第二名方案
首先,感谢 Booz Allen Hamilton 和 Kaggle 团队举办了如此有趣的比赛。同时祝贺所有获胜的团队,以及所有在本次比赛中辛勤付出并学到很多的 Kagglers。
我们在 Public 榜排名第 38,在 Private 榜排名第 2。这个最终结果让我们非常激动,我们的队友之一 @tiginkgo 也因此成为了新的 Kaggle Master :)
结果
我们选择的最佳模型在 Public 榜达到了 0.563 分,在 Private 榜同样达到了 0.563 分。
特征工程
标题序列的 Word2Vec 特征
- 将目标评估之前的课程标题序列视为一个文档,使用 word2vec 进行处理,并计算所得向量的统计值(均值/标准差/最大值/最小值)。
历史特征
- 按(全部、树顶、岩浆、水晶)分组,统计(会话、世界、类型、标题、event_id、event_code)作为历史数据。
- (event_round、game_time、event_count)的计数、均值、最大值。
衰减历史特征
- 针对(标题、类型、世界、event_id、event_code)进行衰减处理的历史数据。
- 每个会话的累积量减半。
历史特征的密度
- 针对(标题、类型、世界、event_id、event_code)的历史数据密度。
- 密度 = (计数) / (从首次激活日起经过的天数)。
滞后评估
- 关于 num_correct、num_incorrect、accuracy、accuracy_group 的大量统计值(均值/标准差/...)。
- 与过去评估相差的小时数。
- 包括完整的评估数据和按标题划分的评估数据。
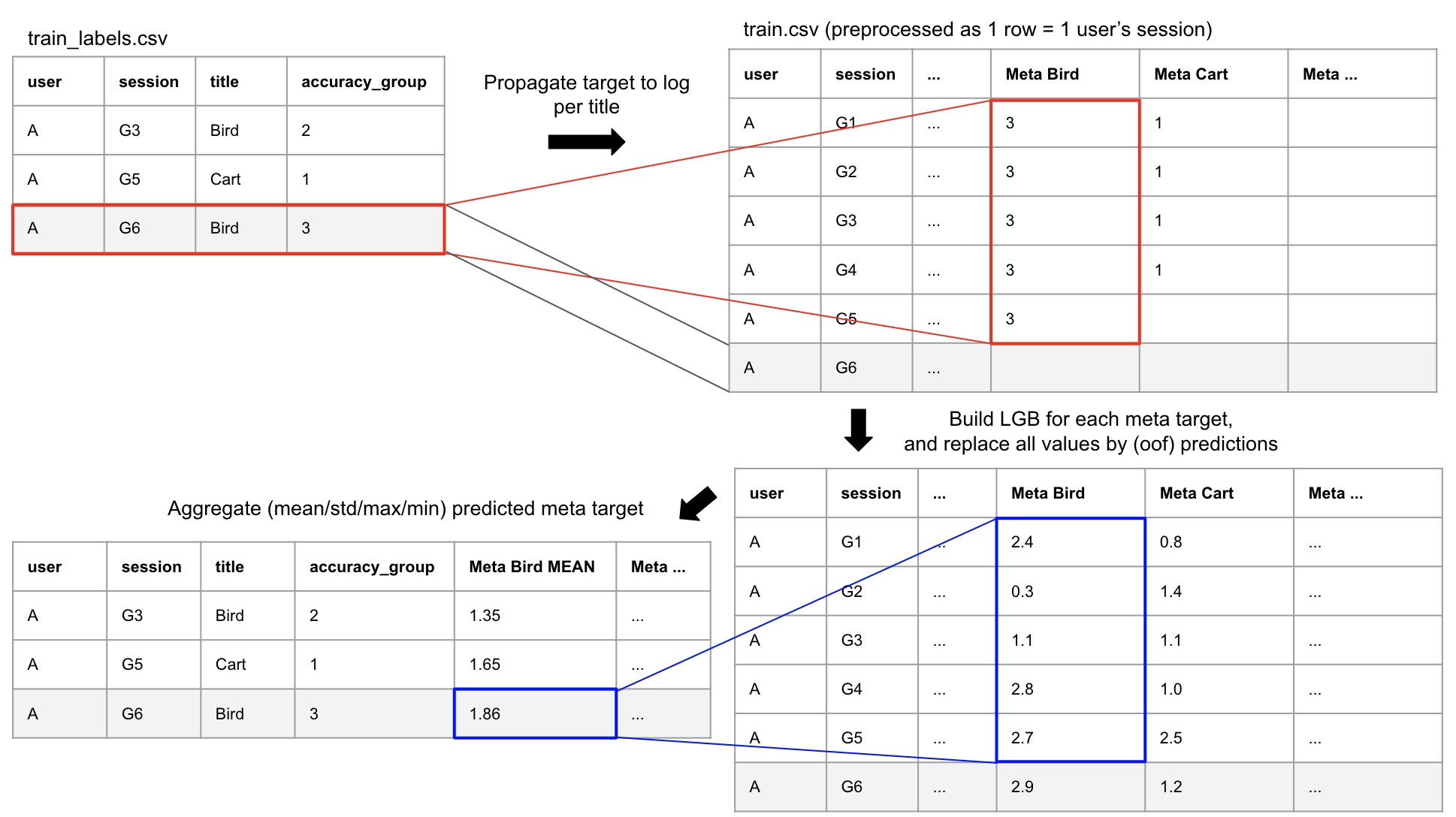
元特征
- 为了表示“提前进行 game_session 如何导致评估结果”,我们为每个评估标题创建了“元目标特征”。我们对训练数据使用 oof(out-of-fold),对其他数据(如没有测试或元目标的记录)使用 KFold 平均值。
特征选择
- 删除重复列。
- 删除高相关列(相关系数超过 0.99)。
- 最后,选取通过零重要性评分最高的前 300 个特征。
建模
- 对于验证集,我们进行了重采样,以确保每个用户只有一个样本。
- 使用 StratifiedGroupKFold,5 折交叉验证。
- 对 LGB、CB 和 NN 进行 RSA(5 个随机种子)集成。
后处理
- 集成权重 = 0.5 * LGB + 0.2 * CB + 0.3 * NN。
- 设定阈值以优化交叉验证的二次加权 Kappa 系数。
特别感谢
Elo Merchant Category Recommendation 比赛的第 7 名方案给了我们很大的启发,特别是我们的 word2vec 和元特征,这是我们解决方案中非常重要的部分。
我们非常感谢 @senkin13,他的精彩解释请见: