(训练 50 个 XGB)
- 堆叠 XGB 基于 LGBM - 来自 @ayushchandramaurya 的公开 Notebook 在此(并训练多个版本不同种子)
- XGBoost - 使用原始 数据作为行,树 深度 = 18 - 来自 @elainedazzio 的公开 Notebook 在此(并训练多个版本不同种子)
- NN - 来自 @ricopue 的公开 Notebook 在此(并训练 100 个 NN)
- 堆叠 XGB 带有许多第一阶段模型和 伪标签列(即 KNN 特征)。
- NN 带有 伪标签行(并训练 25 个 NN)
所以我们使用 9 个模型 并将每个模型训练 多次 使用不同的种子。因此我们的最终集成大约结合了 300 组预测!权重(对于 9 个模型)由 GPU 爬山算法 确定!
享受比赛!
考虑在 Kaggle 的七月 playground 比赛中使用所有这些技术!